

저번 시간에 이어서 유닉스 파일 시스템에 대해서 설명할것이다. 모든 디렉토리 역시 파일로 간주되기 때문에 inode가 존재한다.
1. File open
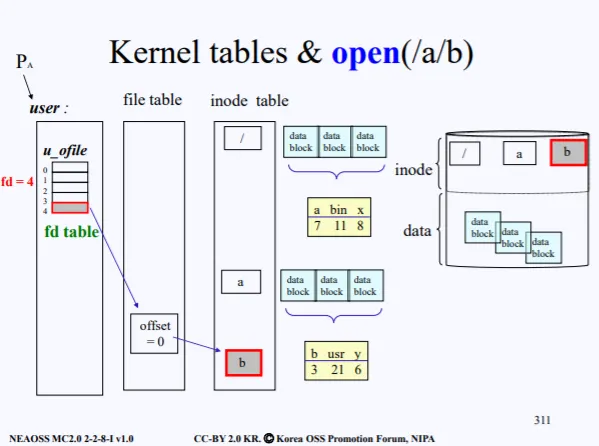
컴퓨터가 부팅이 되면 제일 먼저 커널 프로그램이 올라오면서 각종 하드웨어 Data Structure 역시 올라온다. FCB가 올라오면서 가장 앞에 존재하는 inode 0 이 올라온다. 이는 root directory file 로 ' / ' 루트이다.
이제 유저가 /a/b 파일을 open 해달라고 system call을 요청햇다. 그럼 우선 /a/b 의 inode를 inode table로 가져와야한다. 현재 우리가 아는건 inode 0 즉 / 밖에 모르므로 해당 inode의 포인터를 따라가서 가져와야한다.
inode 0 에 연결된 포인터에는 해당 / 의 content가 들어있다. 이 content에는 실제 root directory file에 들어있는 data들이 존재하는데 현재는 a, bin, x 3개의 file이 들어있고 이 파일들은 각각 i-number가 존재한다.
이 i-number로 디스크에 들어있는 inode - i 를 찾고 그걸 inode-table로 가져온다. a의 경우 i-number가 7이기 때문에, 디스크에서 inode-7를 찾아 가져온다.
이제 inode table에는 / 와 a inode가 들어있다. 동일한 방식으로 a inode를 따라가서 해당 content를 보면 b, usr, y 3개의 directory file들이 들어있다. b의 i-number는 3이므로 디스크에서 inode-3을 찾아서 가져온다.
그럼이제 /a/b/ 를 open하기 위한 준비가 끝났다. file 구조체에서 offset을 0으로 해서 생성한뒤, inode b를 가리키게 한다. 이제 마지막으로 실제 프로세스의 PCB에 존재하는 open한 파일들을 관리하는 배열 (u_ofile[])에 생성한 file→offset의 주소를 넣는다.
결국 user에게 최종적으로 return 되는 fd는 u_ofile[]의 인덱스이다. 따라서 우리가 read(4,buf,size) 이런식으로 파일에다가 쓰게 되는것이다.
FD table에는 다음과 같은 특징이 있다

•
PCB에 존재
•
각 프로세스마다 open한 파일들의 정보가 담긴다
•
open(path_name) 으로 call하면, 커널이 해당 파일을 open한뒤, fd를 리턴해준다
•
0,1,2는 에약된 fd 즉 표준 입출력, 에러 를 위한 fd로, 고정으로 세팅되어있다. 따라서 유저가 open했을때는 fd=3 부터 할당된다
이제 open이 되었다. open이 된 상태에서 read나 write가 어떻게 진행되는 살펴보자.
2. Accessing File with fd
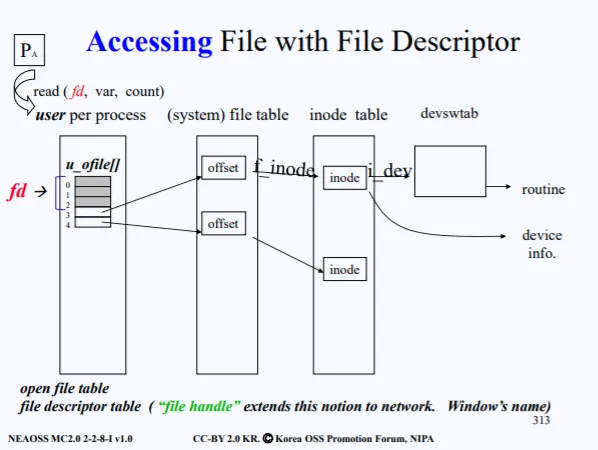
read(4,var,count) 이렇게 요청을 했으면, 우선 유저 프로세스의 PCB에 들어있는 fd_table을 순회한다. 인덱스 4를 찾았으면, fd_table[4]에 들어있는 offset→inode를 확인한다. 실제 inode를 통해 원하는 데이터를 얻을수 있다.
그다음 inode에는 디바이스 정보도 들어있으므로 만약 disk라면 disk의 핸들러 중 read를 찾고 실제 루틴이 시행된다. 이는 전에 말한 device switch table이다.
file handle은 fd 앞에다가 hostname과 pid를 붙인것이다
결국 정리하면 open시에만 file path name을 주고 read, write, close는 전부 open으로 얻은 fd로만 관리한다. 왜 open을 제외하고 나머지는 다 fd로만 관리할까?
open시에는 어쩔수 없이 path name으로 파일 정보를 세팅해야하지만, read시에도 동일하게 path name을 주게 된다면, open 시에 수행됬던 로직들을 또 다시 수행하게 될것이고, 디스크에 쓸때없이 많이 access하는 부하가 생기게 된다.
fd로만 접근하면, file structe, indoe structure, device switch 3번만 메모리에 access하게 원하는 정보를 다 얻어올수 있기 때문에 더 효율적이다.
3. Balanced tree
내가 만약 kt에 다니는데, kt에 가입된 고객들에 대한 데이터베이스를 만들고 싶다고 해보자. 가입자는 1000만명이고, 매우 큰 용량이므로 어떻게 처리를 할지가 매우 중요하다.

고객 정보를 디스크의 섹터들에다가 저장시켜야한다. 현재 내가 가진 디스크의 용량은 10GB이고 섹터의 사이즈는 1K이다. 그럼 내가 현재 사용할수 있는 섹터는 다음과 같이 계산될수 있다.
•
10,000,000,000 / 1000 = 10,000,000 sectors
그럼 현재 천만개의 섹터를 사용할수 있고 각 섹터들을 가리키는 포인터를 만드려면 몇 비트가 필요할까? 이것도 한번 계산해 보자.
만약 1000개의 섹터를 가리키는 포인터를 만드려면 2^10 개의 bit이 필요하다. 10개 의 섹터는 2^4 개의 bit이 필요하다. 따라서 천만개의 섹터를 관리하기 위한 포인터는 적어도 24bit이 필요하다는 소리다. 이를 일단 염두해 두고 다음 설명을 이어가겠다.
각 섹터들이 가지고 있는 주소를 분명 어디에 저장해야한다. 이 저장위치도 섹터이다. 따라서 천만 고객의 정보를 저장하기 위해서는 수많은 섹터들이 필요할 것이다.
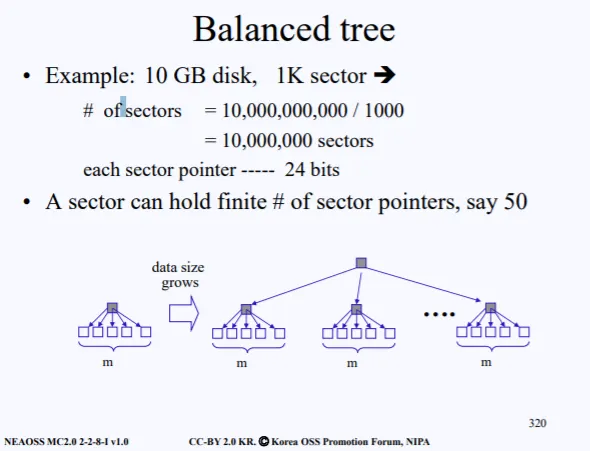
섹터들을 50개의 단위로 묶는다 치면, 50개를 관리하기 위한 또 섹터가 필요하고, 이러한 관리 섹터도 많아지면 이 관리 섹터를 관리하기 위한 섹터도 또 필요하다. 그게 바로 위 그림에서 표현된다.
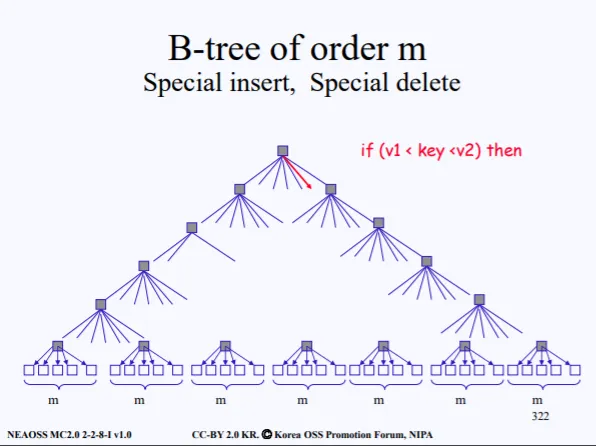
결국 위 그림처럼 될것이다. 50개씩 묶고 그걸 관리하는 섹터가 또 많아져서 그걸 관리.. 관리.. 관리..
수많은 레벨이 생기고 결국 트리 형태로 생길것이다. 일반적으로 이진 트리인 경우 양쪽의 depth가 서로 다를수있지만 섹터가 트리 형태로 관리가 되는건 양쪽의 depth가 모두 동일하다.
따라서 이러한 Tree는 Balenced Tree(B-Tree) 하고 부른다. 결국 우리는 용량이 큰 데이터를 저장하고, 이를 이용할때는 제일 최상위에 존재하는 하나의 inode만 알고 있으면 된다. 루트 inode를 알면, 여기에 연결되어있는 자식 노드에 접근해서 데이터를 얻어오면 되기 때문이다.
제일 최상위에 존재하는 노드를 마스터 인덱스라고도 부른다
4. C functions for file

위에서 우리는 File Desciptor에 대해서 공부를 하였다. 헌데 생각해보면 우리가 C 프로그램시에 파일과 관련된 open을 하기 위해서 fd가 아니라 대부분 File* 구조체를 이용했을것이다. 이는 fd와 뭐가 다를까?

file과 관련된 시스템 콜은 다음과 같다
•
create, open : 파일 열기
•
close : 파일 닫기
•
lseek : 파일 오프셋 변경
•
stat : inode 정보 보기
•
read, write
이것들 이외에는 전부다 라이브러리 function인데 결국 라이브러리 함수들은 read나 write로 입력 혹은 출력을 진행한다. wrapper 임 ㅋ
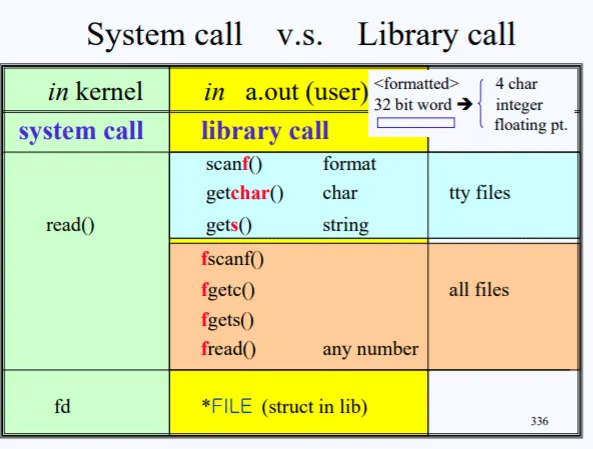
라이브러리 call과 시스템 call의 차이를 한번도 보고가자. 실제 데이터를 읽는 건 시스템 콜에서는 read밖에 없고, 라이브러리에는 아주 많다. 라이브러리 함수들의 공통된 특징은 맨 앞에 f가 안붙어있으면 전부다 표준 입출력에 사용되는 함수이다. (키보드 or 스크린) f가 있으면 전부 파일과 관련된 함수이다.
이러한 라이브러리 콜들은 전부 결국 커널에 들어와서 read() 시스템 콜을 호출하게 된다. 이처럼 라이브러리 함수 내에서 FILE* 을 사용하면 결국 커널 내부에서 fd에 관련된 처리가 된다. 좀더 자세히 설명해보면
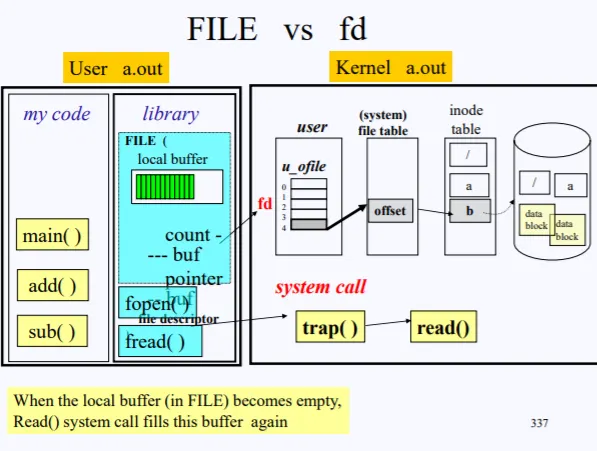
내가 짠 코드에서 FILE* aa=fopen() 이렇게 코드가 수행되면, 실제 라이브러이에 들어있는 fopen이 호출되면서 foepn은 결국 실제 open 시스템 콜을 불르게 될것이다. open이 완료되면, fd가 FILE 구조체의 pointer에 저장이 된다. 따라서 해당 포인터로 fd_table에 접근할수 있고, 유저가 최종적으로 받게되는건 FILE 구조체 포인터의 주소이다.

정리를 해보자.
1.
내 코드에서 fopen('/a/b/c') 를 호출함
2.
fopen에서 실제 '/a/b/c' 를 위한 FILE 구조체를 만듦
3.
라이브러리에서 실제 open system call을 함
4.
커널에서 파일 관련 로직이 수행되고 fd가 나옴
5.
fd를 생성한 FIEL 구조체에 저장함
6.
유저는 FILE 구조체 주소를 얻고 이를 이용해 파일에 접근함
그럼 파일을 이용하는데 눈에 보이는 open 말고도, 실제 리눅스는 모든걸 파일로 처리한다고 했기때문에 그 부분이 어디인지 살펴보자.

getchar() 함수는 표준입력으로부터 한 바이트를 가져오는 함수이다. 실제 코드를 보면 내부에 노락색 data 구조체가 존재한다. 해당 구조체에는 버퍼가 존재하고, 그 버퍼의 주소, 마지막으로 현재 몇바이트를 읽었는지의 정보가 n에 담겨져 있다.
n==0 이라는 의미는, 버퍼가 비어있다는 의미로 보면 된다. 버퍼가 비어있으면 read syscall을 호출하는데, 여기서 fd=0 로 인자를 주게 된다. 이게 바로 표준 입력 즉 키보드로부터 입력을 받는다는 의미이고 키보드의 fd가 0으로 설정되어있다.
버퍼가 비어있지 않으면, 해당 버퍼의 주소를 리턴한다.
결국 이렇게 정리하지만 FILE* 을 이용해서 실제 코드를 짤때, 저 구조체 내부에 fd가 들어가있고, 우리는 단지 보지 못할뿐이다.
5. FIie system in Disk
이제 여태 설명한 FIle System 에 대한 총정리를 한번 해보자. File system은 각 data 섹터들을 관리하기 위한 inode, 실제 content가 담긴 data-block이 존재한다고 했다. 또한 inode들은 파일들의 사이즈가 달라도 동일한 마스터 인덱스 inode를 가지기 때문에 inode 사이즈는 동일하다고 했다.

그럼 이러한 inode, data 의 관리가 또 필요하기 때문에 super block 이라는 영역이 존재한다. 결국 디스크에는 superblock, inode, data 여역으로 구분되어져 있다.
superblock의 주역할은 inode나 data 의 섹터들이 사용후 delete 되었을때 이를 관리하기 위함이 제일 크다. 따라서 inode hole sector, data hole sector 를 가리키는 포인터들이 존재한다.
추가적으로 global 정보가 들어있는데, 여기에는 현재 inode, data block의 사이즈가 몇인지, 접근권한은 뭔지 등에 대한 정보가 들어가 있다.
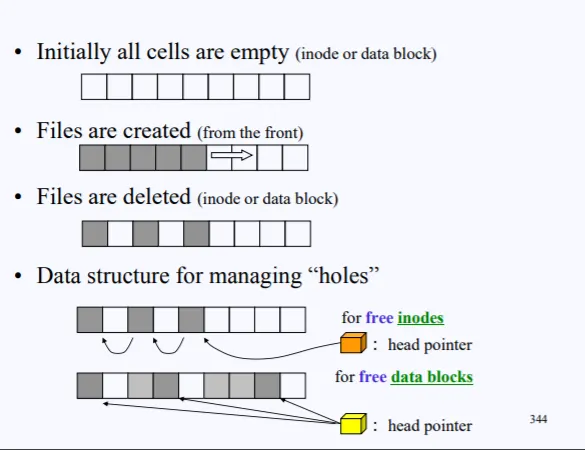
초기 비어있는 섹터들이 비어있다고 가정해보자. 해당 섹터들을 inode든 data block이든 둘중 하나일 것이다. file이 생성되면 섹터들이 채워질것이고, 특정 셀이 delete가 되면 hole이 생긴다.
이러한 hole들을 관리하기 위해 free_inodes를 위한 포인터 하나와, free_data_blocks를 위한 포인터가 필요하고 이 정보가 super block에 들어가있다.
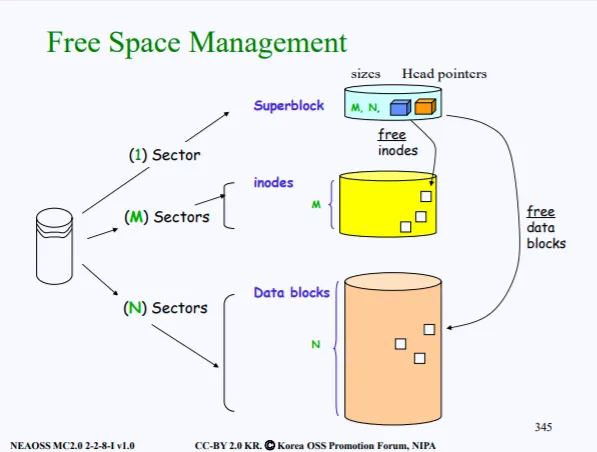
위 그림이 바로 super block에 들어가 있는 free_inodes, fre_datablock 포인터를 나타낸다. M과 N은 각각 indoe와 data block의 사이즈가 들어있다.
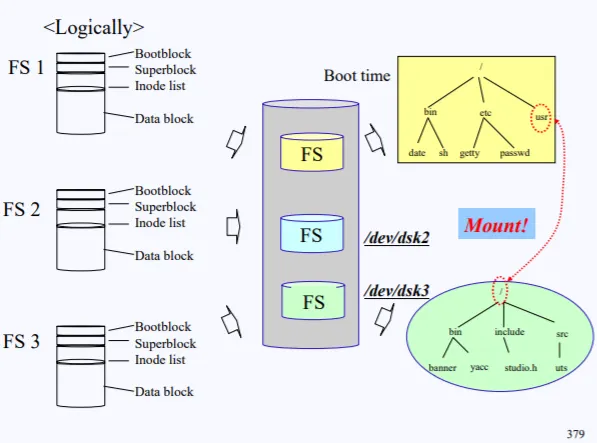
Bootblock은 부팅시에 로딩되기 위해 필요한 정보가 저장되어있음
이렇게 유닉스의 FIie System은 Bootblock, Superblock, Inode, Data block 4가지로 구성되어있다. 이러한 FIie System 은 disk에만 존재한는게 아니라 USB 같은곳에도 들어있다. 또한 하드가 2개면 2개에 전부다 들어있다.
그럼 이러한 여러개의 FS중 어느게 root가 되어야 하느냐가 문제이다. 윈도우에서는 만약 위의 사진처럼 3개의 FS라면 이를 C드라이브, D드랑브, E드라이브 이렇게 구분하고 유저는 각각의 FS에 접근할수 있다.
하지만 유닉스나 리눅스에서는 여러 FS중에서 하나를 무조건 root로 해 부팅을 해야한다. 만약 FS_1을 root로 부팅을 했다면, 부팅시에 화면에 FS_1가 루트로 세팅되어 올라오게된다.
그러면 FS_2나 FS_3은 어떻게 접근해야할까?. 이는 마운트를 이용하면 된다. 현재 FS_1의 하위 폴더중 /tmp 에다가 FS_2의 root를 마운트 시키면 FS_2의 root는 FS_1의 가지중 하나가 되고, /tmp는 실제 FS_2의 root로 되버린다.
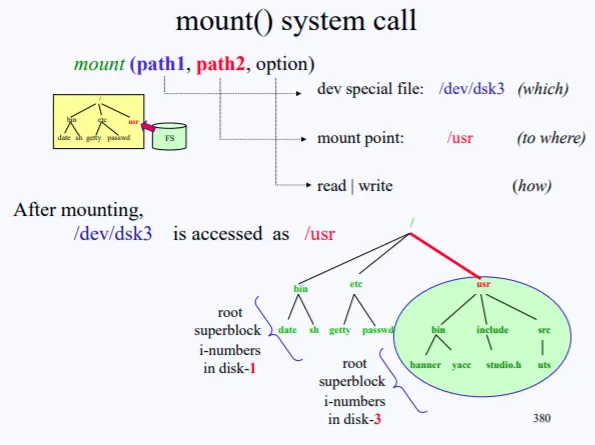
이렇게 현재 disk-1의 FS가 부팅시에 올라와있고, /usr/에 disk-3의 FS를 마운트 시키면 /usr/를 통해 /dev/dsk3의 FS에 접근할수 있다.
6. 정리
여기까지 Unix의 File System에 대해서 알아보았다. 바로 Linux Files System을 공부하지 않은건 리눅스도 결국 유닉스로부터 파생되었기 때문에 유닉스의 FS를 알아야지만 더욱 이해가 빠르다고 생각한다. 오우 넘나 재밌고

