
목차
1. Slab Allocator란?
user space에서 malloc, free 같은 동적 메모리 할당 및 해제와 관련된 로직을 공부한적이 있다.

이와 동일하게 kernel space에서도 메모리를 효율적으로 관리하기 위한 allocator가 존재하는데 그 놈이 바로 Slab Allocator이다. 여태 NUMA, Memory Zone, Buddy System 등과 관련된 이론 공부를 진행했는데 결국 슬랩 할당자를 공부하기 위한 선수 지식이였으며 해당 내용들을 어느정도 파악하고 있어야 슬랩 구조에 대한 이해가 쉽게 다가올 것이다.
커널 메모리 관리 기법은 크게 slab, slub, slob 으로 나뉘는데, 해당 기법들의 차이점을 간단하게 알아볼 것이고 앞으로의 설명은 slub을 기준으로 할 것이다.
Slab Allocator
•
2007 ~ 2008년 까지 default로 사용되었다
•
관리에 매우 복잡한 처리가 필요해서 효율이 떨어지는 기법이다
•
user-space에서 청크를 fastbin, unsorted bin 등과 같이 구분하는 것처럼 full list, partial list, empty list 로 나뉘어 관리된다. 관리되는 주체는 slab 객체라 부른다
•
slab 객체에는 내부에 메타데이터 정보가 포함되어있는데 이 메타 데이터를 관리하는 오버해드 문제가 발생한다
•
결국 Slab의 단점 때문에 더이상 쓰지 않고 Slub이 현재 default로 쓰인다
Slub Allocator
•
현재 default로 사용되는 할당자
•
slub 객체는 partial list만을 사용하여 관리함
•
slab에 비해 메모리 지역성이 향상되었으며 메모리 단편화가 줄어듬
•
slab에 비해 관리가 단순하다
•
즉 기존 slab객체에 들어있는 메타데이터 정보를 최적화한 구조가 바로 slub이다
Slob Allocator
•
주로 적은 용량을 가지는 임베디드 리눅스 환경에서 선택하여 사용하는 할당자이다
•
속도는 느리지만 메모리 소모가 매우 적다는 장점이 있다
자 이제 앞으로 설명하는 '슬랩 할당자'라는 단어는 Slub Allocator 라고 생각하고 진행하겠다.
2. Slab Allocator 전체 흐름
이해하기 쉽게 저번 Buddy 시스템에서의 메모리 할당 예시를 다시한번 생각해보자. Buddy 시스템이 무엇인지 모른다면 아래 글을 읽어보고 오자

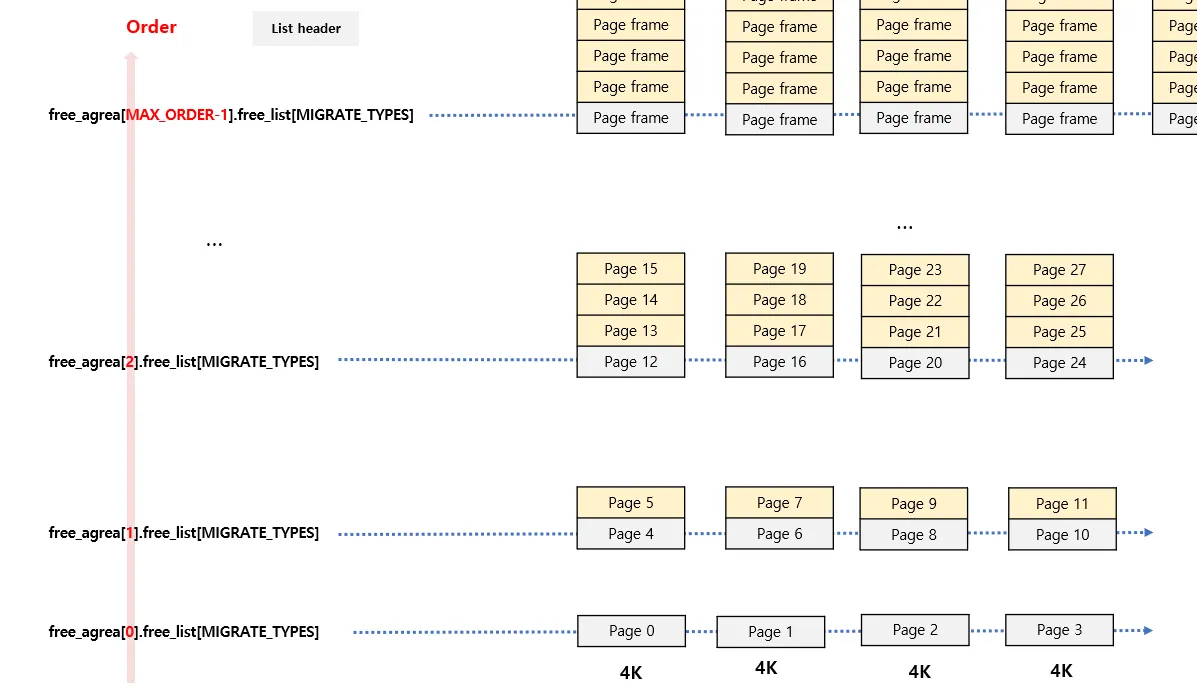
커널이 부팅되고 버디 시스템에 의해 Order-N 단위로 블럭들이 free_list에 연결되어 있다. page 단위는 4K 사이즈라고 가정했을 때 만약 여기서 3000byte 사이즈 메모리를 할당 요청이 들어게되면 어떻게 될까?
공부했던 내용을 바탕으로 하면 Order-0의 들어있는 free_list를 뒤지고, 여기에 현재 존재하는 블럭을 할당해줄것이다. 헌데 만약 128byte의 요청이 들어오면 어떻까?
위 그림으로 보아 Order-0 free_list에 존재하는 블럭을 할당해줄것이다. 아무리 가장 작은 Order-0인 page 여도 128byte를 위해 4k 사이즈를 할당해주는건 너무 비효율 적이고 이는 내부 단펴화로 이어진다.
슬랩 할당자가 나오게된 큰 이유가 바로 이것이다. 버디시스템은 4K 이상의 사이즈가 큰 메모리의 할당요청시에 효율적으로 할당을 관리하여 외부 단편화를 줄였다. 반대로 슬랩 할당자는 내부 단편화를 줄이기이 위해 사용된다고 말 할 수 있다.
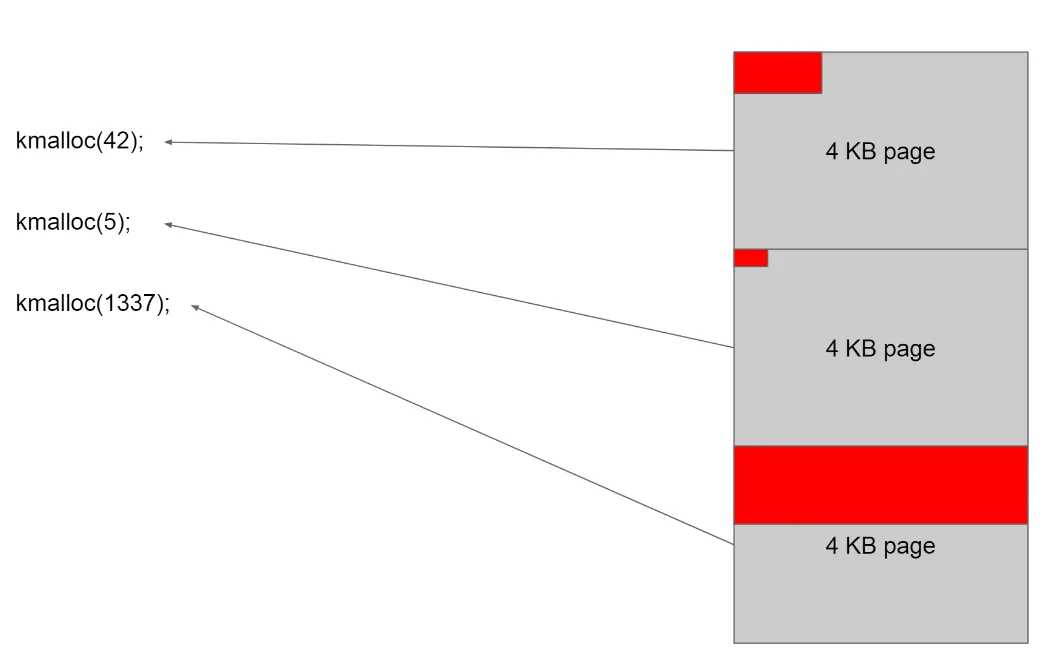
위 그림은 슬랩 할당자의 필요성을 간편하게 보여준다. 슬랩 할당자가 없다면 모든 메모리들은 페이지 단위로 관리되기 때문에 42byte의 메모리 요청시, 4K 페이지 하나를 할당해주고 그 안에서 42만큼 할당 해 줄 것이다. 5byte, 1337byte도 동일하다. 내부 단편화가 발생한다
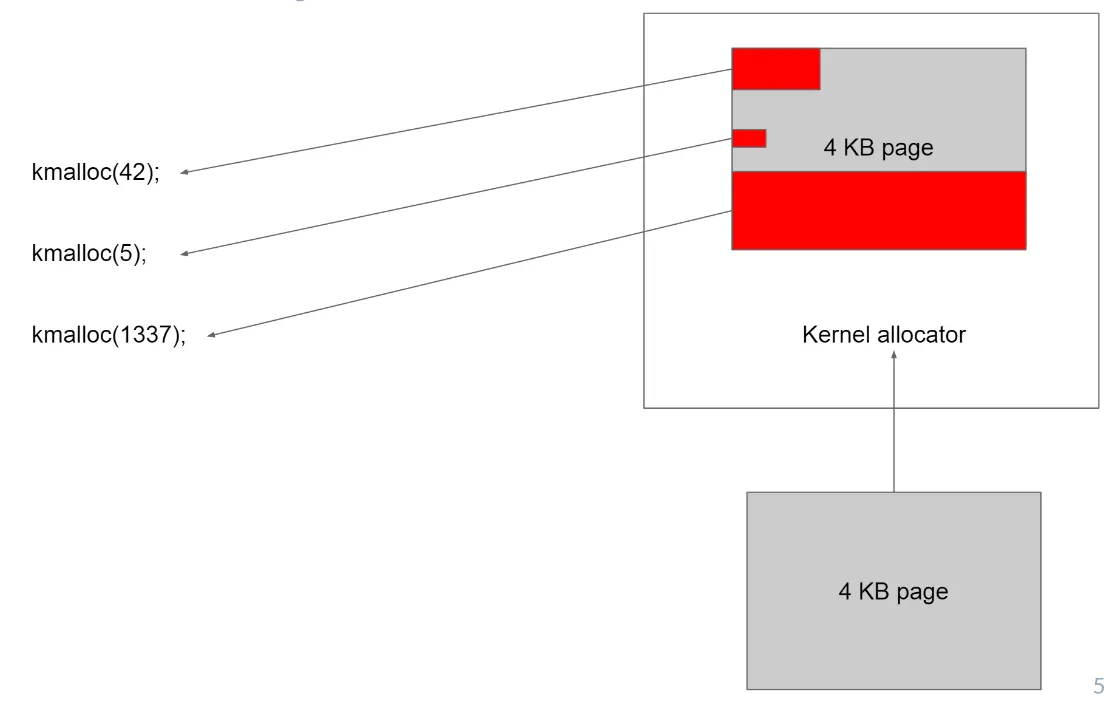
하지만 슬랩 할당자를 사용하게 된다면 4K 내부를 좀더 세부적으로 관리할 수 있게 된다. 42byte, 5byte, 1337byte 모두 하나의 4K page 하나로 할당 할 수 있게되고 이를 통해 내부 단편화가 줄어든다. (4K Page 하나의 내부에서 좀더 세부적으로 object라는 단위로 관리되는 로직이다.)
허나 오해하면 안되는게, 버디 시스템이랑 슬랩이랑 동떨어진거라고 생각하면 안된다. 버디 시스템 안에 슬랩 할당자가 포함된다. 요말이 뭔말인지는 차차 알아가자 ㅋ
3. Slab Allocator 구조
다시한번 말하지만 슬랩 할당자 같은 놈들도 효율적으로 메모리를 관리하기 위해서 나온 개념이다. 메모리를 할당 해주기 위해서 거치는 로직이 A→B→C→D→E→... 등과 같이 복잡하다면 당연히 할당받는 속도는 느릴 것이다.
원론적인 얘기지만 어떻게 빨리 메모리를 할당해줄까? 라는 생각을 해야한다. 이를 해결하려면 커널 내부에서 실제 어떠한 로직으로 메모리를 할당해주는지 알아야한다.
확인했다고 치고! 대략 80% 이상의 할당은 특정 패턴으로 메모리를 할당 및 해제하게 된다. 이를 통해 다음과 같은 아이디어를 낼 수 있다
•
자주 쓰는 메모리 패턴을 미리 정의해 놓고 미리 할당해 놓자
•
미리 정의한 패턴에 대한 할당 요청이 들어오면 미리 할당해 놓은 놈을 주자
•
특정 패턴으로 메모리 해제 요청을 함면 바로 시스템에 반환해주는게 아닌 일단 대기하자. 비슷한 요청이 또 올 수 있다
저 아이디어가 바로 슬랩 할당자이다. 슬랩 할당자를 이루는 주요 용어는 다음과 같다
•
슬랩 캐시
커널에서 자주 사용하는 구조체에 대한 동적 메모리를 미리 확보하고 관리하는 주체
•
슬랩 페이지
버디시스템에서 관리되는 ordern-N 단위의 페이지를 뜻함
•
슬랩 오브젝트
슬랩 캐시가 할당해 놓은 메모리이다. user-space의 malloc - chunk 단위로 생각하면 편한다. chunk 사이즈처럼 object 크기도 가변이다.
위 용어들을 전의 아이디에 대응시켜보면 다음과 같다
•
자주 쓰는 메모리 패턴을 미리 정의해 놓고 미리 할당해 놓자
⇒ 슬랩 캐시
•
미리 정의한 패턴에 대한 할당 요청이 들어오면 미리 할당해 놓은 놈을 주자
⇒ 슬랩 오브젝트
•
특정 패턴으로 메모리 해제 요청을 함면 바로 시스템에 반환해주는게 아닌 일단 대기하자. 비슷한 요청이 또 올 수 있다
⇒ 슬랩 오브젝트를 할당 및 해제
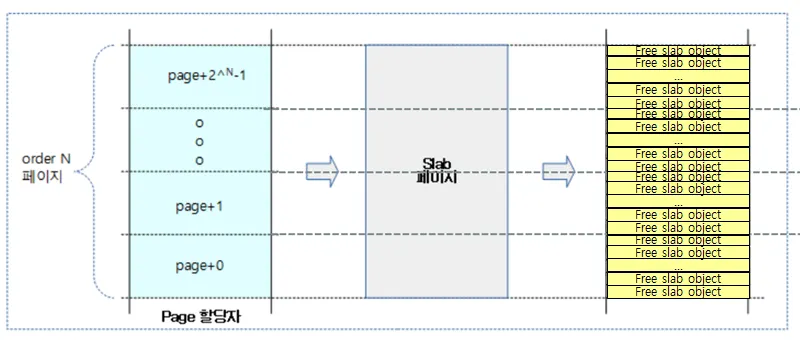
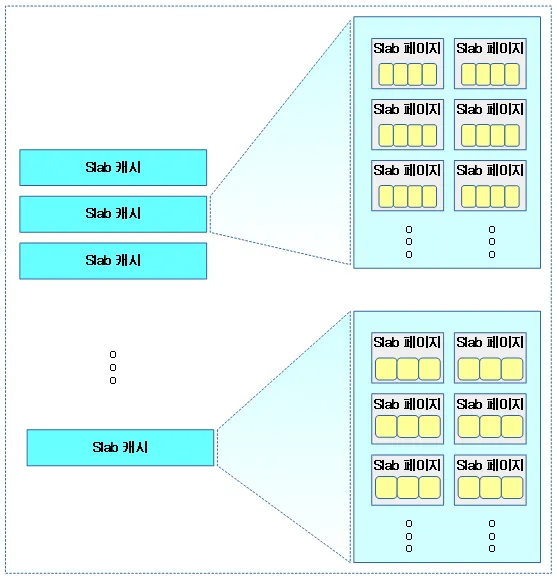
버디 시스템에선 Order-N 단위로 페이지를 관리한다고 했다. 위 그림은 Order-N 페이지를 사용하여 슬랩 페이지를 구성하고, 슬랩 페이지에서 할당 가능한 슬랩 오브젝트를 배치한 모습이다. 하나의 페이지가 내부적으로 슬랩 오브젝트들과 헤더(슬랩 메타데이터)로 구성된다는 걸 볼 수 있다.
슬랩 캐시는 바로 이러한 1개 이상의 슬랩 페이지가 모여서 구성된다.
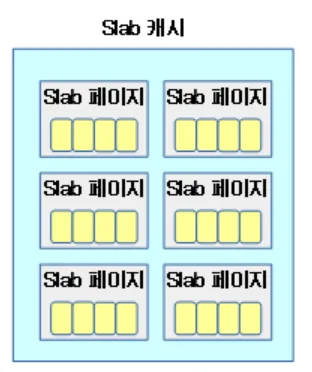
슬랩 캐시내의 모든 object들의 사이즈는 동일하다. 만약 필요한 object 크기가 다른 경우 각각의 object 사이즈 별로 슬랩 캐시를 만들어 구성할 수 있다.
*하나의 슬랩 페이지에서 구성되는 슬랩 오브젝트 크기는 동일하지만 서로 다른 슬랩 페이지는 슬랩 오브젝트 크기가 다를수 있다
위에서 슬랩 캐시의 아이디어는 '자주 쓰는 메모리 패턴을 미리 정의해 놓고 미리 할당 해 놓자' 이였다. 슬랩 캐시에 대한 이해를 돕기 위해 다음과 같은 예를 들어보자.
보통 프로세스가 생성 할 때마다 그에 해당하는 pcb 정보도 생성된다. 이는 실제 struct task_struct 구조체 형태로 구현되어있고, 해당 구조체가 생성된다는 의미이다.

위 구조체가 바로 task_struct 이다. 커널은 프로세스를 생성할 때 struct task_struct 구조체 크기만큼 메모리를 할당하고 종료시 해제되는 루틴을 거친다. 만약 수천개의 프로세스가 생성된다면 분명 부하가 발생할 것이다.
하지만 위에서 설명한 슬랩 캐시를 적용시키면 부하를 줄일수 있다. struct task_struct 구조체 크기만큼 동적으로 메모리를 미리 할당해두고 프로세스가 생성될 때 제공해주는 방식으로 말이다.
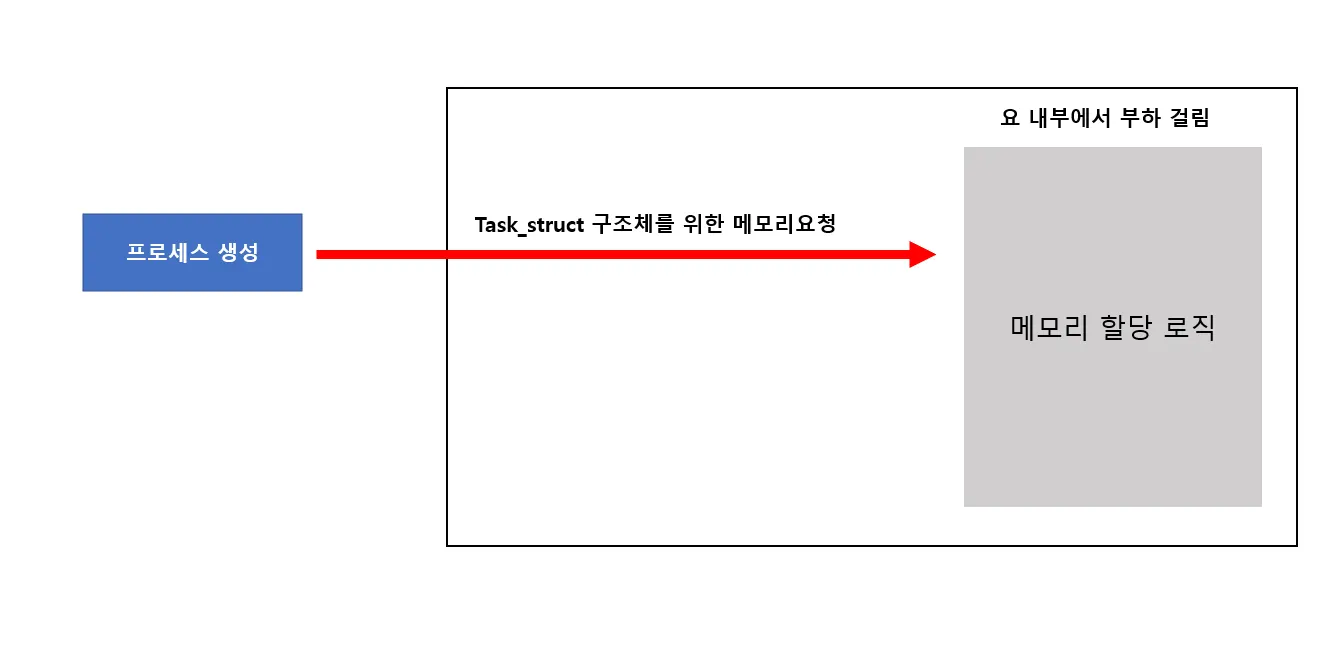
다음과 같은 방식으로 진행된다면 많은 부하가 걸리지만
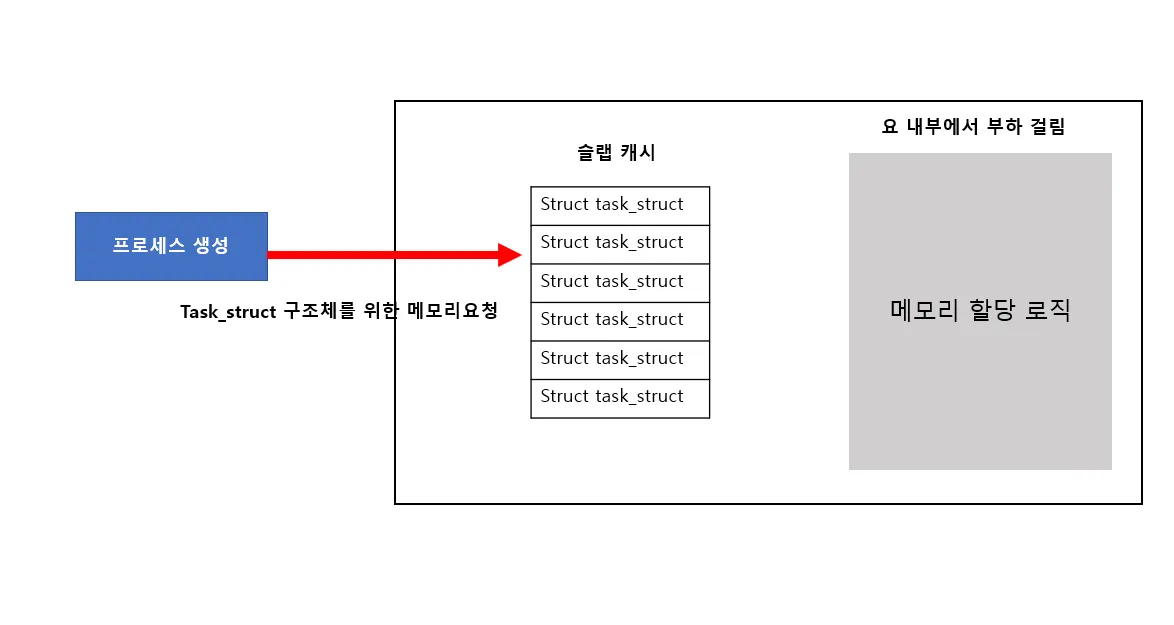
요렇게 캐시 역할을 수행함으로써 성능을 높일 수 있다는게 포인트이다.
즉, 자주 사용되는 놈들을 위한 메모리를 슬랩 캐시에 미리 할당해놓는 것이다.
실제 task_struct 구조체 사이즈는 슬랩 캐시에 미리 할당되어 있으며 요놈 뿐만 아니라 파일을 생성할 때 사용되는 struct inode 구조체, 가상 메모리 공간을 관리하는 struct mm_struct 구조체 등도 자주 사용되기 때문에 이러한 구조체들을 위한 메모리도 슬랩 캐시에 존재한다.
그럼 실제 커널에서 어떠한 슬랩 캐시가 존재하는지 cat /proc/slabinfo 명령어로 확인해보자
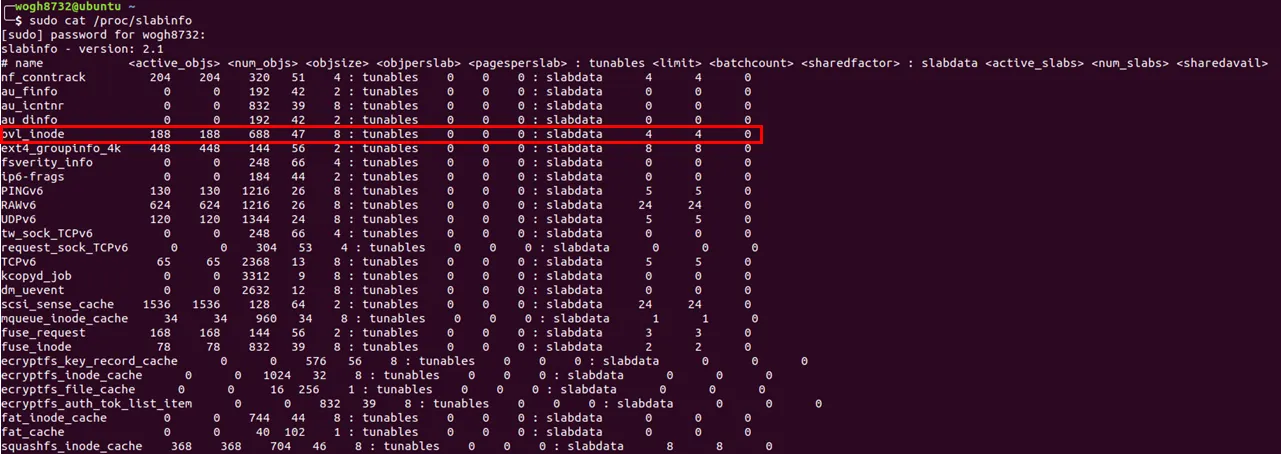
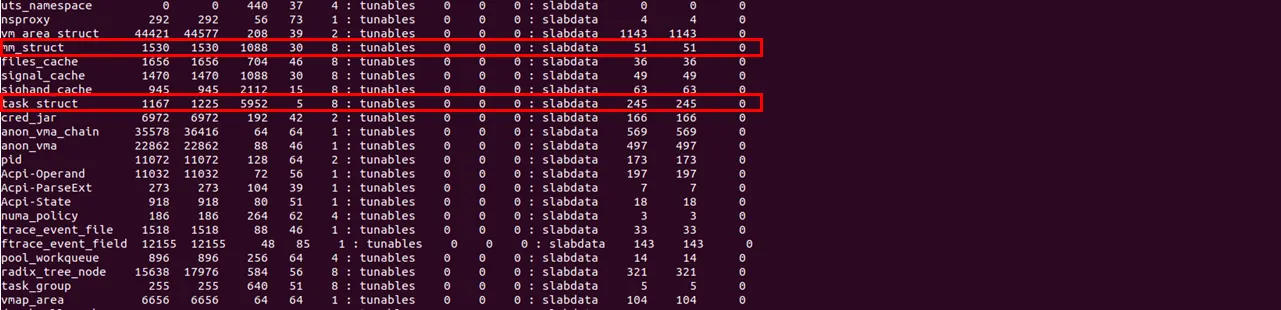

앞서 설명한 3개의 구조체들도 슬랩 캐시로 존재한다는 것을 알 수 있다. 요 3개 뿐만 아니라 굉장히 많은 슬랩 캐시를 확인 할 수 있다. 다시말하지만 위에 놈들은 자주 쓰이는 놈들이고, 그로인해 슬랩 캐시형태로 미리 각 사이즈에 맞게 메모리를 할당 해 놓은 것이다.

추가적으로 kmalloc-8 ~ kmalloc-8k 슬랩 캐시를 볼 수 있다. 커널 드라이버 공부 할 때 kmalloc을 많이 사용했는데, 저렇게 자주 요청되는 kmalloc 사이즈들도 따로 슬랩 캐시로 구성해놓았다!!
라인별 의미는 다음과 같다
•
name
슬랩 캐시 이름
•
<active_objs>
사용중인 object 수(per-cpu에 있는 free object 조차 사용 중인 object 수에 포함됨)
•
<num_objs>
할당된 슬랩 페이지의 모든 object 수(free+inuse)
•
<objsize>
슬랩 object 사이즈(메타데이터 포함)
•
<objperslab>
각 슬랩 페이지에 들어가는 object 수
•
<pagesperslab>
각 슬랩 페이지에 들어가는 페이지 수
•
<limit>
캐싱될 최대 object 수 - slub에서 미사용 중(항상 0)
•
<active_slabs>
사용 중인 슬랩 수 = 전체 슬랩 수와 동일
•
<num_slabs>
전체 슬랩 수 = 사용 중인 슬랩 수 와 동일
자 그렇다면 이제 슬랩 캐시는 실제 어떻게 구성되어있을까?. 이 역시 구조체 형태로 관리하며 바로 struct kmem_cache 로 모든 슬랩 캐시를 표현한다.
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
struct work_struct kobj_remove_work;
#endif
#ifdef CONFIG_MEMCG
struct memcg_cache_params memcg_params;
int max_attr_size; /* for propagation, maximum size of a stored attr */
#ifdef CONFIG_SYSFS
struct kset *memcg_kset;
#endif
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
C
복사
따라서 슬랩 캐시라고 말하면 위 구조체를 생각하면 된다.
그럼 이제 슬랩 오브젝트에 대해서 다시한번 살펴보자. 아까 슬랩 오브젝트는 슬랩 캐시가 할당해 놓은 메모리라고 했다.
•
struct task_struct
•
struct inode
•
struct mm_struct
예를 들어 위와 같은 구조체에 대한 메모리 공간을 미리 슬랩 캐시로 확보해 놓은 상태에서 프로세스 생성을 위해 task_struct 구조체로 메모리 할당을 요청 할 때가 있을것이다.
결국 task_struct 슬랩 캐시에서 할당해 놓은 메모리 시작 주소를 알려주게된다. 요놈이 바로 슬랩 오브젝트의 시작주소를 반환한다는 의미이다. 우리가 일반적으로 커널 드라이버 코드에서 볼 수 있는 kmalloc()으로 반환받는 주소가 바로 슬랩 오브젝트의 시작주소이다.(물론 가상주소로 변환된)
4. Slab Cache 구조
이제 kmem_cache 구조체에서 중요한 멤버변수를 살펴보자. 슬랩 캐시는 실제 kmem_cache 구조체 형태로 관리된다고 했는데 그 안에서 크게 2가지 형태로 또 구분이 된다. 위 두개 역시 슬랩 캐시 형태이다.
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
...
...
struct kmem_cache_node *node[MAX_NUMNODES];
}
Python
복사
•
struct kmem_cache_cpu __percpu *cpu_slab
빠른 할당을 위해 CPU 별로 슬랩캐시를 관리하는 구조체로 이 역시 슬랩 캐시이다. 만약 cpu가 4개라면 per-cpu 는 4개이다.
•
struct kmem_cache_node *node[MAX_NUMNODES]
NUMA 구조에서 각 노드별 메모리 접근 속도가 다르므로 슬랩 페이지들을 노드별로 관리하기 위한 구조체이다.
위 두개의 구조체가 어떻게 관리를 연관성있게 하는지는 차차 이해해보자. 우선 위 두개의 구조체를 그림으로 표현하면 다음과 같다.
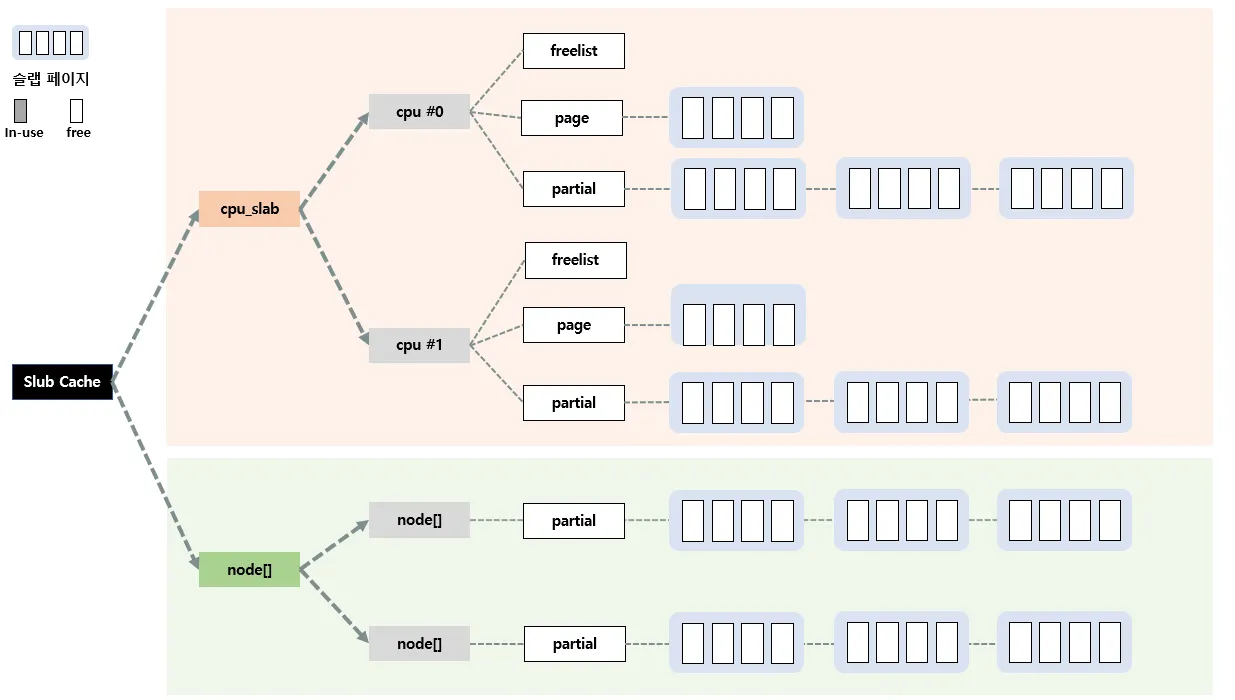
실제 슬랩 캐시(kmem_cache 구조체)는 각 노드별, 각 cpu 별로 관리한다. 처음에 헷갈렸던게 어짜피 노드 자체도 cpu+로컬메모리 형태로 관리하는건데 굳이 또 cpu별로 관리를 해야하나? 싶었다.
질문의 답은 위 두개의 구조는 따로 관리되는게 아니라 서로 상호작용을 하면서 전체를 관리하다고 이해하면된다. per-cpu 슬랩 캐시의 관리형태를 살펴보자.
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
C
복사
kmem_cache_cpu 구조체는 크게 freelist, page, partial 필드가 존재한다. percpu로 관리되는 필드를 다음과 같은 용어로 계속 진행하겠다.
•
c→freelist
•
c→page
•
c→partial
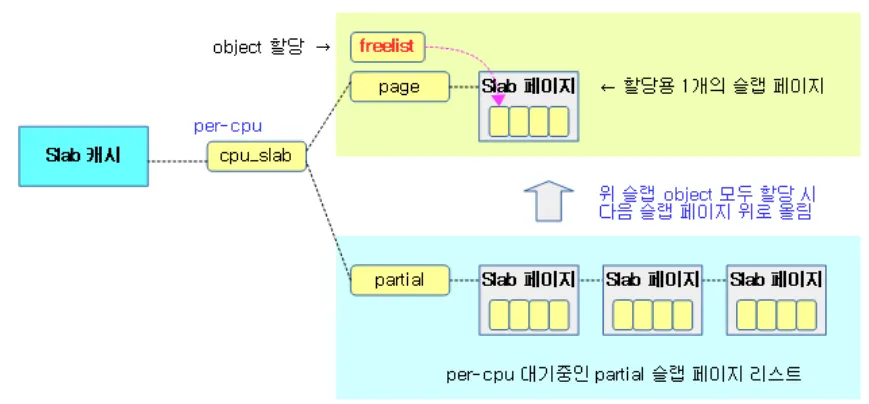
struct page *partial 에는 슬랩 페이지들이 리스트로 연결되어 있으며 각 슬랩 페이지들에는 free or inuse 인 오브젝트들이 들어있다. c→partial 에 들어있는 슬랩 페이지들은 바로 이용되지 못하고 c→page 로 이동되야지만 사용가능하다.
결국 c→page 는 오로지 하나의 슬랩페이지만 관리하고, 슬랩페이지에 들어있는 여러 오브젝트들 중 free되어있는 오브젝트들이 할당될수 있는것이다. 그리고 이렇게 free object들은 c→freelist 를 통해서 접근할 수 있다.
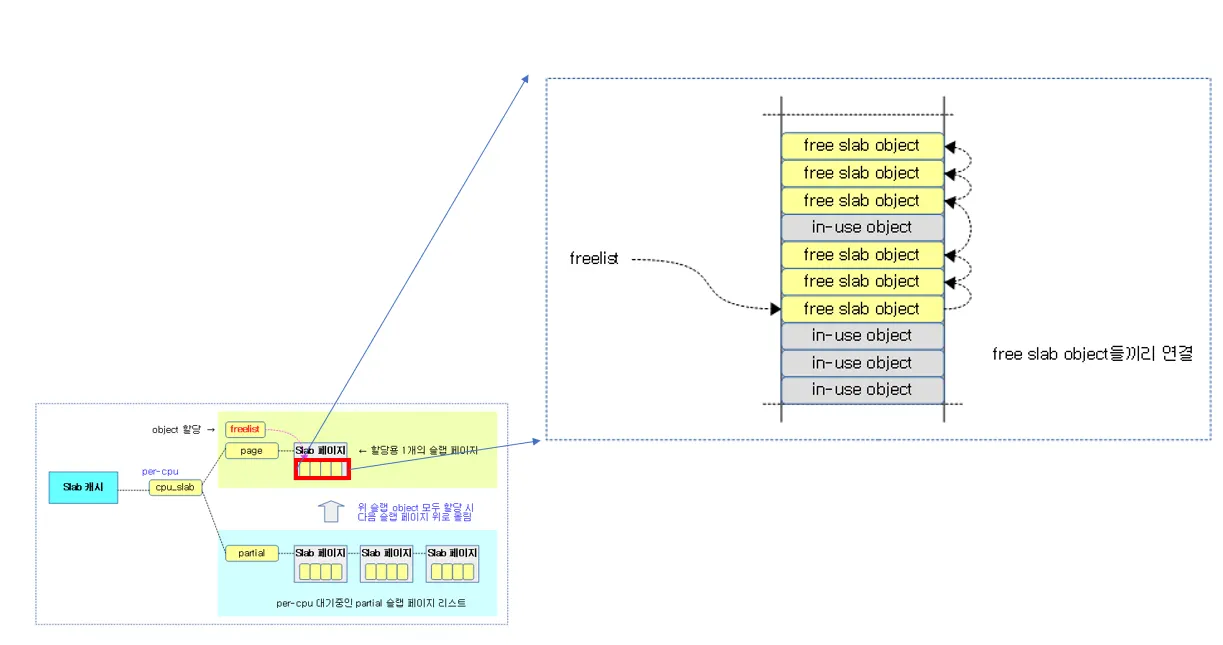
실제 c→page 들에 있는 오브젝트들은 c→freelist 에서 위 처럼 free 오브젝트들끼리 연결되어있다.
여기서 하나 알아두고 가야할것이 있다. freelist는 실제 c→freelist와 c→page→freelist 두개로 관리된다. page 구조체를 잠깐보면
struct page
{
...
struct
{ /* slab, slob and slub */
union
{
struct list_head slab_list;
struct
{ /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union
{
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct
{ /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1; // 뒤에서 설명함
};
};
};
...
C
복사
freelist가 또 존재한다. 따라서 실제 free object는 c→freelist와 c→page→freelist 두개로 관리되어 다음과 같이 동작한다
•
c → freelist
현재의 CPU가 직접 freelist를 관리하므로 오브젝트의 할당 및 해제가 가능하다
•
c → page → freelist
현재 CPU가 예를 들어 1번 CPU라고 했을 때, 1번 CPU를 제외한 다른 2번, 3번.. 등의 다른 CPU가 1번 CPU가 관리하고 있는 오브젝트를 해제했을때 이곳으로 해제된다. 자기 자신의 CPU가 아니면 오브젝트는 여기에 해제만 가능하고 할당은 불가능하다
아래의 그림은 2가지의 freelist가 관리되는 로직을 잘 표현한다.
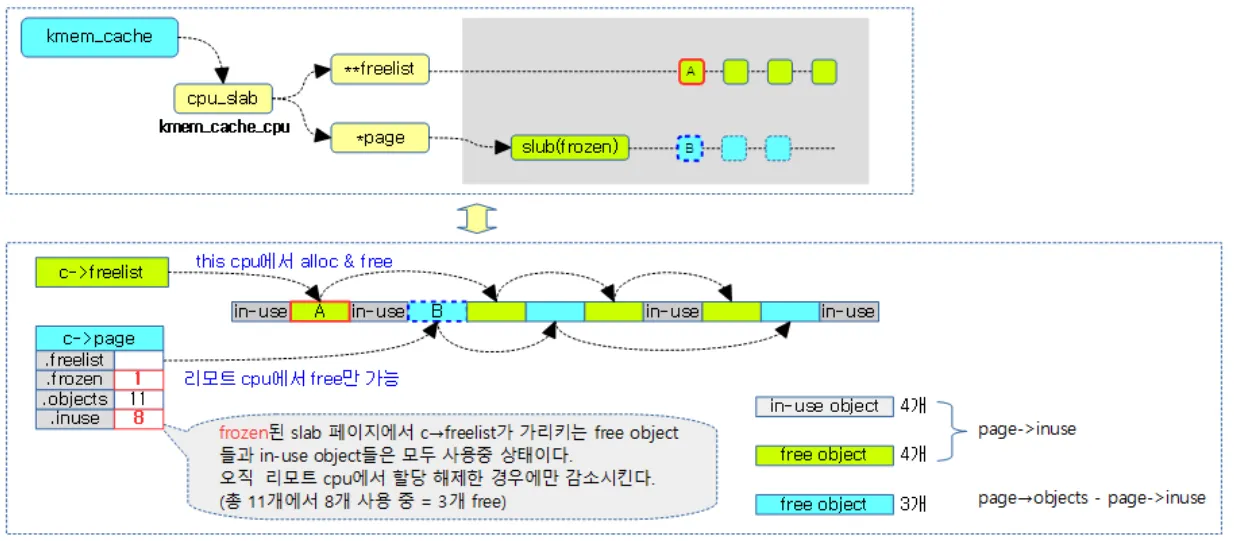
현재 c→freelist에는 총 4개의 free되어있는 오브젝트가 연결되어 있고, c→page→freelist에는 4개의 free 오브젝트가 연결되어있다. c→page에 현재 표시되어있는 freelist, frozen, objects, inuse는 다 위의 page 구조체에 들어있는 필드이다.
frozen 상태란 슬랩 페이지가 특정 cpu가 전용으로 사용할 수 있는 상태를 뜻한다.
c->page에 연결된 슬랩 페이지이거나, c->partial에 연결된 슬랩 페이지들이 frozen 상태에 이며 node→partial 에 연결된 슬랩 페이지는 unfrozen 상태이다.
추가적으로 전담 CPU만이 슬랩 오브젝트의 할당, 해제가 가능하며 전담 CPU가 아닌, 다른 CPU는 슬랩 오브젝트의 해제만이 가능하다.
다시 위 그림을 보면 page 구조체의 in-use필드에 들어가는 값은 실제 사용되고 있는 오브젝트 4개 뿐만 아니라 c→freelist에 들어있는 오브젝트 4개도 포함하여 계산된다. (왜 그런지는 모르지만 일단 그렇단다).
따라서 .inuse는 8개의 오브젝트로 표시된다. inuse 필드는 전담 CPU가 아닌 다른 CPU가 오브젝트를 free했을 경우에만 감소된다. 이해하기 쉽게 아래 그림을 봐보자.
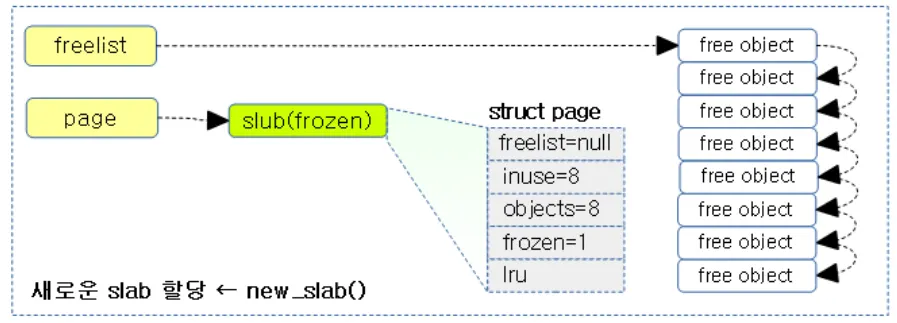
현재 c→freelist에는 전부 free상태여서 fastpath로 할당이 가능하다. c→freelist에 8개의 오브젝트가 들어있으므로 inuse는 8이다. c→page→freelist는 널이다.
(Fastpath에 대해선 뒤에서 설명함)
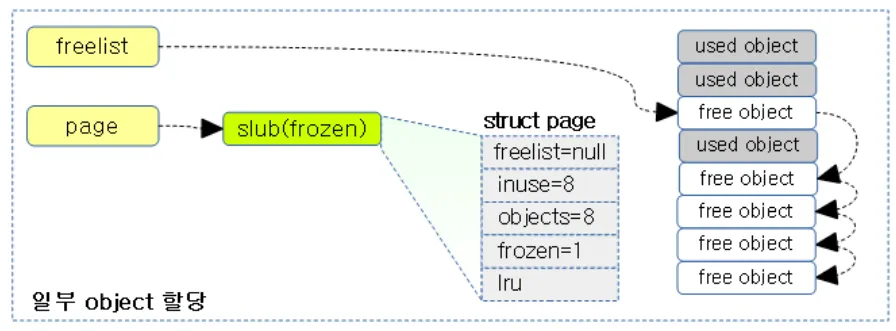
이 상태에서 Fastpath로 c→freelist에 있는 몇개의 오브젝트를 할당해 주었다. 그럼에도 불구하고 inuse값을 보면 전담 CPU에서 할당 및 해제가 일어났으므로 값의 변화가 없다.
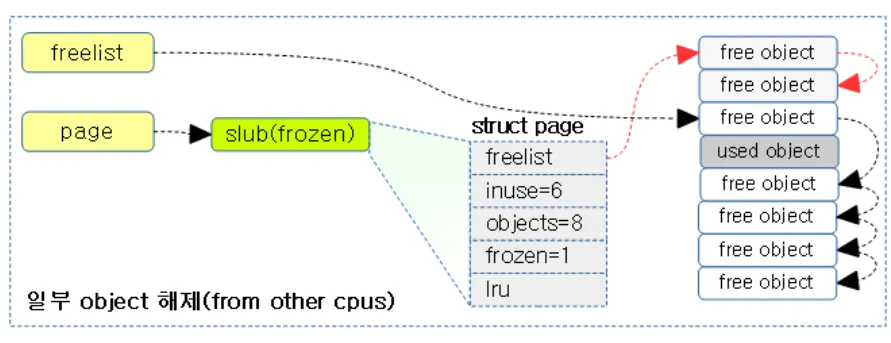
이때 전담 CPU가 아닌 다른 CPU가 2개의 오브젝트를 해제시켰다. 따라서 c→page→freelist에 두개의 오브젝트가 연결되고, inuse값이 2개 감소된다.
그럼 per-node 는 언제, 어떻게 관리될까?
요놈은 object가 할당 및 해제되는 로직을 파악하면 이해할 수 있다.
5. Slub object 할당
슬랩 할당자, 정확히는 slub 할당자에 대해서 전체적인 프로세스를 살펴봤으며 실제 내부적으로 어떠한 형태의 구조체로 구성되었는지, 슬랩 캐시는 무엇이고 어떻게 관리하는지를 살펴보았다.
커널 드라이브 코드를 짤때 kmalloc(80) 요렇게 동적 메모리를 요청을 하면 실제 반환되는 주소는 free되어있는 object라고 하였다. 그럼 이제 어떠한 로직으로 object가 할당되는지 간략히 살펴보자.
슬랩 object가 할당되는 방식은 총 5개로 Fastpath, Slowpath-1, Slowpath-2, Slowpath-3, Slowpath-4 가 있다.
•
c : per-cpu
•
n : per-node
Fastpath
Fastpath는 가장 빠른 할당방식으로, 현재 c→freelist에 할당 가능한 object가 있으면 바로 할당해주는 방식을 뜻한다.
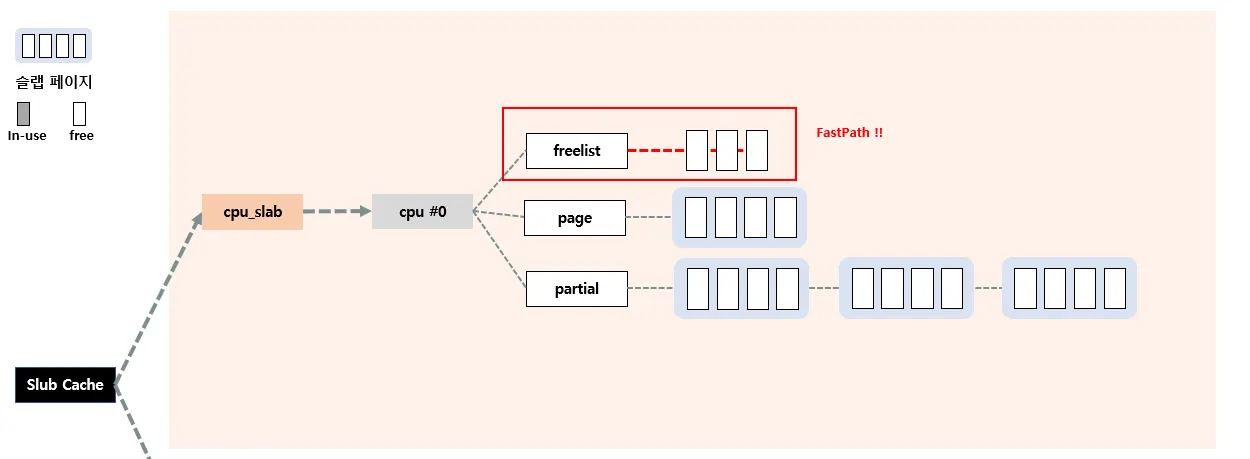
우선 헷갈리면 안되는게, c→freelist에는 슬랩 페이지가 연결된것이 아니라 그냥 슬랩 오브젝트가 연결된다. c→freelist에 현재 세개의 오브젝트가 연결되어있다. 따라서 c→freelist에 들어있는 놈을 바로 할당해주는 방식이 바로 Fastpath이다.
Slowpath - 1
현재 c→freelist 에 사용할 수 있는 object가 없을 경우 Slowpath 방식이 실행된다. 그 중 첫번째로 slowpath-1이 시행되는데, 바로 c→page→freelist에 들어있는 오브젝트들을 c→freelist로 올린다음 다시 Fastpath를 시도한다.
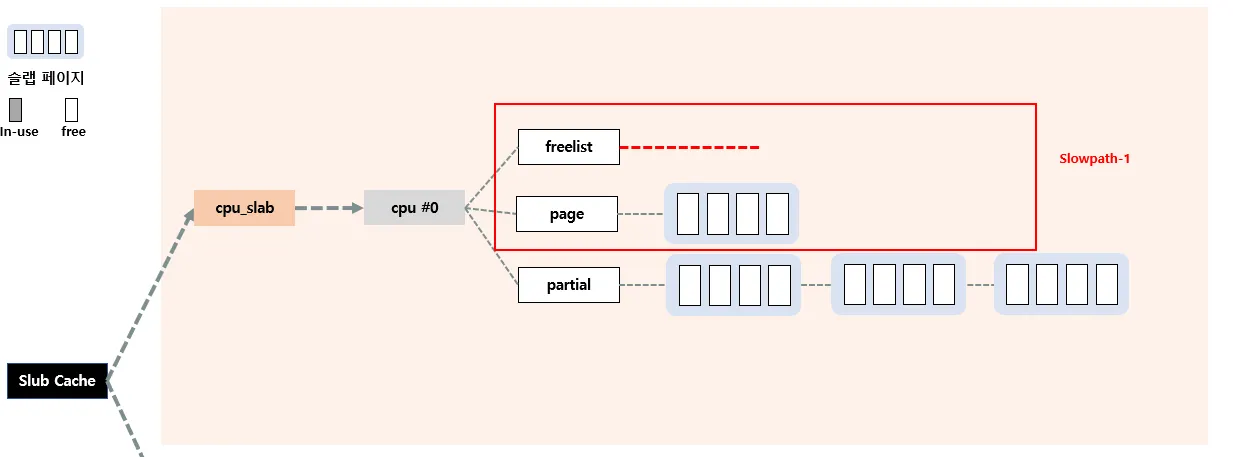
현재 c→freelist 에 할당해줄 수 있는 오브젝트가 없다. 따라서 c→page 슬랩페이지에 있는 오브젝트들을 c→freelist로 이동시킨다.
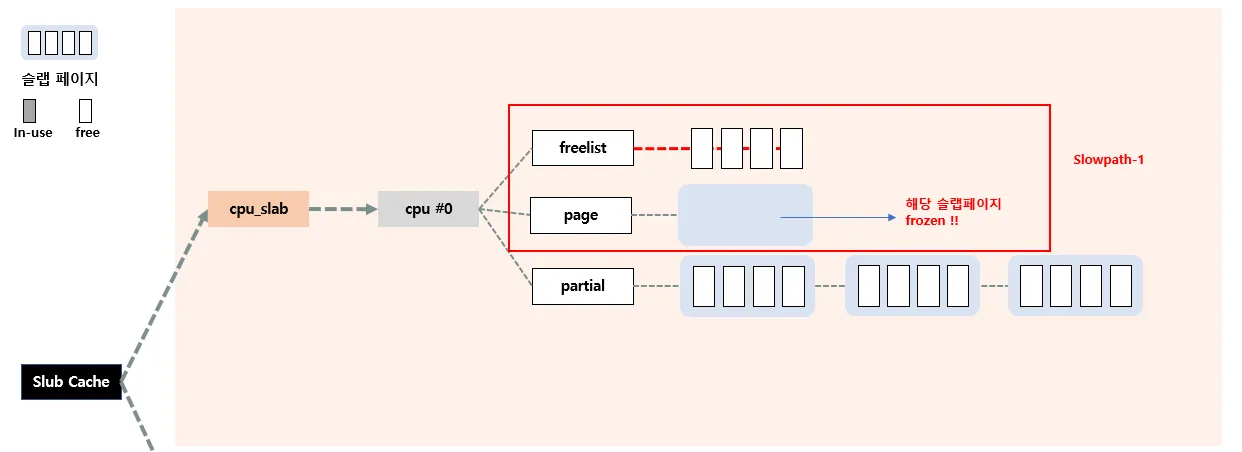
이제 Fastpath를 시행해서 할당해준다. 그리고 c→page에 있었던 슬랩 페이지의 오브젝트들이 전부 위로 올라갔으므로 해당 슬랩페이지는 unfrozen상태가 되며 이곳에 오브젝트가 하나라도 free되어 반환되기 전까지는 kmem_cache 슬랩 캐시의 관리를 벗어난다.
Slowpath-2
만약 Slowpath-1 단계에서 c→page에 free된 오브젝트가 없는 경우 Slowpath-2단계가 시행된다.
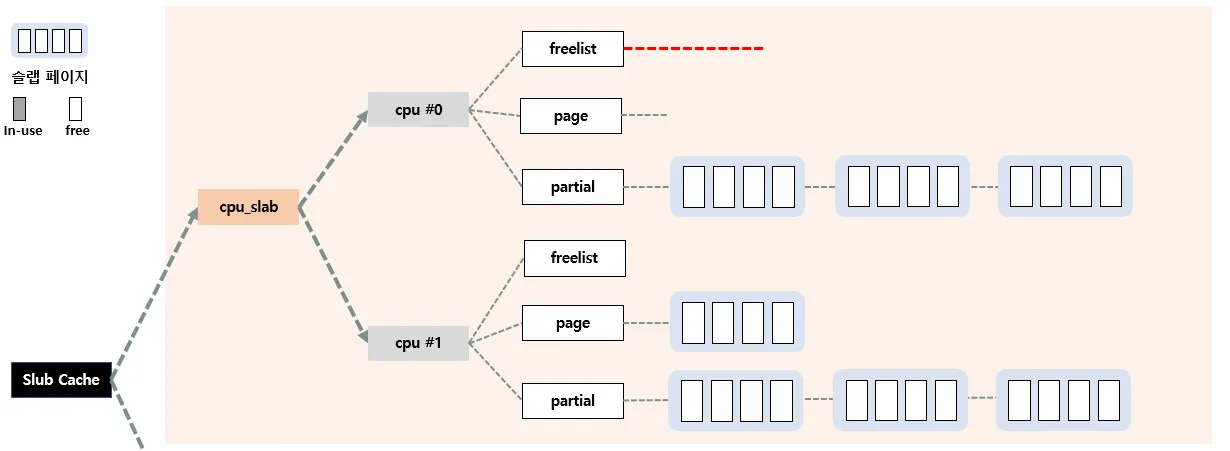
아까 Slowpath-1을 통해 4개의 오브젝트가 c→freelist에 올라간후, 4개 오브젝트 할당요청이 와서 fastpath로 4개다 할당해줬다고 가정하자.
그리고 또 할당요청이 왔다. 현재 c→freelist에는 할당해줄수 있는 오브젝트가 없으며, c→page→freelist 또한 할당해줄수 있는 오브젝트가 없다. 따라서 c→partial 슬랩 페이지를 이용한다.
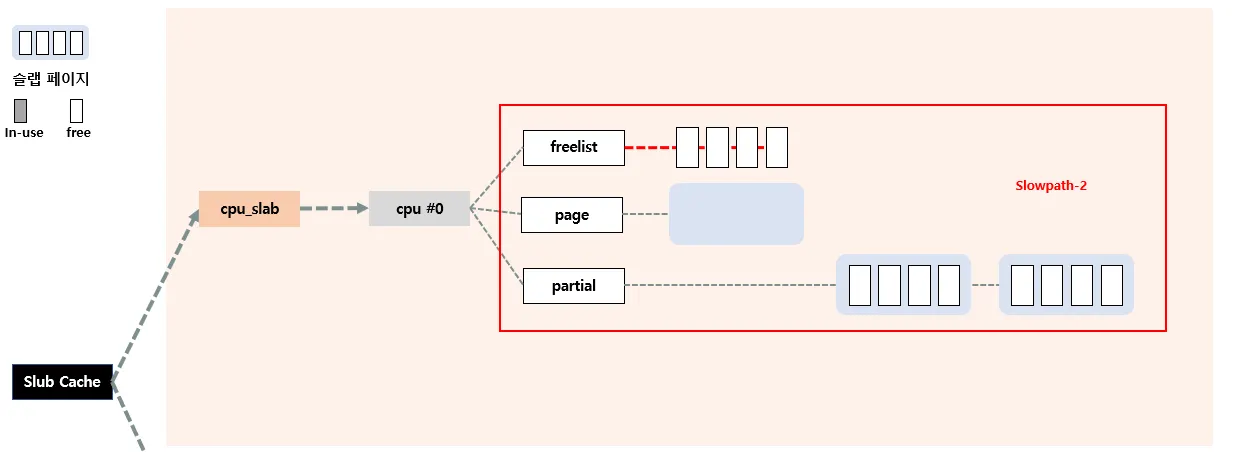
c→partial에 있는 슬랩페이지를 c→page로 올리고, 슬랩페이지 안의 오브젝트들은 c→freelist로 이동시킨다. 이로써 다시 Fastpath를 수행할 수 있게 된다.
Slowpath-3
Slowpath-2 단계서 c→partial 에도 할당가능한 오브젝트가 없다면 시행되는 단계이다.
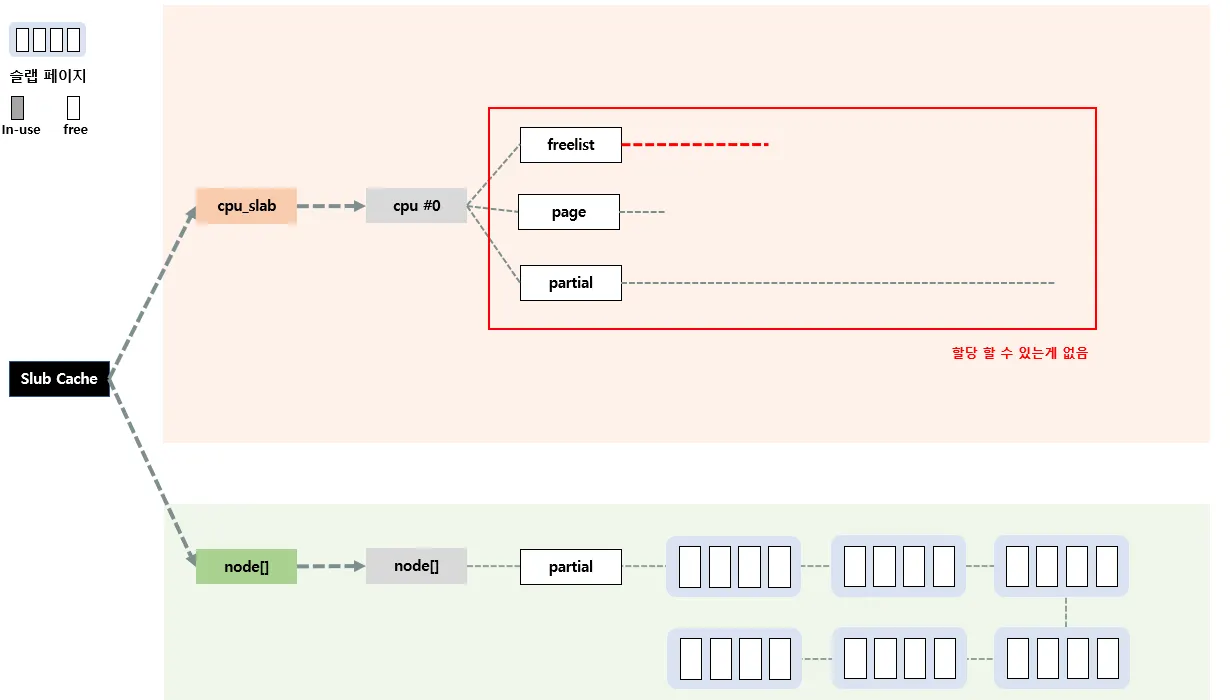
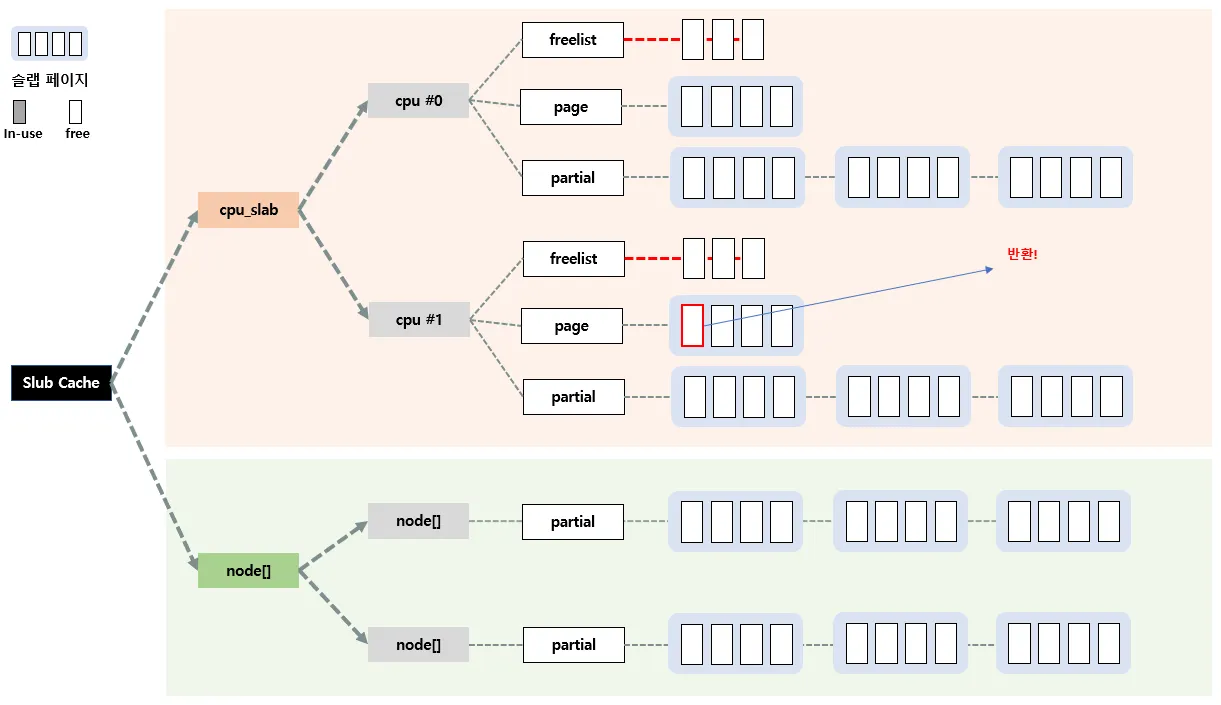
이렇게 per-cpu 슬랩 캐시에 이용할수있는 놈이 없는 경우 이제 per-node를 이용하는게 3단계이다.
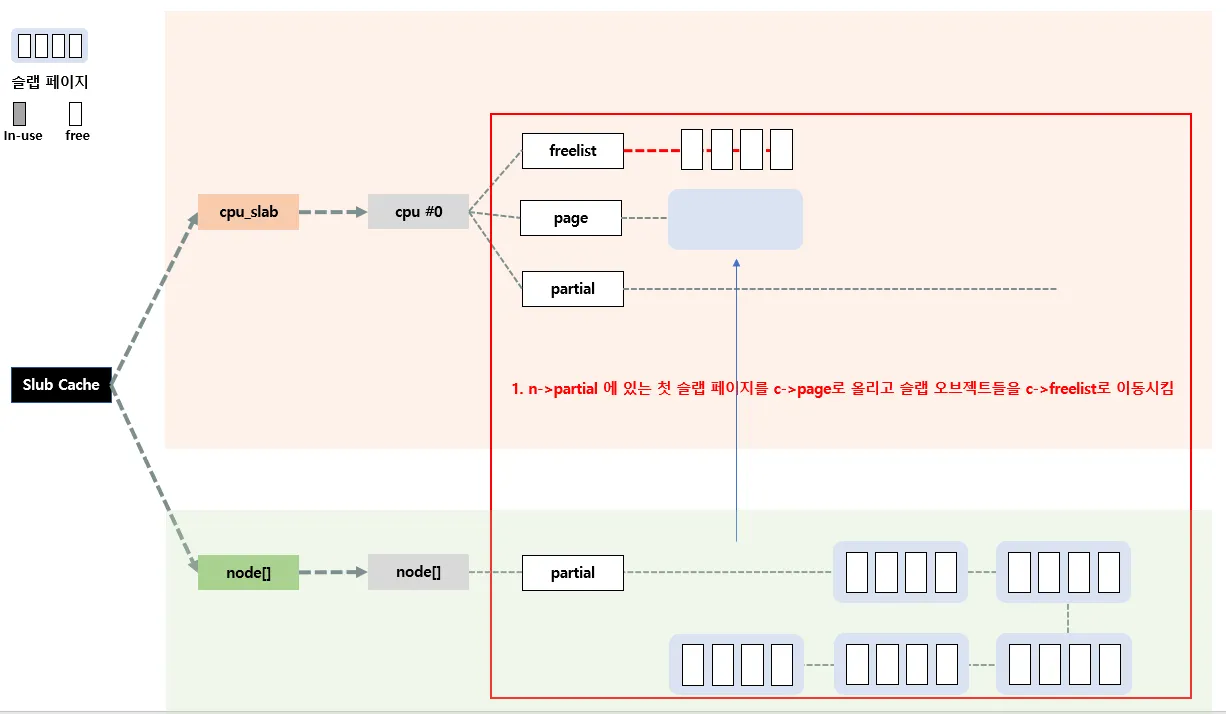
우선 n → partial에 들어있는 첫 슬랩 페이지를 c → page 로 올린 후, 슬랩 오브젝트들은
c → freelist로 이동시킨다.
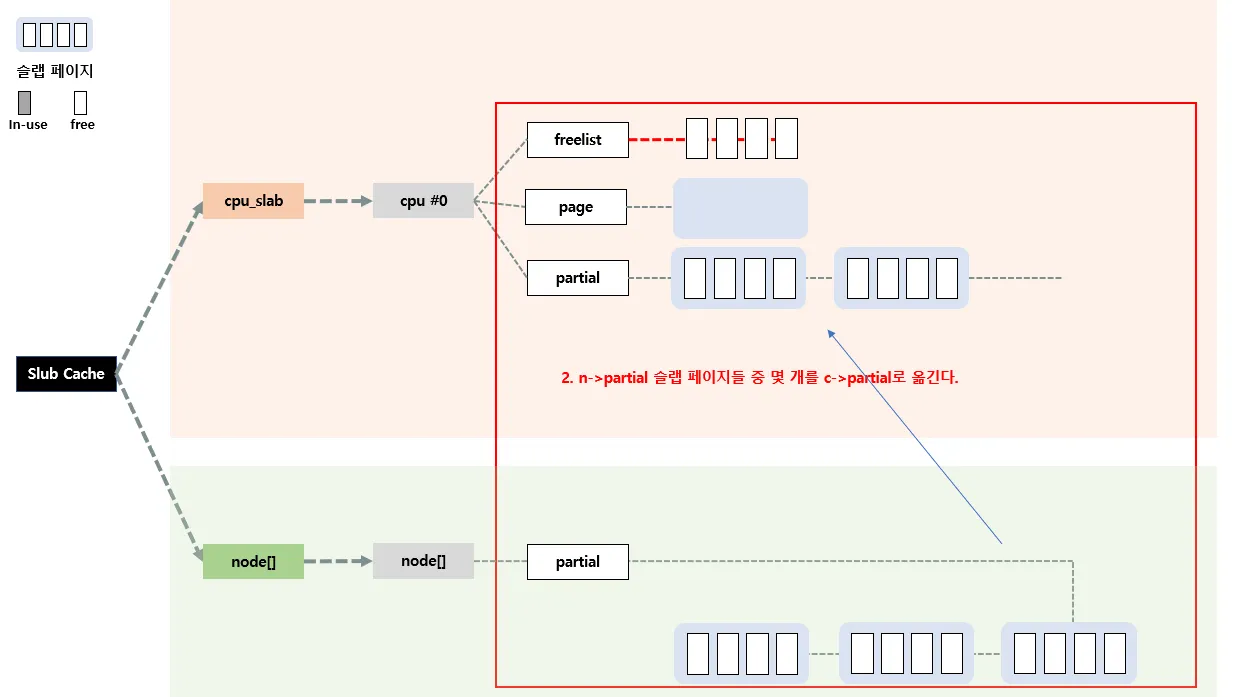
그리고 n→partial에 있는 슬랩 페이지들 중 일부를 c→partial로 이동시킨다. 만약 n→partial 리스트가 비어있는 경우에는 현재 per-node 슬랩 캐시말고 다른 노드의 n→partial을 뒤진다. 만약 여기도 없으면 마지막으로 Slowpath-4단계를 수행한다.
Slowpath-4
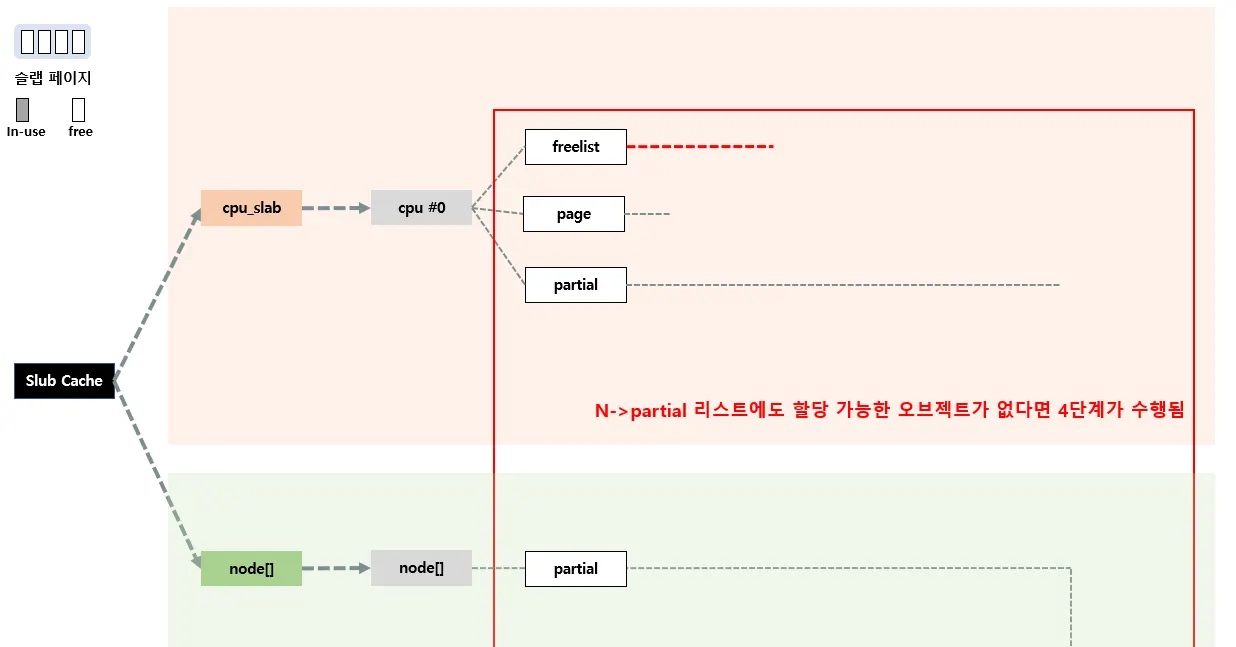
Fastpath, Slowpath1,2,3 다 실패하는 경우에 수행되는 단계로, 이는 아예 Buddy 할당자를 통해 새롭게 슬랩 페이지를 할당 받고, cpu_slab에 추가한다.
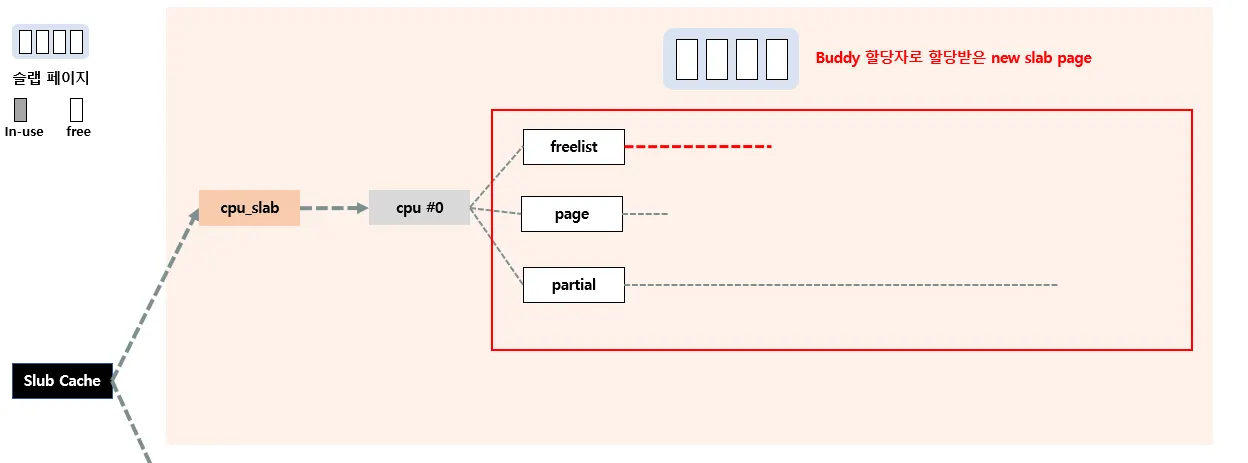
Buddy 할당자로 새로운 페이지를 할당받는다. 버디 시스템을 잘 모른다면 아래글을 읽고 오자

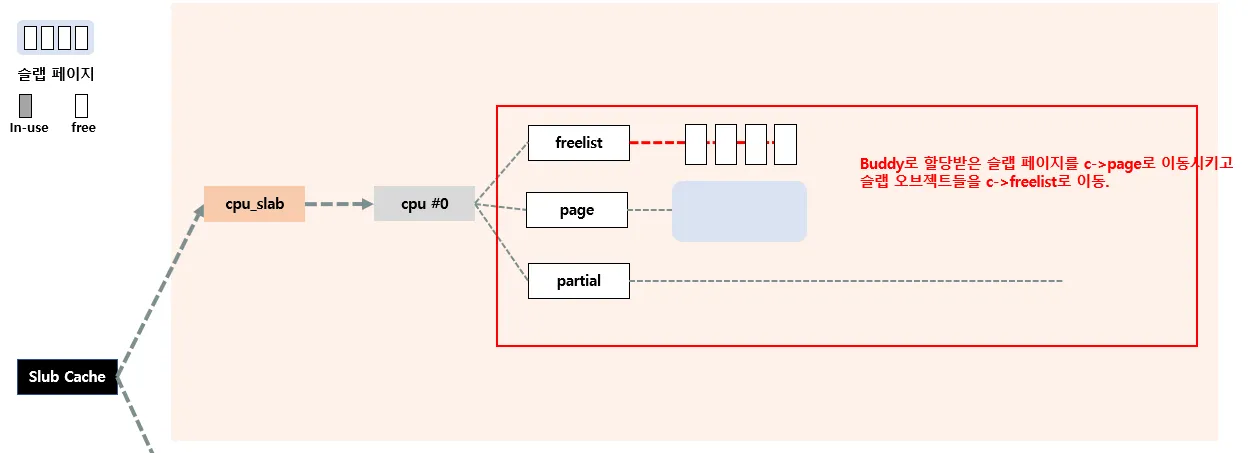
Buddy 할당자로 페이지를 할당받아 슬랩 페이지로 초기화한 후 c->page, c->freelist 에 슬랩 오브젝트를 옮긴다.
6. Slub 오브젝트 해제
이번엔 슬랩 오브젝트가 반환되는 경우 로직을 살펴보자.
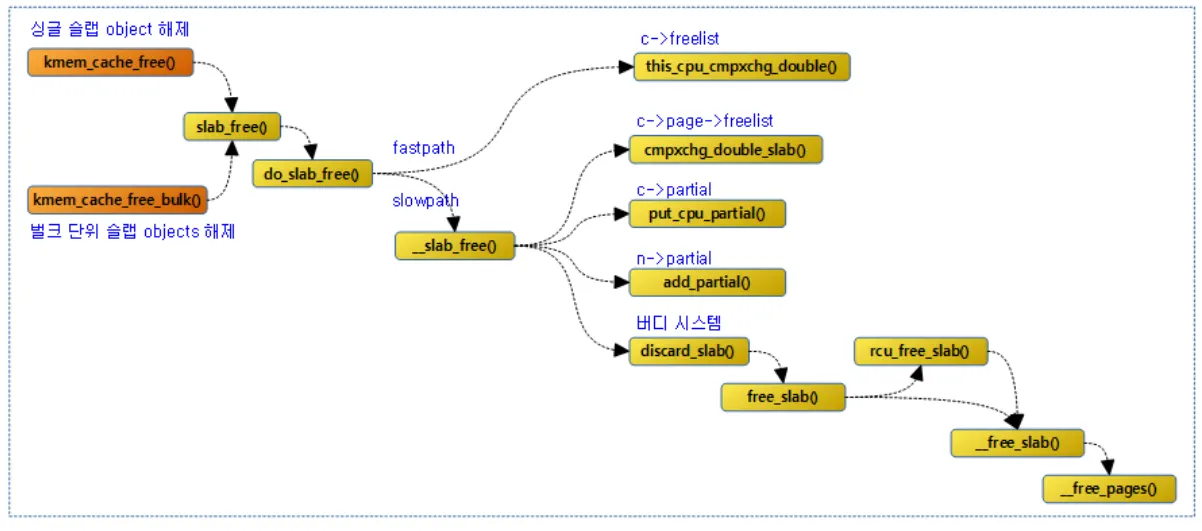
오브젝트가 할당될 때도 Fastpath, Slowpath에 따라서 어디에 있는 놈이 할당되는지 달라졌다. 반환되는 과정도 마찬가지이다. Fastpath와 Slowpath 방식으로 반환되는데 위 그림처럼 반환되는 위치를 정리할 수 있다
•
c→freelist 에 반환되거나 → faspath
•
c→page→freelist 에 반환되거나 → slowpath
•
c→partial 에 반환되거나 → slowpath
•
Buddy 시스템에 반환되거나 → slowpath
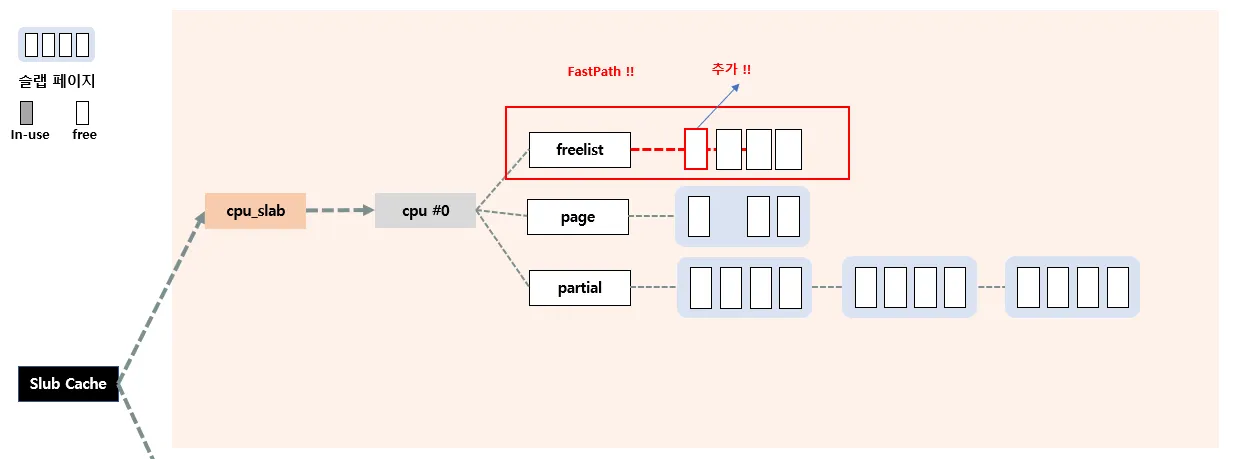
Fastpath
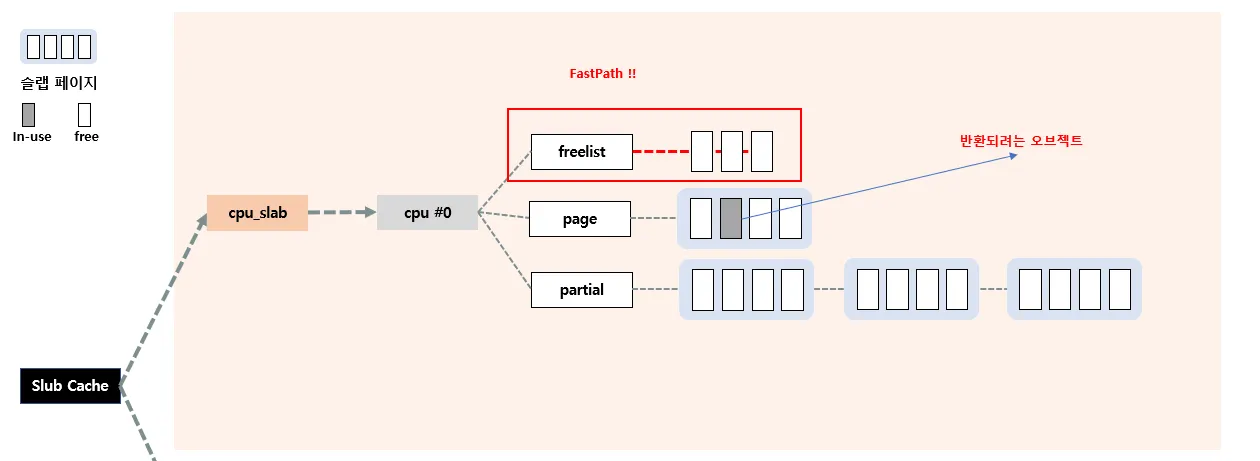
현재 반환되려는 오브젝트가 전담(현재) CPU의 c→page 슬랩페이지에서 관리하는 놈인 경우 Fastpath 방식으로 반환한다. 즉, c→freelist에 추가시킨다
Slowpath
1. c→partial의 슬랩 페이지 혹은 다른 CPU의 c→page에 반환
만약 반환되려는 오브젝트가 c→page에서 관리하는 놈이 아니라면 slowpath로 전환된다.
" c→page에서 관리하는 놈이 아니다 " 라는 말은 매우 많은 케이스로 표현될 수 있다.
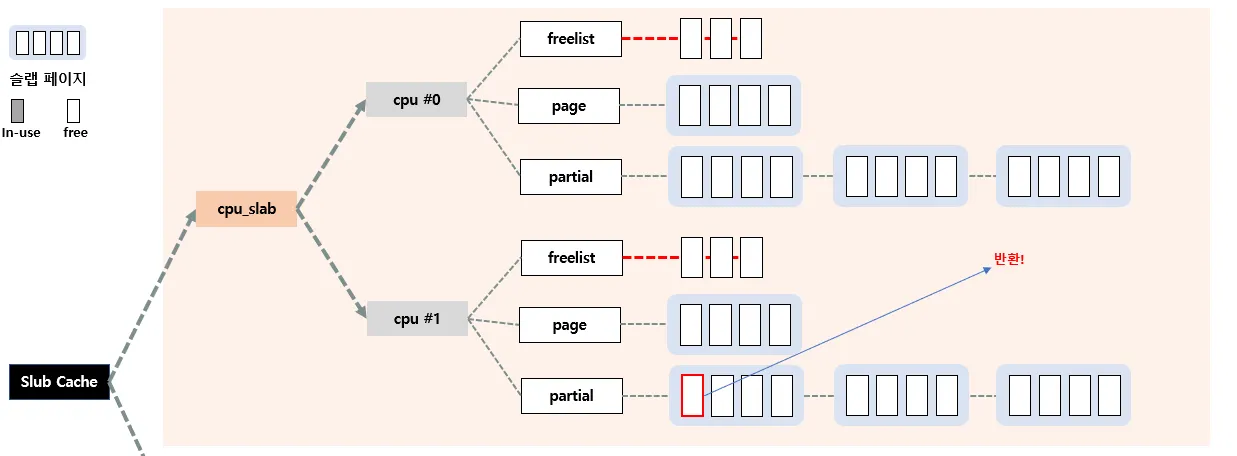
•
case 1 : 자기 전담 CPU 의 c→partial에서 관리하는 경우
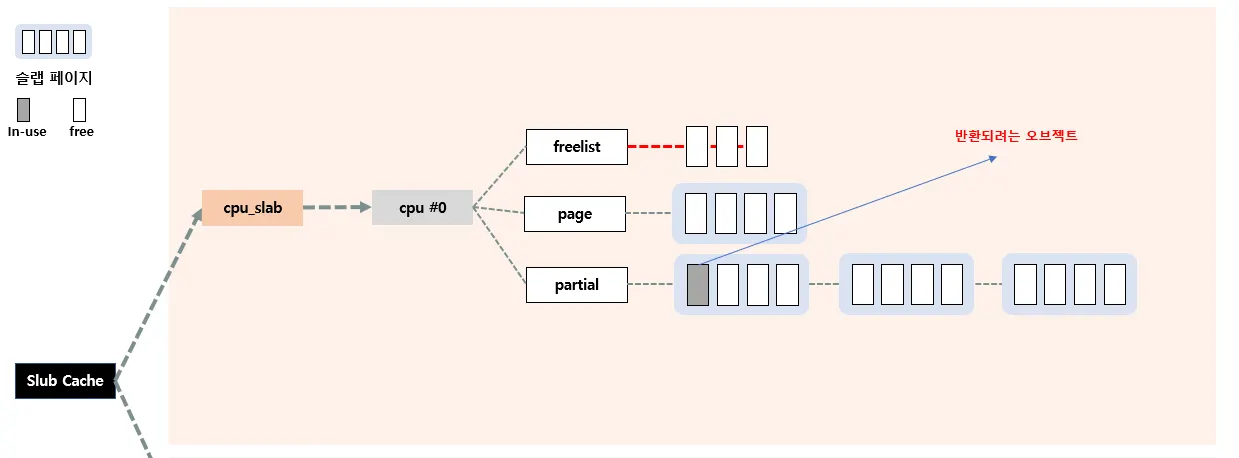
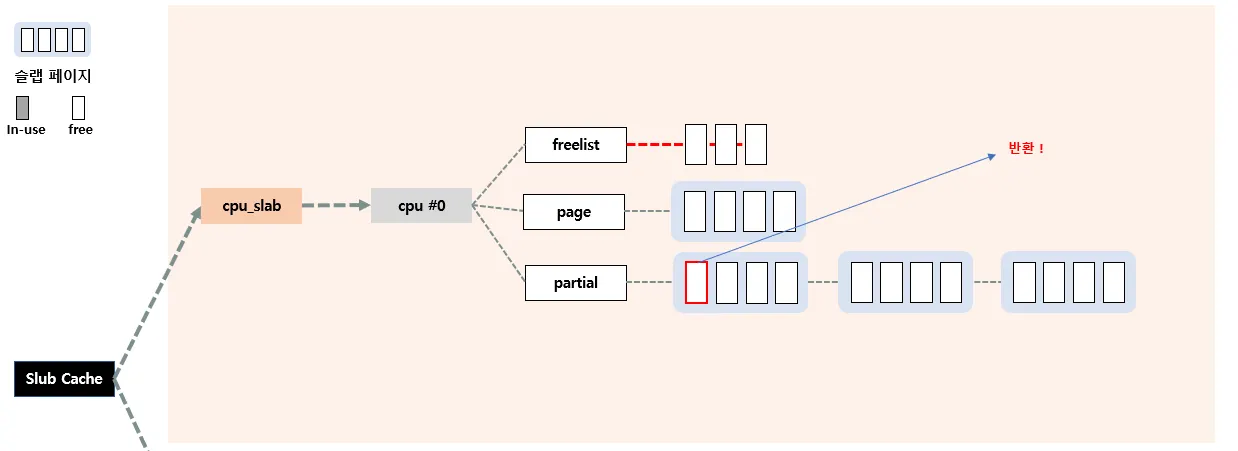
•
case 2 : 자기 전담 CPU가 아닌 다른 CPU의 c→page에서 관리하는 경우
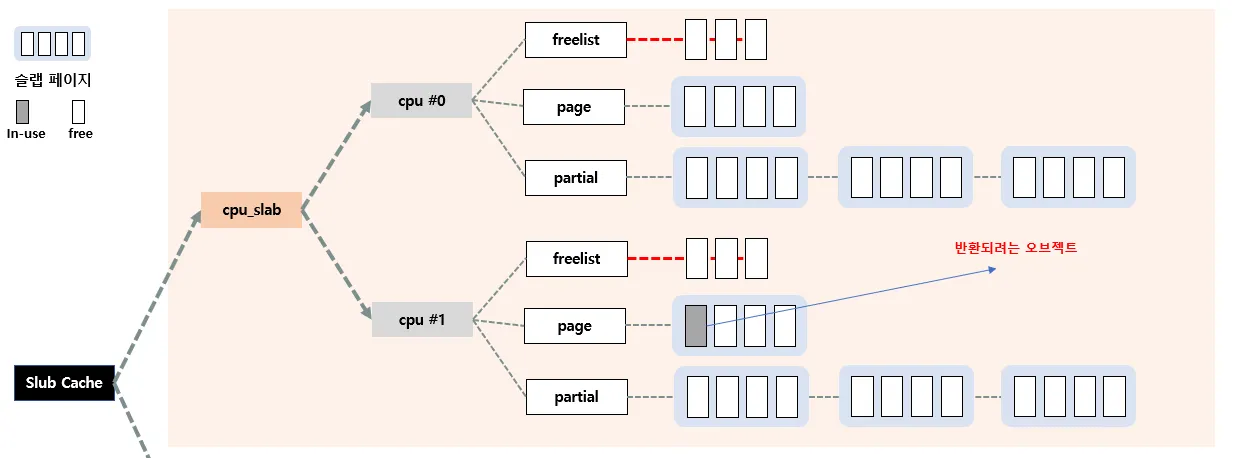
•
case 3 : 자기 전담 CPU가 아닌 다른 CPU의 c→partial에서 관리하는 경우
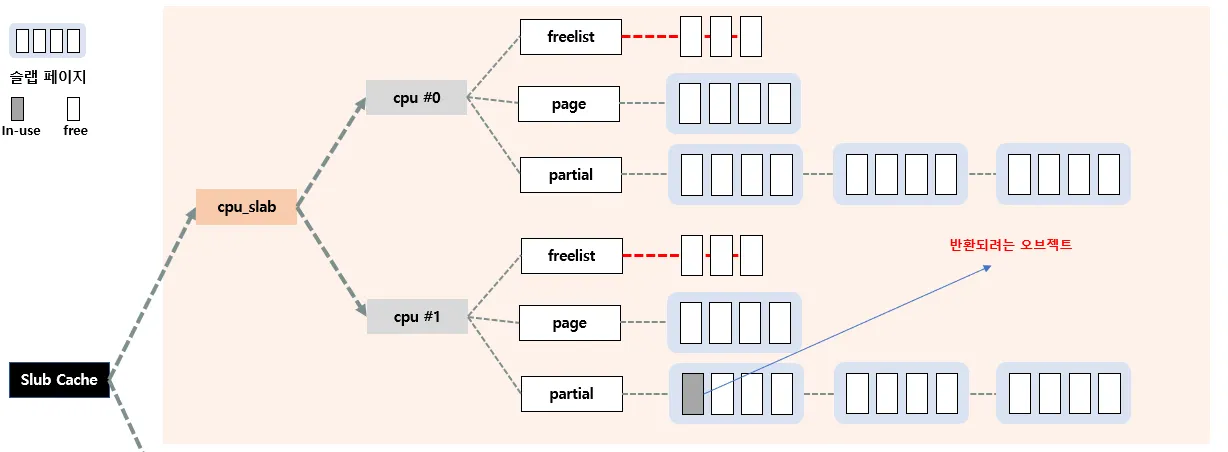
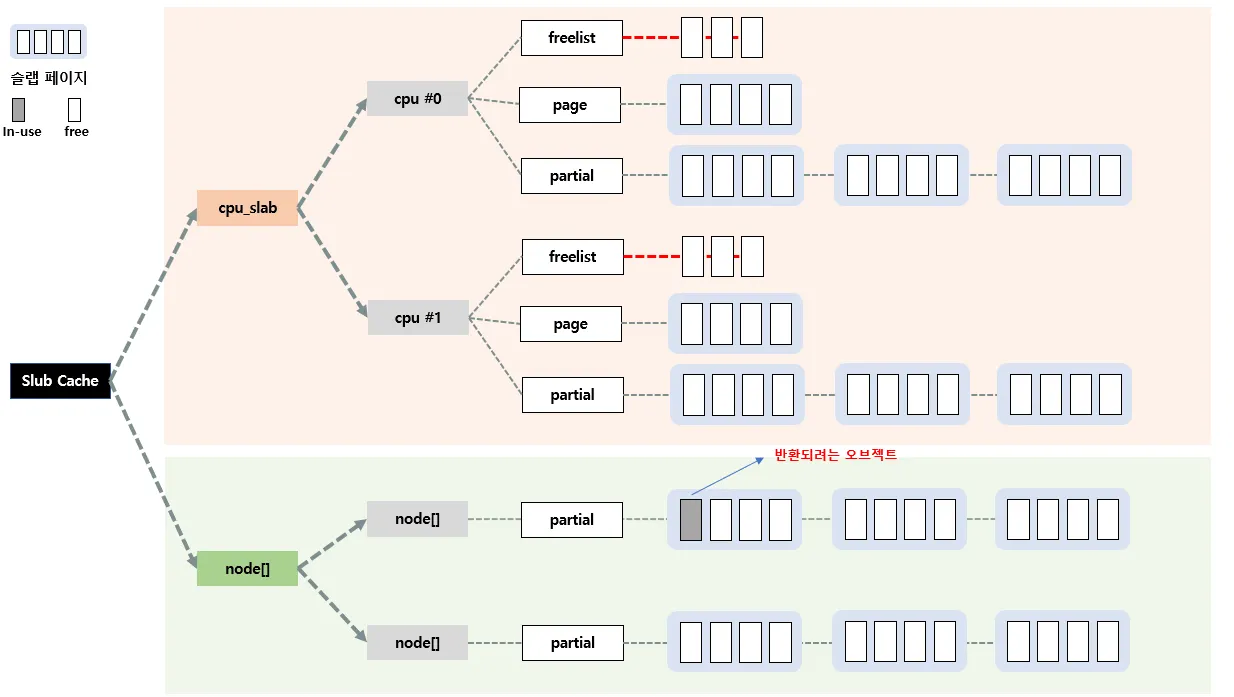
2. n→partial의 슬랩페이지에 반환
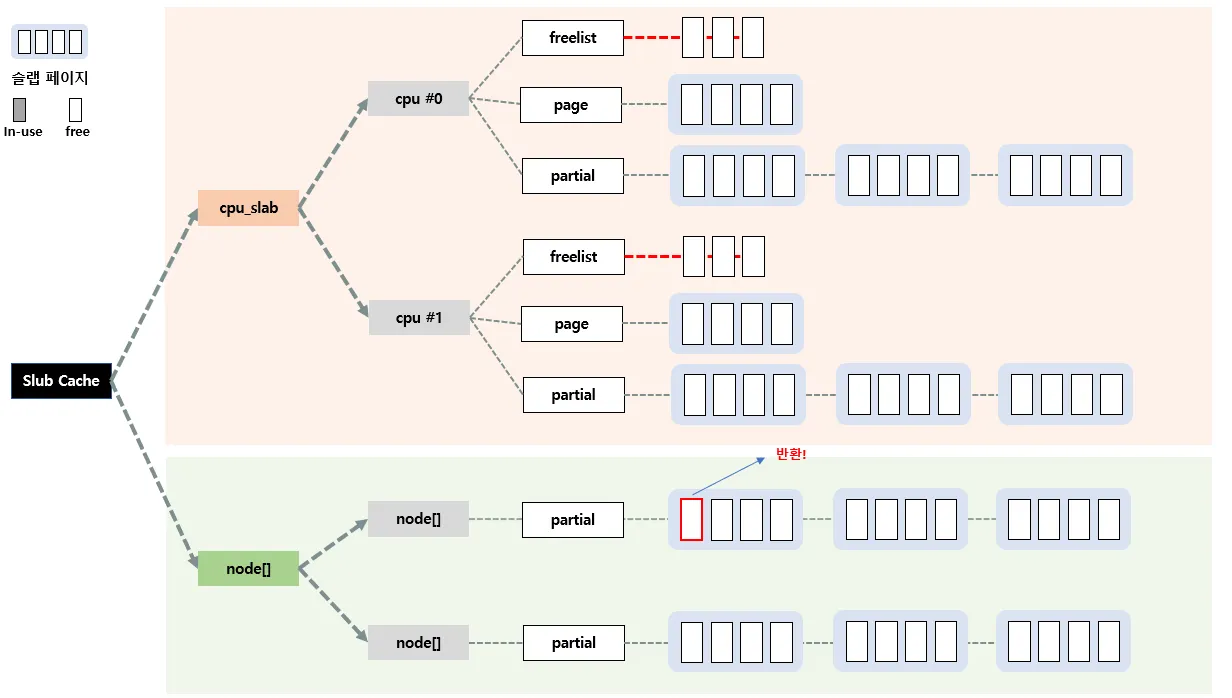
3. Buddy 시스템으로 반환
만약 아래 그림처럼 c→partial에서 관리할 수 있는 슬랩 페이지가 꽉차버렸고, 슬랩 페이지의 모든 오브젝트가 free되어있는 경우에는
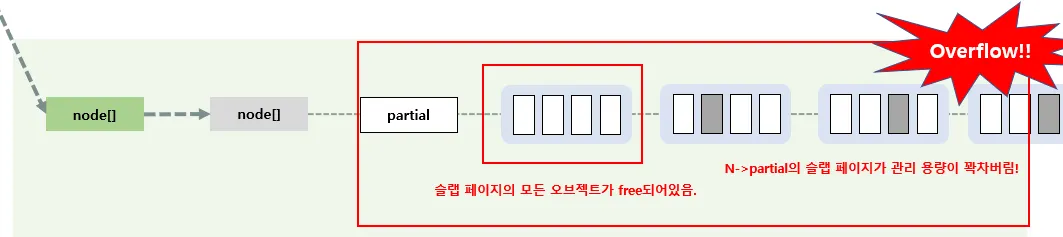
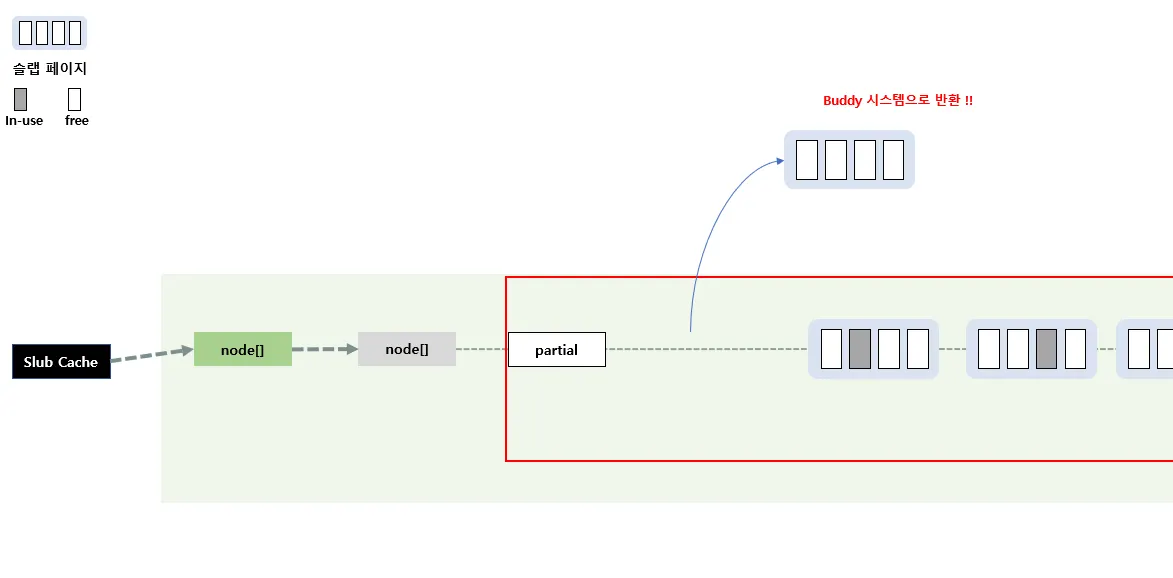
다음과 같이 Buddy 시스템으로 해당 슬랩 페이지를 반환시킨다.
6. Slab object 구조
그렇다면 여태 계속 말하고있는 slab object는 어떻게 구성되어 있을까? 간단하게 한번 알아보자
슬랩 오브젝트의 최소 사이즈는 다음과 같다
•
32bit : 4byte
•
64bit : 8byte
슬랩 오브젝트의 구성요소는 다음과 같다. 참고로 아래의 구성요소는 전부다 사용되는건 아니다.
FP(Free Pointer)
•
선두에 있는 free object가 다음 free object를 가리키는 역할을 한다.
•
데이터 주소 침범 등을 검출하는 경우 FP가 object 뒤로 이동되는 경우가 있다
Poison
•
데이터 주소 침범 등을 검출하기 위해 사용한다
•
슬랩 object가 사용 중이지만 초기화되지 않은 경우 0x5a('Z') 값으로 채운다
•
슬랩 object가 사용되지 않을 때 0x6b('k') 값으로 채운다.
•
정리하면 poison 은 값으로 에러 검출을 확인하는 용도이다
•
" slub_debug=P " 옵션 설정으로 poison 디버깅을 할 수 있다.
Red-Zone
•
데이터 주소 침범 등을 검출하기 위해 사용한다
•
object-size 좌우에 red-zone 값을 기록한 후 object의 생성과 소멸 시에 이 값이 변경되는 것으로 에러 검출을 한다
•
" slub_debug=Z " 옵션 설정으로 red-zone 디버깅을 할 수 있다.
Owner(User)-Track
•
슬랩 object의 생성과 소멸 시에 호출한 함수를 출력하기 위해 사용한다.
•
" slub_debug=U " 옵션 설정으로 Owner-Track 디버깅을 할 수 있다.
Padding
•
Align을 위한 부분이다.
•
패딩 값으로 0x5a=’Z’를 채운다
슬랩 오브젝트는 여러 상태로 위의 속성을 포함하여 표현될 수 있다.
1) 별도의 메타데이터가 없는 object
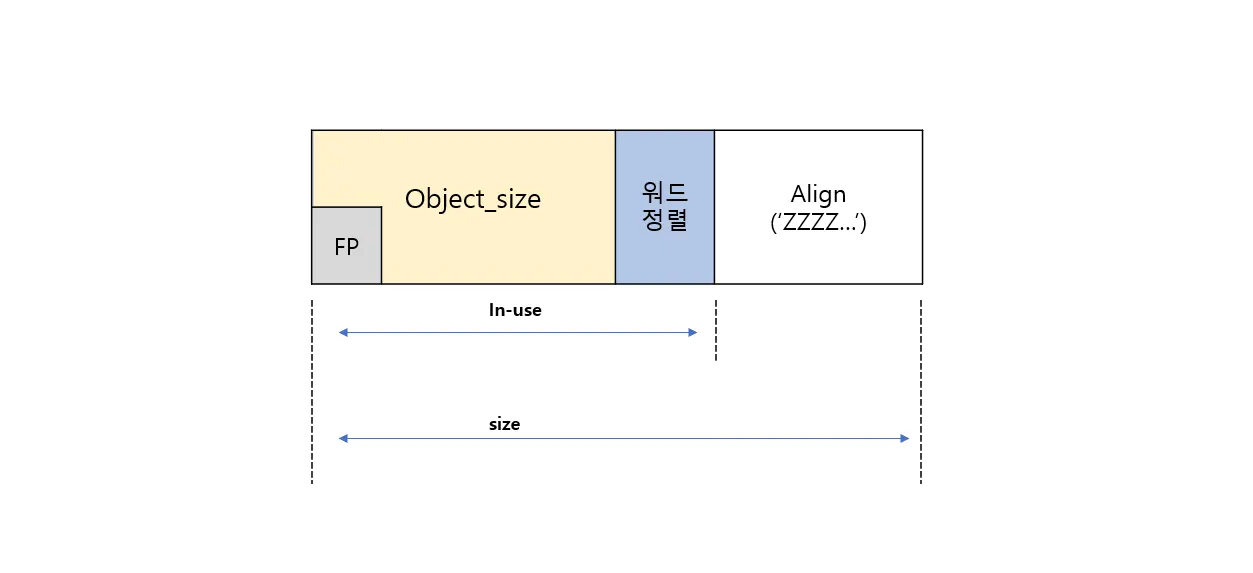
•
전체 오브젝트 사이즈는 실제 object 사이즈 (in-use) + align 단위이다
◦
ex) object_size : 22, Align 단위 : 8, 워드 정렬 단위 4
⇒ inuse : 24, Total size : 24
•
최소 정렬 사이즈는 워드(32bit : 4, 64bit : 8) 단위를 사용한다
2) FP가 이동된 object (posion 정보 추가)
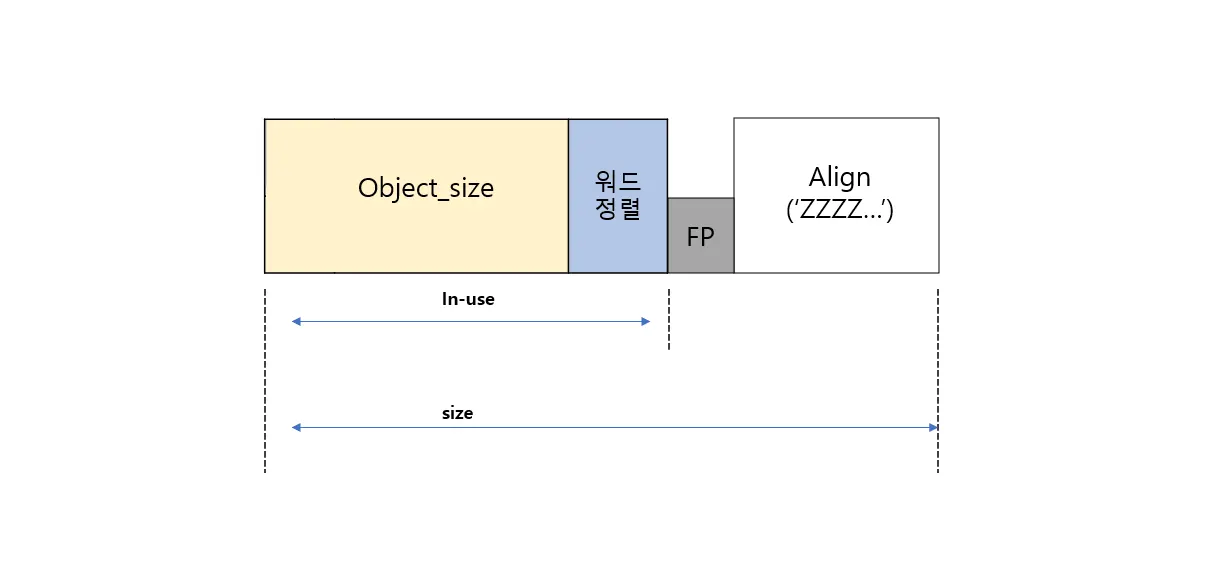
•
에러 검출 용도로 커널 옵션에 poison 을 키게되면 object 안에 에러 검출을 위한 정보가 삽입된다.
•
즉 object 위치에 별도의 정보를 기록해야 하기 때문에 FP를 뒤로 이동시킨다
3) red-zone 정보가 포함된 object
red-zone 정보는 object 좌우에 삽입된다고 했다
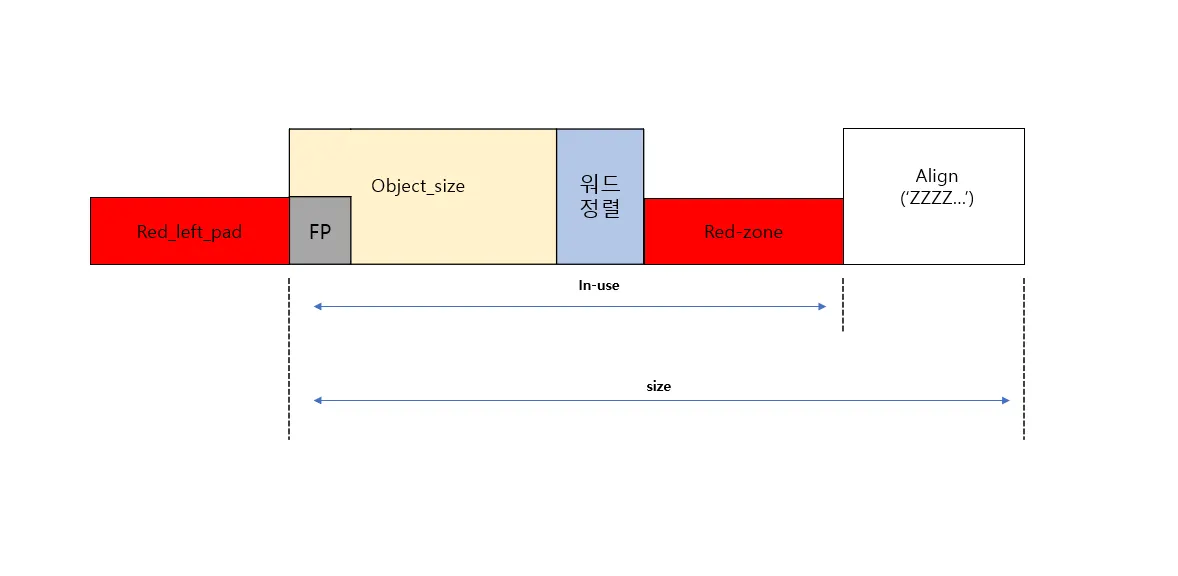
•
object 우측에 red-zone 정보가 삽입된다
•
좌측 red-zone은 이전 오브젝트의 데이터가 overwrite되는 것을 방지하기위함이다. overwrite가 되어도 red_left_pad가 있다면 다음 오브젝트의 데이터가 보장된다.
4) Owner-track 정보가 포함된 object
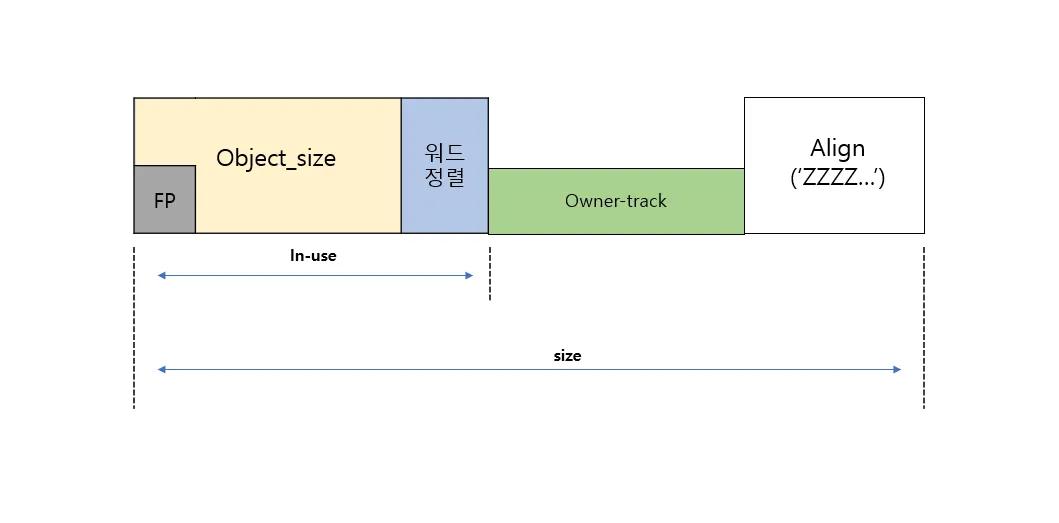
•
object 할당 및 해제를 디버깅하기 위해 inuse 사이즈 + 뒤에 삽입된다
5) FP이동(posion), red-zone, owner-track, Kasan 정보가 모두 포함된 object
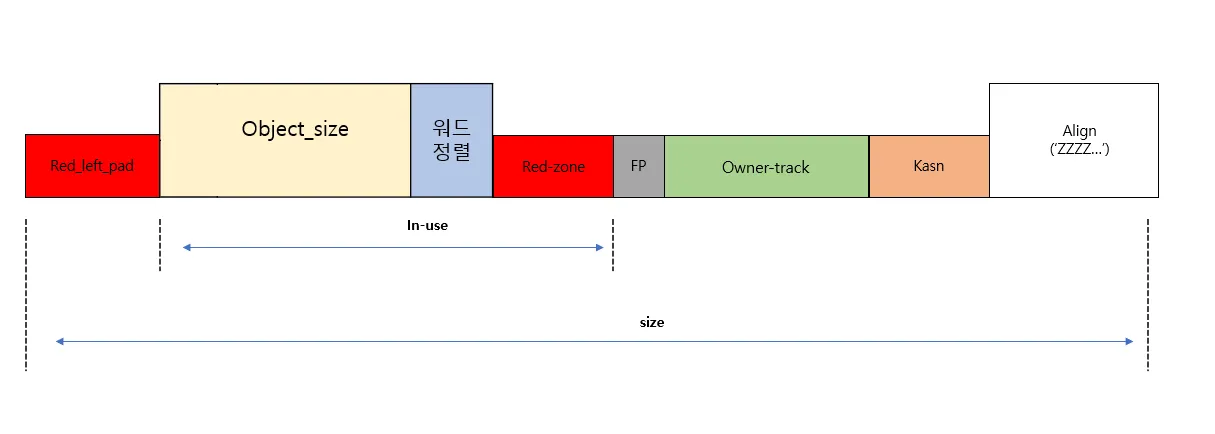
•
1~4 가 모두 들어간 오브젝트이다
•
추가적으로 커널의 에러를 검출하기 위한 KASAN 기능을 옵션으로 추가할 수가 있는데 해당 옵션이 on 된경우 owner-track 우측에 삽입된다.

