
작년 말 쯤 리눅스 커널에 대해 전체 프로세스 관한 공부를 진행했었다. 디테일한 내용은 아니였지만 예전 학교에서 배웠던 지식들을 복습할 수 있는 시간이였다. 이젠 좀 더 디테일하게 분석을 진행해보고자 한다.
가상메모리-물리메모리 의 관계와 슬랩 할당자, 스케줄링 기법 등에 관련해서 실제 소스코드 단에서 분석을 해볼것이다. 또한 해당 지식을 바탕으로 소형 운영체제를 한번 만들어 보는 것을 올해 목표 중 하나로 잡고있다.
오늘은 그 첫번째 시간으로 리눅스 커널의 가상메모리에 대해서 공부해보고자 한다.
1. 가상메모리란?
가상 메모리는 메모리를 관리하는 방법의 하나로, 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 주는 방식을 말한다. 가상 메모리를 이용하면 실제 물리메모리가 가지고 있는 크기를 논리적으로 확장하여 사용 할 수 있다.
그럼 앞서 왜 가상메모리를 사용할까?
논리적으로 메모리를 확장하여 사용 할 수 있다
실제 물리메모리가 가지는 공간보다 더 큰 공간으로 확장할 수 있다. 그렇다고 해서 더 실제 물리 메모리가 가지고 있는 공간 그 이상으로 데이터를 저장할 순 없지만, ram(주기억장치)이나 디스크, 레지스터 등의 공간을 연속적으로 가상 공간에 매핑할 수 있다.
프로세스들에게 동일한 메모리 공간을 제공해 줄 수 있다
유저는 물리 메모리 정보가 아닌 OS가 제공해주는 가상 메모리 공간만 신경쓰면 된다. 만약 가상메모리 없이 물리메모리만을 사용하는 경우 A, B 두개의 프로세스가 현재 동시에 돌아간다면 두 개의 프로세스는 서로의 물리 메모리 공간을 신경써서 동작해야 한다.
여기서 '신경쓴다'의 의미는 A는 B가 사용하는 물리 메모리 영역을 실시간으로 알아야 하고 B 역시 A의 사용영역을 실시간으로 파악해야한다. 이는 매우 비효율적이다. 하지만 가상메모리를 사용하게 된다면 유저는 단지 OS가 제공해주는 가상 메모리 영역만 이용하면 된다. 나머지 관리는 OS 내부에서 처리된다
메모리 관리에 효율적이다
당연히 연속적으로 존재하는 데이터를 읽고 처리하는게 빠르다. 하지만 우리는 컴퓨터를 사용하면서 많은 데이터를 생성하고 삭제하고 수정하는 동작을 수행한다. 따라서 초기에는 연속적으로 할당되어 있던 데이터들이 시간이 지나면 들쑥 날쑥 저장된다. 가상메모리를 이용하면 이렇게 연속적이지 않은 메모리를 논리적으로 연속적인 메모리 형태로 사용가능하다.
가상메모리 < - > 물리메모리
가상 메모리의 단위는 페이지 단위로 관리되고 물리 메모리는 프레임 단위로 관리된다. 페이지와 프레임은 동일한 사이즈를 가지며 이는 32bit 기준으로 4Kb이다.(이는 아키텍처마다 다름)
메모리를 효율적으로 사용하기 위해 이렇게 페이징 기법을 이용하여 실제 관리가 들어간다. 좀더 내부적으로 들어가자면 앞서 말한 페이지는 하드웨어에 의해 정해지는 고정 사이즈이다. 반대로 세그먼트는 method, procedure, function, object, variables, stack 등 프로그램의 논리적 단위로 나누는 방법이다.
페이징 방법이 기계적으로 페이지 크기 만큼 일정한 크기로 나누는 것과 달리 세그멘테이션 방법은 프로그램의 논리적 단위를 잘 나눠 주어 서로 침범하지 못하게 보호해주는 방법이다. 따라서 페이징 기법과 세그먼테이션 기법을 혼용하여 실제 메모리를 관리하게 된다.
세그먼테이션 기법에 대한 설명은 후에 하도록 하고 페이징 기법에 대해서 우선 알아보자.

왼쪽에 보이는 영역이 가상메모리이다. 현재 동작하고 있는 프로세스는 해당 가상 주소만을 보며 동작한다. 실제 데이터는 가상 메모리 영역에 존재하지 않는다. 이는 주기억장치라 불리는 물리메모리(통상적 RAM)에 존재한다.(혹은 디스크)
그렇다면 가상 메모리를 통해 실제 데이터를 처리하기 위해선 가상 주소 → 물리 주소의 변환 과정이 필요하다. 따라서 가상 주소를 물리 주소로 변환해주는 페이지 테이블 이 존재한다.
가상 메모리를 사용함으로써 연속적이지 않은 물리 메모리를 연속적인 메모리로 이용할 수 있다고 했다. 이 의미는 바로 저 페이지 테이블 을 이용하여 연속적으로 처리될 수 있는 것이다.
실제 가상 주소를 물리 주소로 변환하는 과정은 MMU(Memory Management Unit) 이라 불리는 하드웨어가 수행한다.
MMU는 실제 CPU 코어 내부에 탑재되어 동작한다
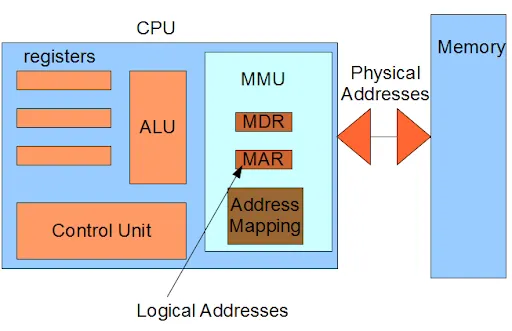
MMU가 가상 주소를 물리 주소로 변환하는 과정은 다음과 같다.
우선 MMU 내에 존재하는 TLB(Translation Lookaside Buffer)를 참조한다. TLB 에는 가장 최근에 변환한 페이지 테이블 엔트리를 정보가 들어있다. 일종의 캐시 버퍼라고 생각하면 편하다. TLB 내에는 대략 128~256 개의 페이지 테이블 엔트리를 가지고 있다.
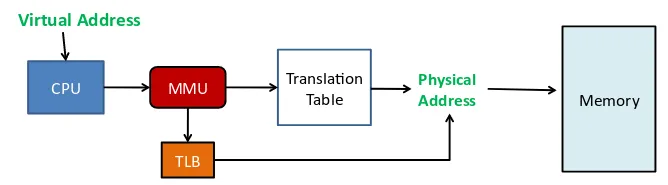
MMU는 CPU를 통해 변환하려는 가상주소를 TLB에서 먼저 검색한다. 올라와 있는 엔트리가 존재하면, 바로 물리 메모리로 주소 변한 후 원하는 데이터를 가져올 수 있다. 만약 TLB내에 올라와 있는 엔트리가 없다면 페이지 테이블을 참조해서 변환 과정이 일어난다
여기서도 두가지 경우로 나뉘는데, 페이지 테이블에서도 원하는 엔트리가 없다면 이를 페이지 폴트 라 부르며 디스크에서 페이지 교체 알고리즘을 이용하여 필요한 페이지를 가져오게 된다. 그 후 페이지테이블을 업데이트한다.
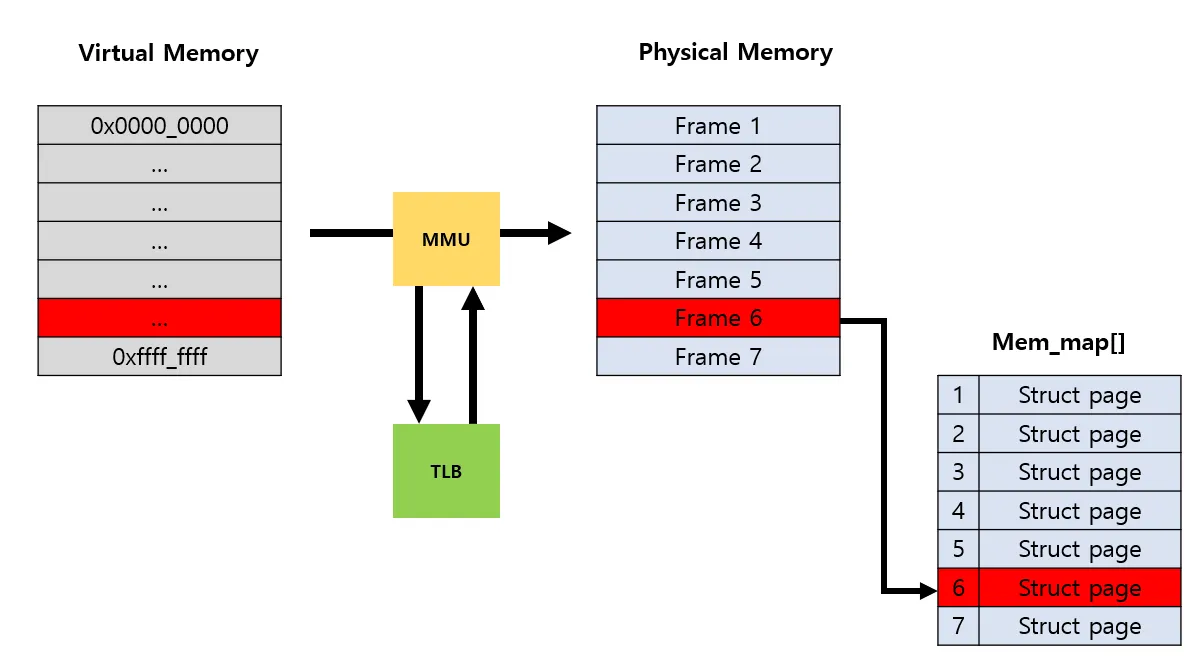
MMU, TLB 를 포함하여 전의 그림을 다시 표현하면 다음과 같다(매우 간단히..). 물리 메모리에서 각 프레임을 4Kb 단위로(32bit 기준) 관리하며 프레임 번호를 매기는데 이를 page frame number 라고 부른다.
page frame number 이 필요한 이유는 page descriptor 로 물리 주소를 관리하기 위함이다. 여기서 말하는 page descriptor는 페이지 프레임을 관리하는 자료구조라고 생각하면 된다.

쉽게 말해 커널이 각 페이지 프레임의 현재 상태를 알아야 하기 때문에 필요하 자료 구조
⇒ 페이지 디스크립터가 실제 struct page 이다
page frame number 를 계산하는 방법은 간단하다.
물리주소 >> 12
ex) 0x3333 >> 12 // Result is 3
⇒ 0x3333 's PFN is 3.
PFN(page frame number)를 통하여 우리는 page 구조체의 주소를 알 수 있다. 여기서 page 구조체의 주소를 알아야 하는 이유는 실제 물리 메모리 페이지 프레임에 대한 모든 정보는 struct page 타입의 mem_map 배열에 들어있기 때문이다.
정리하면 변환하려는 VA(Virtual Address) 를 통해 page descriptor를 알 수 있으며, 반대로 page descriptor를 통하여 VA(Virtual Address)를 알 수 있다.
가상 주소 -> 물리 주소 -> 페이지 디스크립터
페이지 디스크립터 -> 페이지 프레임 번호 -> 물리 주소 -> 가상 주소
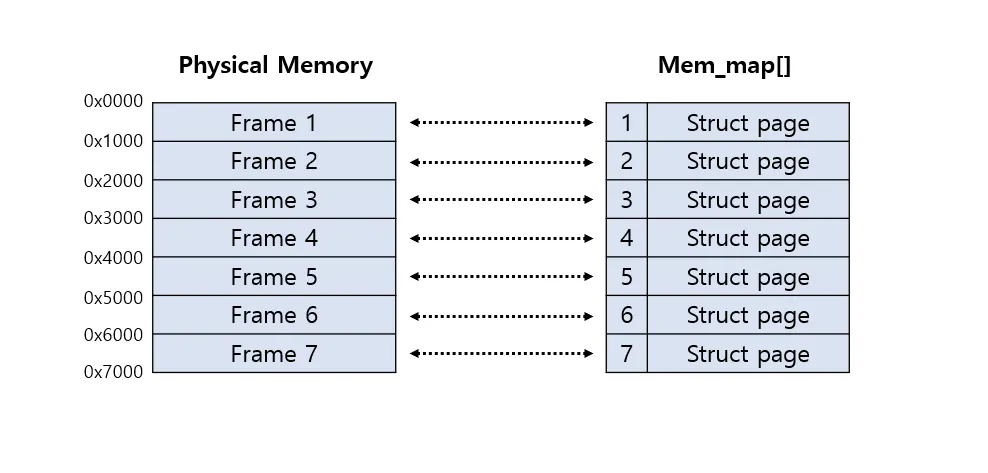
위 사진 처럼 모든 물리 메모리 페이지마다 하나의 페이지 디스크립터가 할당된다. 따라서 사이즈를 최대한 줄이기위해 페이지 디스크립터내에서 관리되는 멤버들을 유니온 타입으로 묶어 사용하도록 설계되었다. struct page의 멤버들은 다음과 같다
struct page
{
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union
{
struct
{ /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
struct
{ /* page_pool used by netstack */
/**
* @dma_addr: might require a 64-bit value even on
* 32-bit architectures.
*/
dma_addr_t dma_addr;
};
struct
{ /* slab, slob and slub */
union
{
struct list_head slab_list;
struct
{ /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union
{
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct
{ /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
struct
{ /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
};
struct
{ /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
unsigned long _compound_pad_2;
/* For both global and memcg */
struct list_head deferred_list;
};
struct
{ /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union
{
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
struct
{ /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
};
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
};
union
{ /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;
C
복사
출처 : https://elixir.bootlin.com/linux/v5.6.19/source/include/linux/mm_types.h
page 구조체 멤버들은 크게 다음과 같이 구성되어 있다
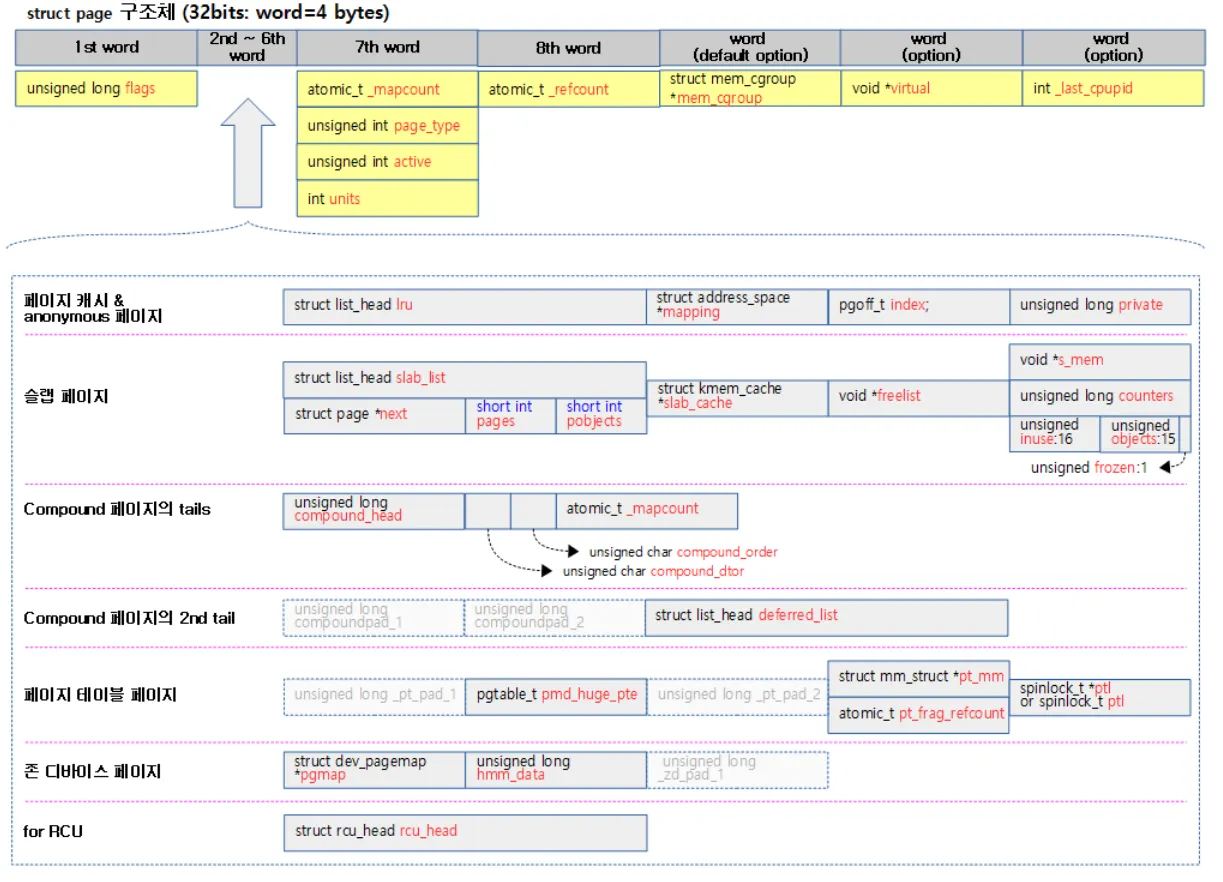
1.
unsigned long flags : 페이지의 상태를 나타내는 플래그
2.
union ... : 페이지 타입별로 필요한 정보들이나 리스트 구성을 위한 멤버들이 포함됨
•
cache page
•
슬랩(slab, slob, slub) page
•
Compound tail page
•
페이지 테이블(pgd, pud, pmd, pte)용 page
•
존 디바이스 page
3.
union ... : 페이지 매핑 카운터나 커널 페이지 타입을 지정할 수 있는 멤버들이 포함됨
•
_mapcount
여러 개의 페이지 테이블에서 이 페이지를 매핑하는 경우 매핑 카운터가 증가된다
•
page_type
•
active
•
units
4.
atomic_t _refcount : 페이지에 대한 참조 카운터
5.
struct mem_cgroup *mem_cgroup
메모리 cgroup을 사용할 때 이용하는 포인터 변수
cgroup이란 프로세스들이 사용할 수 있는 컴퓨팅 자원들을 제한 및 격리 시킬 수 있는 기능이다
6. void *virtual : 커널 주소 공간의 가상 주소
7. int _last_cpupid
이제 실제로 가상 주소를 어떠한 방식을 통해서 물리 주소로 전환시키는지 알아보자
어떠한 방식으로 변경시킬까?
여때까지 가상주소가 물리주소로 변경되는 전체 프로세스에 대해서 알아보았다. 또한 변환의 역할을 MMU 하드웨어에 의해서 일어나며 내부 TLB 를 통해서 좀더 빠른 전환(캐싱)을 제공할 수 있다는 것을 확인했다. 일단 잠시 TLB 에 대한 내용은 접어두고 생각해보자.
Page size가 4Kb이고 32bit 시스템이라면 다음과 같은 page table 사이즈를 갖는다.
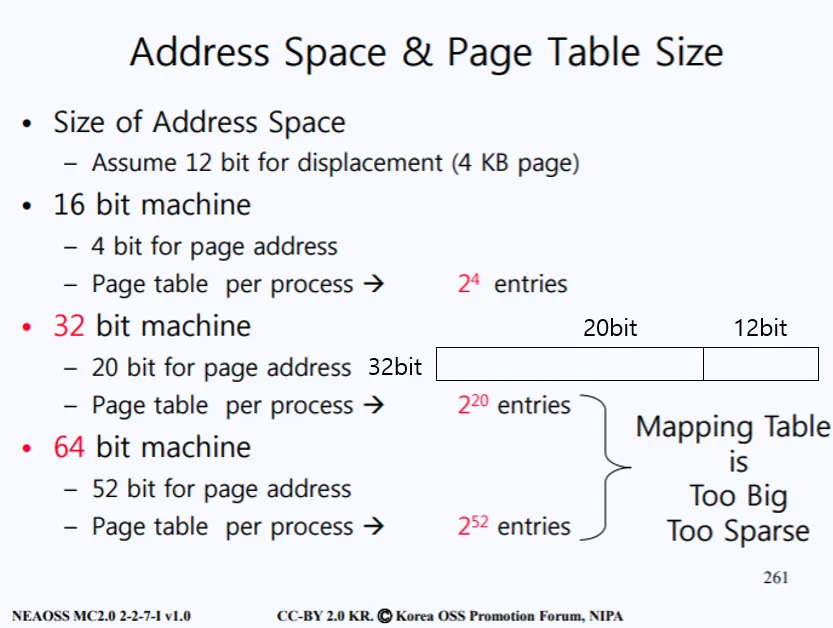
4Kb(4096byte)의 주소를 표현하기 위해선 2^12 공간이 필요하므로 12bit가 필요하다. 그렇다면 자연스럽게 나머지 20bit는 해당 페이지가 어디있는지를 찾기 위한 페이지 테이블을 위한 주소 공간으로 사용된다. 따라서 페이지 테이블은 1Mb(2^20)개의 Page table entry를 갖게된다.

가상 주소가 물리 주소로 변환되는 간단한 예시이다. 상위 20bit는 PTN로 사용된다. 현재 0x7444 인덱스에 해당하는 PFN가 존재한다. 해당 PFN에 해당하는 Frame 주소를 기준에서 가상 주소의 하위 12bit를 오프셋을 더하여 물리 주소가 계산된다.
Page Table 구조
생각을 한번 해보자. 만약 극단적으로 현재 A라는 프로세스 하나만이 동작중이고 위 그림의 빨간 블록의 주소만이 현재 사용된다. 그렇다면 해당 가상 주소를 물리 주소로 변경하는 과정이 일어날 것이고 그때의 페이지 테이블은 1MB개의 PTE 중 단 하나만이 사용 될 것이다. 나머지 PTE는 사용되지 않아 낭비되고 있다. 또한 Page Table은 그 자체만으로 크기가 크기 때문에 주로 Ram에 존재한다.
매우 비효율 적이지 않는가? 어떻게 하면 Page Table의 사이즈를 줄일 수 있을까?
그 해답은 바로 Page table의 다양한 구조로 설명된다
1. Multi-level Page Table
페이지 테이블을 여러 단계로 쪼개어 사용한다. 가장 기초적인 2단계 페이징기법은 다음과 같다
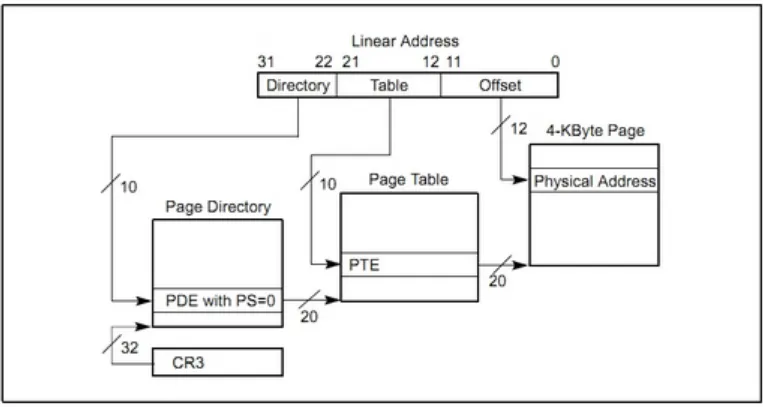
x86 architectual
기존 페이지 테이블을 위한 20bit를 각각 10bit, 10bit로 쪼갠다. 첫 10bit를 Page Directoy Table로 구성하여 각 Page Table을 가리키는 포인터들로 구성한다. 따라서 Page Directoy는 1024(2^10)개의 엔트리를 갖는다. 이렇게 함으로써 사용하지 않은 Page Table를 NULL로 만들수 있고, 메모리 사용 공간을 줄 일 수 있다.
CR3레지스터에는 Page Directory의 base 주소가 들어있다. 따라서 해당 레지스터로부터 Page Directory의 base 주소와 가상주소의 10bit에 들어있는 offset을 더하여 Page Table base 주소를 계산하게 된다.
그다음 page table base 주소와 나머지 10bit에 존재하는 오프셋을 더하여 페이지 프레임 주소를 얻게 된다. 최종적으로 가상 주소의 하위 12bit에 들어있는 오프셋을 더하여 실제 페이지 프레임에 들어있는 특정 물리 주소를 얻을 수 있다.

64bit 시스템에서는 다음과 같이 4단계 페이징도 존재한다. 하지만 이렇게 여러 레벨의 페이징 구조를 이루게 되면 더 많은 접근 횟수가 발생하므로 속도가 느려진다
2. Hashed Page Table
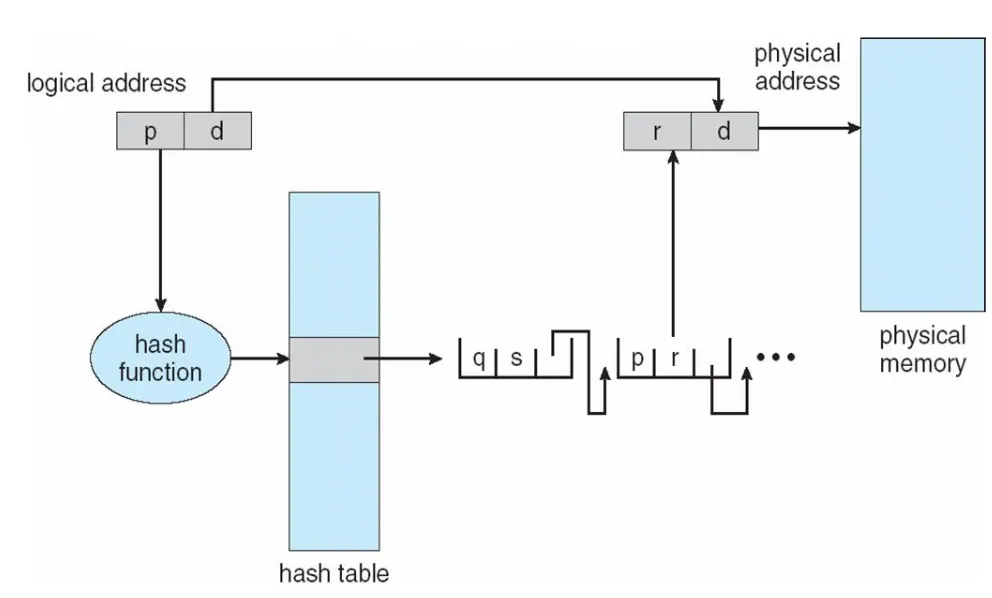
해시 페이지 테이블은 VPN(Virtual Address Page Number)를 해싱 함수를 통해 해시화한다. 그다음 해시 테이블에 존재하는 엔트리를 참조하여 물리주소를 찾는 방식이다.
해시 테이블 엔트리는 linked-list 형태로 구성되어있으며 총 3개의 필드로 구성된다
•
가상 페이지 번호
•
매핑되는 페이지 프레임 번호
•
다음 리스트 포인터
해싱된 VPN를 순회하여 일치하는 가상 페이지 번호를 찾는다. 일치하는 페이지 번호가 있다면 그에 매핑되는 페이지 프레임 번호와 offset을 더하여 물리 주소를 계산하게 된다. 해싱 페이지 테이블 구조의 장점은 속도에 있다
해시 테이블의 사이즈는 고정이기 때문에 이를 검색하는데 상수의 시간 즉 O(1) 이 걸린다. 그다음 리스트를 순회하며 일치하는 가상 페이지를 검색하는데는 O(n)시간이 걸리기 때문에 총 O(n)의 시간으로 가상주로를 물리주소로 변환 시킬 수 있다.
3. Inverted Page Table
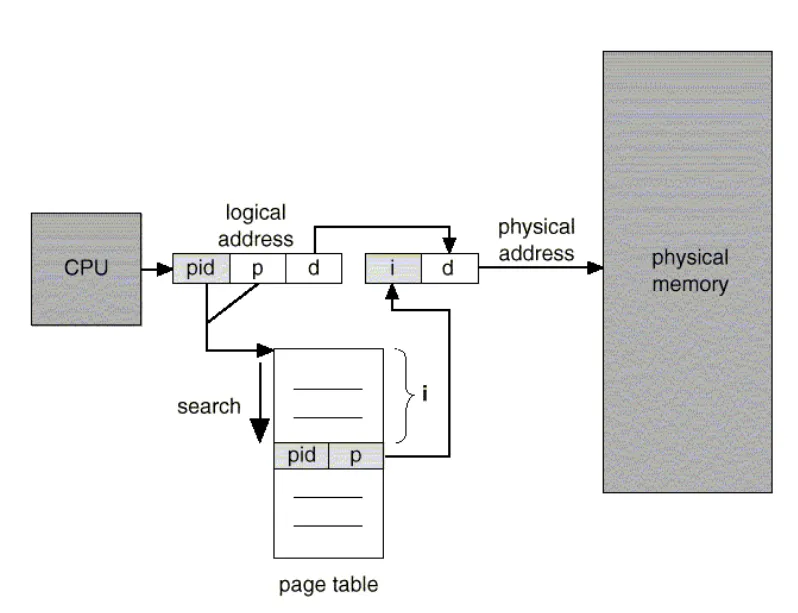
기존 페이지 테이블은 각 프로세스마다 모두 존재했다. 하지만 역 페이지 테이블은 프로세스 별 페이지 테이블이 아닌 시스템에 하나만의 페이지 테이블을 두는 방식이다.
가상 주소에는 pid를 포함하고 있기 때문에 하나의 테이블 만이 사용가능하다. 하지만 pid를 검색하는 시간이 추가됨에 따라 속도가 느려질 수 있다는 단점이 존재한다.
이렇게 다양한 페이지 타입이 존재하는데 이러한 메모리를 관리하기 위한 메커니즘은 아키텍쳐에 의존적이다. 위에서 설명한 개념들은 대부분 intel x86에 기반을 둔 메커니즘이다.
paged segmentation
페이징에 대해서 조금 디테일하게 알아봤다. 여기서 추가적으로 세그멘테이션 기법에 대해서도 알아보자. 페이징은 4kb의 고정 사이즈로 메모리 공간을 쪼개서 사용하는 기법이라고 설명하였다. 하지만 사용자에 의해서 결정되는 메모리들은 어떻게 될까?
malloc같이 컴파일 시에 할당되는 메모리들은 고정으로 사이즈를 미리 할당해 둘 수 없다. 따라서 가변 길이의 메모리 공간을 관리 할 수 있는 세그먼테이션 기법과 페이징 기법을 혼용하여 사용하게 된다.
다음의 그림은 세그먼테이션과 페이징 기법을 같이 사용하여 가상주소를 물리주소로 변형하는 로직이다. (x86 linux에서는 세그먼테이션 활용 안함. 페이징을 주로 이용)
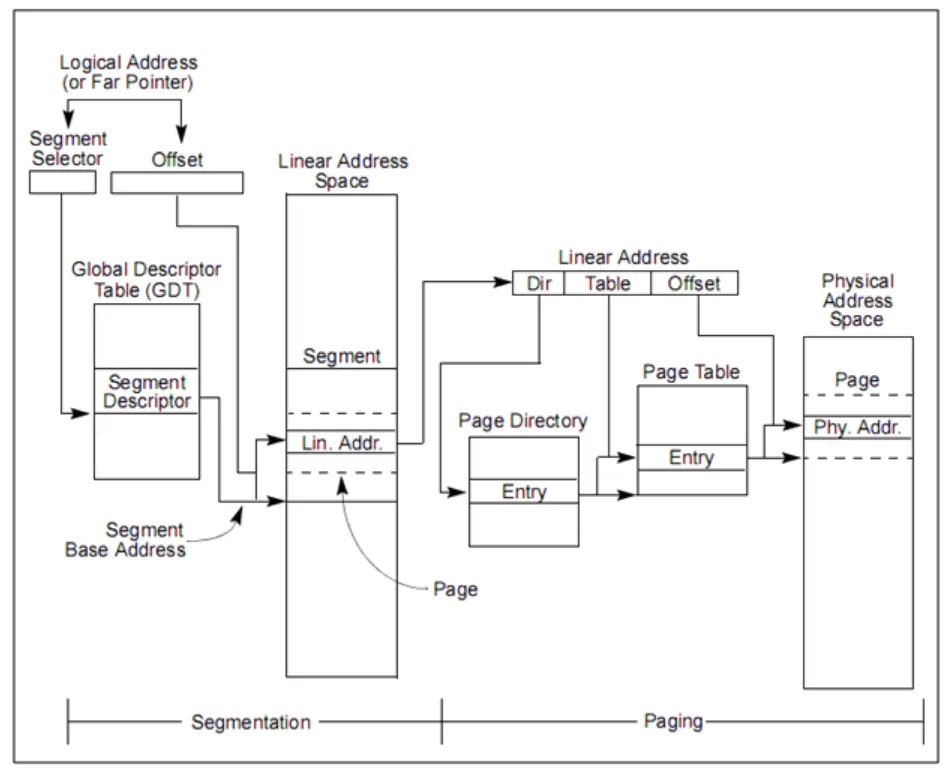
세그먼테이션 + 페이징
세그먼트란 우리가 일반적으로 볼 수 있는 다음과 같은 덩어리 들을 의미한다

세그먼테이션 기법은 실행할 프로그램을 세그먼트로 나누어 메모리에 적재한다. 세그먼트란 위 사진처럼 논리적인 단위로서 일정한 크기의 페이지와는 달리 가변적인 크기를 갖기 때문에 페이징 기법과는 달리 메모리가 페이지프레임으로 나눠지지 않는다.
그럼 앞 부분의 세그먼테이션 로직을 먼저 살펴보자
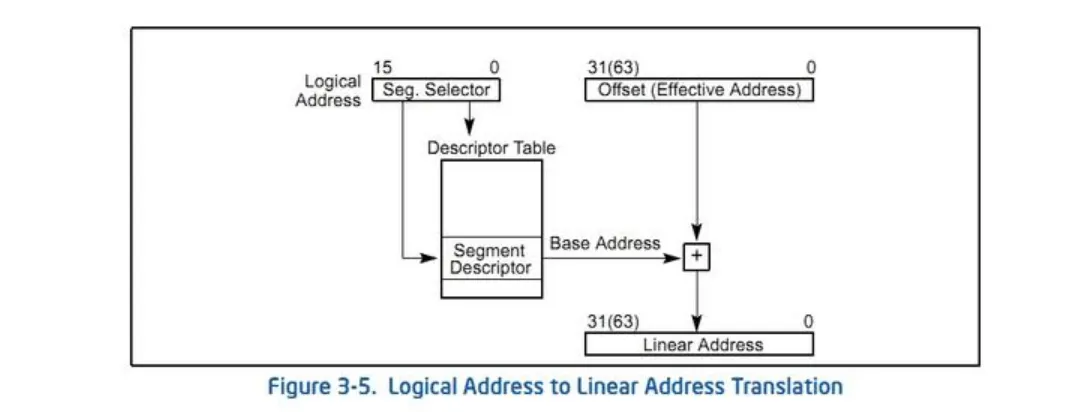
16ibt의 segment selector 를 이용하여 Descriptor Table(GDT) 에서 원하는 Segment Descriptor를 선택한다. Segment Descriptor 에는 해당 세그먼트에 대한 정보가 들어있으며 이를 통해 선형주소의 base 주소를 얻는다.
그다음 base주소와 offset을 더하여 VA⇒Linear Address로 변환한다
Segment Selector란?
Segment Selector는 세그먼트 레지스터이다. 흔히 말하는 CS, DS, SS, ES, FG, GS 등이 모두 세그먼트 셀렉터이다. 세그먼트 레지스터를 이용하여 GDT에서 세그먼트 디스크립터를 선택하기 때문에 세그먼트 셀렉터라고 부른다.
info reg 명령어를 통해 해당 프로세스에서 사용되는 세그먼트 레지스터를 알 수 있다

세그먼트 셀렉터의 구조는 다음과 같다
•
13bit : 테이블을 가리키는 인덱스
•
TI : 해당 셀렉터가 가리키는 세그먼트 디스크립터가 전역 테이블인지 지역 테이블인지를 나타냄(GDT or LDT)
•
PRL : 셀렉터가 가리키는 세그먼트의 권한을 나타냄
Segment Descriptor란?

요약하자면 세그먼트의 위치, 접근 권한, 상태 등에 대한 정보를 가지고 있는 구조체이다. 세그먼트 디스크립터의 구조는 다음과 같다

•
Base Address : 세그먼트의 시작주소.
•
등 등
결국 가상주소 ⇒ 물리 주소로 변환되는 페이징과는 달리, 세그먼테이션 + 페이징 기법은 가상주소 ⇒ 선형주소 ⇒ 물리 주소 형태로 변환된다.
추가적으로 세그멘테이션 + 페이징 기법은 보호모드→ IA-32 모드에서 사용되는 기법들이며 OS의 운영 모드에 따라서 또 다른 가상 메모리 관리 기법들이 적용된다

window OS 같은 경우 위처럼 세그먼테이션 + 페이징 을 사용하여 메모리 관리를 한다. 하지만 Linux OS 는 페이징 기법만을 사용하여 메모리 관리를 진행한다.
완벽하게 세그먼테이션을 사용하지 않는 것은 아니다. 기존 세그먼테이션 + 페이징 의 관리를 MMU가 직접 처리해주는 것이 아닌, SW적으로 OS가 어느 페이지가 코드 세그먼트인지, 데이터세그먼트 인지를 관리해주고 실제 주소변환 단계에서는 단순히 paging 기법만을 사용한다고 생각하면 된다.
리눅스는 그럼 왜 페이징 기법만을 사용할까?
운영체제는 크게 두가지 형태로 구분 된다
1.
머신에 의존된 코드
2.
머신에 독립된 코드
여기서 말하는 머신이라고 하는 것은 3가지 차이점을 가진다
1.
CPU 아키텍쳐 차이
2.
전체 시스템 차이
3.
I/O device 차이
OS를 개발하게 되면 위 3가지 차이와 무관하게 작성할 수 있는 코드를 머신에 독립된 코드 라고 한다. 이렇게 독립적인 코드를 만들어야 이식성이 높아지면서 다른 하드웨어에서도 동일한 OS를 동작시킬 수 있다
하지만 위에서 말한 3가지 머신의 차이점 때문에 필연적으로 머신에 의존적인 코드가 존재할 수 밖에 없다. 문맥 전환, 프로세스 생성, I/O 관리, 메모리 관리 등의 코드들은 특히나 CPU 아키텍처에 종속적이다.
linux - intel 환경에서는 기본적으로 paged segmentaion을 지원한다. 하지만 임베디드 환경에 주로 사용되는 linux-arm 아키텍처에서는 segmentation 구조를 지원하지 않는다.
결국 리눅스 개발자들은 이식성을 높이기 위해 페이징 기법으로 메모리 관리를 구현하고 세그먼테이션에 해당하는 부분은 OS가 S/W적으로 처리하게끔 한다
따라서 리눅스에서는 위 가상주소와 선형주소가 동일한것이라고 생각하면 된다. 각 세그먼트들이 포함되어 있는 페이지들의 주소를 OS가 처리하면서 실제 페이징이 이뤄진다.
정리
cpu 아키텍쳐에 따라서 관리되는 메모리 기법들이 너무 다르다. 이번에는 인텔 위주로 설명했지만 추후 arm을 대상으로 하여 다시 공부해 볼 예정이다.
오우 너무 어렵고
참고자료

