1. Memory Allocator
리눅스에서는 4kb 사이즈의 페이지 단위로 메모리가 관리된다. (물론 x86 기준)
따라서 만약 내가 malloc 같은 함수를 이용하여 400바이트의 공간을 할당 요청 해도 리눅스 커널 내부에선 페이지 단위로 할당을 해준다. 물론 이 과정 가운데 매우 복잡한 로직이 존재하며 유저가 메모리를 할당 요청할 때 마다 페이지 단위로 할당해주지 않는다.
ptmalloc 같은 유저단의 메모리 할당자는 방금 말한 복잡한 로직을 관리한다. 내부에서 미리 충분히 큰 용량의 페이지들을 미리 할당받고 그걸 청크 단위로 쪼개서 할당 및 사용 후 반환된 메모리를 free list로 묶어 재할당 하는 등의 로직처럼 말이다.
이와 같이 커널 내부에서도 메모리의 할당을 관리하는 시스템이 존재하고 그 중 하나가 버디 시스템이다. 결국 버디 시스템도 메모리를 할당 할 때 생기는 단편화 같은 문제들을 해결하기 위한 다양한 방법중 하나라고 생각하면 된다. 정리를 해보자
아~~~~무 것도 없는 상태라고 가정해보자. 사용자는 메모리를 할당해줘! 라고 요청을 하면 사실 커널이 사용가능한 페이지를 찾고 그 부분을 써라! 하고 반환할 것이다.
매번 이렇게 유저가 요청할때마다 커널에 요청하고 커널이 일하고 ... 비효율적이다. 따라서 유저단에서 매니저를 하나 고용하여 메모리를 처리할 수 있게 일을 주었다
제임스 아저씨가 메모리 할당을 관리하다라고 생각하자. 제임스는 머리가 좋다. 따라서 처음 유저가 요청을 했을 때 미리 충분한 양의 사이즈를 할당받아오고, 이를 추가로 저장하여 사용자에게 돌려준다. 그다음 유저가 또 요청을 하면 이미 받아온 공간이 있기 때문에 커널한테 요청하지 않아도 자기가 관리하고 있는 체계 안에서 할당 해 줄 수 있다
동일하게 유저들만이 메모리 할당 요청을 하는게 아니라 커널도 내부에서 메모리를 할당받고 그러는 경우가 있을 것이다. 따라서 커널도 위 제임스 아저씨같은 메모리를 할당자를 추가로 고용하여 메모리 할당을 관리한다.
2. Buddy System
서로 다른 크기의 연속적인 페이지들을 빈번하게 할당 및 해제하는경우 외부 단편화가 생기는 단점이 있다. 남은 공간으로만 봤을 땐 충분해도 실제 커널이 요청한 사이즈를 처리할 수 있는 연속된 페이지가 없다는 의미이다.
버디 시스템은 이러한 외부 단편화를 줄이기 위해 탄생하였다. 이를 통해 연속적인 페이지 단위로 관리가 가능하다. 관리 메커니즘 부터 알아보자.
우선 버디 시스템에서는 order 단위로 페이지 할당을 요청한다. 이것은 2^n 단위로만 요청을 할 수 있음을 의미한다. 예를 들어, order 3에 해당하는 페이지를 요청하는 경우 8(2^3 )개의 연속된 페이지들를 요청하는 것이다.

현재 연속으로 free 되어 할당 가능한 페이지가 7개 있다. 하지만 버디 시스틈에서는 Order 페이지 단위로 관리를 하므로 총 할당 가능한 Order page는 Order_0 = 3, Order_1= 1, Order_2 =1 이다.
버디 시스템에서 할당 할 수 있는 최대 페이지 수는 2^(MAX_ORDER-1) 이다. 물론 아키텍쳐별로 다르다. 만약 MAX_ORDER가 11이고 페이지 단위가 4kb인 시스템의 경우, 최대 2^10 개의 연속된 페이지, 즉 4kb * 1024 = 4M 사이즈의 페이지를 할당 할 수 있다.
이전 메모리 존 설명에서 struct zone 구조체 중 free_area 구조체를 확인했었다.
struct zone {
...
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; // here! x86 MAX_ORDER = 11
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
...
} ____cacheline_internodealigned_in_smp;
=============================================================================
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
C
복사
버디 시스템은 free 되어있는 order page들을 해당 free_area 구조체 배열로 관리한다. x86에서는 MAX_ORDER 가 11로 설정되어 있다. 해당 구조체가 free_page를 관리하는 로직은 Dynamic memory allocator 설명과 비슷하다. 이를 잘 모른다면 아래 글을 읽어보고 오자.

free_area 구조체는 연결 리스트인 free_list와 현재 Order_page에 free되어 있는 페이지들의 개수가 담긴 nr_free 필드로 구성된다.
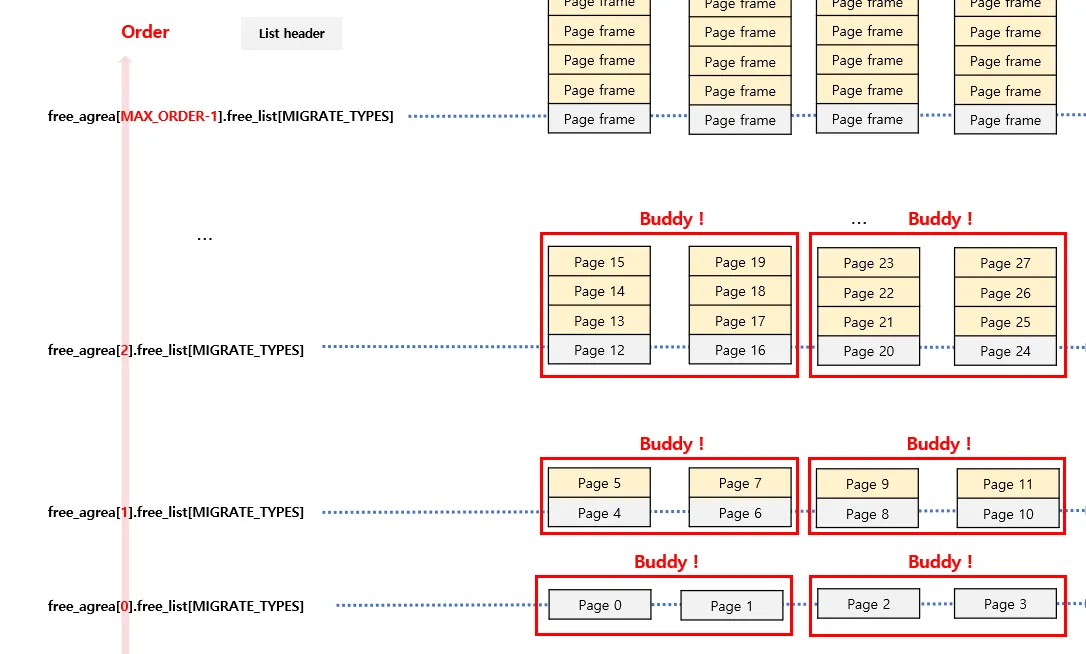
아래 그림은 각 free_area order 별 free_list에 연결되어 있는 페이지들을 나타낸 그림이다

0번째 free_area 는 2^0=1 개의 페이지들로 구성되고 2번째 free_area은 2^2 개의 페이지들로 구성된다. 회색 부분은 각 리스트의 header를 뜻한다.
만약 16kb의 메모리를 요청했다면 order 2에 속해있는 놈을 할당해준다. 요청 사이즈를 free_area의 인덱스로 변환하는 로직은 다음과 같다
(PAGE_SHIFT 은 매크로로 설정되어있음)
1. requested_size >> PAGE_SHIFT
2. 결과값의 bit 수
ex) 32bit, page size is 4kb, request size is 16kb, PAGE_SHIFT is 12
- 16000 >> 12 = 3
- 3 is 11(2진수)
- 총 2bit이므로 free_area index는 2
/arch/x86/include/asm/page_types.h
#include <linux/const.h>
#include <linux/types.h>
#include <linux/mem_encrypt.h>
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
#define PMD_PAGE_SIZE (_AC(1, UL) << PMD_SHIFT)
...
C
복사
MIGRATE_TYPES
free_list[MIGRATE_TYPES] 를 보면 MIGRATE_TYPES 라고 써져있는 부분이 있다. 요놈은 page 타입들을 구분하는 용도로 사용된다. 버디 시스템은 결국 메모리 단편화를 줄이기 위해 나왔으며 단편화를 줄이려면 조각들을 잘 병합시키거나, 잘 쪼개는 등의 기능을 지원해야하며 이렇게 되야 연속적인 페이지들을 관리 할 수 있다.
MIGRATE 영어 뜻 그대로 Order-page들을 효율적으로 왔다리 갔다리 하는 과정에서 필요한 속성 정도로 이해하면 된다. 즉 최대한 커다랗고 연속된 free 메모리를 유지하고자 하는 목적으로 버디 시스템에서 설계되었다. MIGRATE 타입은 다음과 같다
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
C
복사
https://elixir.bootlin.com/linux/v4.14.62/source/include/linux/mmzone.h#L42
타입 설명 출처 : http://jake.dothome.co.kr/zonned-allocator-alloc-pages-fastpath/
•
MIGRATE_UNMOVABLE
◦
이동과 메모리 반환이 불가능한 타입
◦
커널에서 할당한 페이지, 슬랩, I/O 버퍼, 커널 스택, 페이지 테이블 등에 사용되는 타입
•
MIGRATE_MOVABLE
◦
연속된 큰 메모리가 필요한 경우, 현재 사용되는 페이지를 이동시킬 수 있는 타입이다
◦
이동시킴으로 단편화를 막을 수 있다
◦
유저 메모리 할당 시 사용된다
•
MIGRATE_RECLAIMABLE
◦
이동은 불가능하지만 메모리 부족시 메모리 회수가 가능한 경우 사용되는 타입
◦
자주 사용은 안됌
•
MIGRATE_ISOLATE
◦
커널이 특정 범위의 사용 중인 movable 타입의 페이지들을 다른 곳으로 이동시키기 위해 잠시 요 타입으로 변경하여 관리함.
◦
해당 타입의 페이지들은 버디 시스템이 절대 사용하지 않음
•
MIGRATE_HIGHATOMIC
•
MIGRATE_CMA
따라서 실제 Order-n 으로 묶여있는 block들은 세부적으로 MIGRATE 타입 별로 구분된다
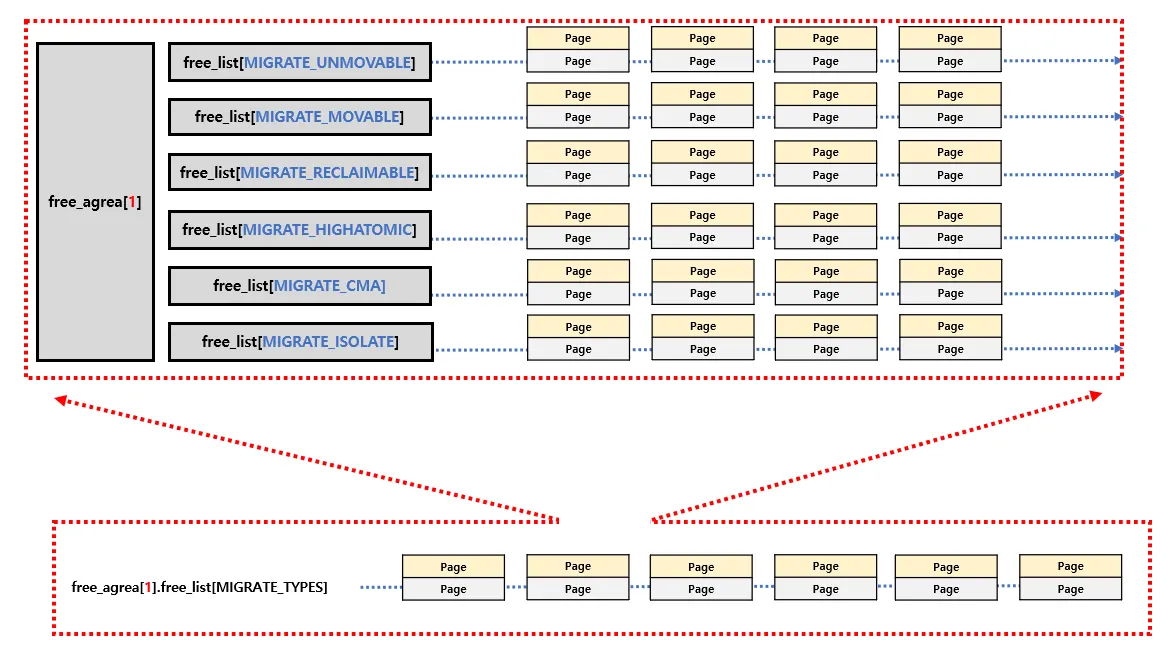
아래에 보이는 Order-1의 블럭들은 사실 그 위처럼 다양한 타입으로 한번더 분류되어 있다. 또한 각 Order-n MIGRATE 타입에서 가장 많은 덩어리들을 갖고 있는 놈이 해당 Order의 대표 타입이 된다
Page_block
버디 시스템은 Order-n 단위로 페이지들을 관리하는데 여기서 Order-n들을 free 상태든 used 상태든 상관없이 page_block 단위로 관리된다. page_block은 huge 페이지 단위에 맞춰 사용되고 만약 huge 페이지를 사용하지 않는 경우는 버디 시스템이 사용하는 최대 페이지 크기에 맞춰사용한다
/* Huge page sizes are variable */
extern unsigned int pageblock_order;
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/* Huge pages are a constant size */
#define pageblock_order HUGETLB_PAGE_ORDER
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
#else /* CONFIG_HUGETLB_PAGE */
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)
#endif /* CONFIG_HUGETLB_PAGE */
#define pageblock_nr_pages (1UL << pageblock_order)
/* Forward declaration */
C
복사
https://elixir.bootlin.com/linux/v4.14.62/source/include/linux/pageblock-flags.h#L47
즉, pabeblock 은 총 2^(MAX_ORDER-1) 사이즈 단위로 구성된다. x86 4.14 커널 기준에서는 pageblock_order 는 9로 확인된다
/ # cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 0 0 1 2 1 1 0 1 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 0 0 0 0 0 1 0 1 0 1 0
Node 0, zone DMA32, type Movable 9 5 9 7 8 8 8 9 6 4 42
Node 0, zone DMA32, type Reclaimable 0 1 0 1 1 1 1 0 0 1 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic
Node 0, zone DMA 1 7 0 0
Node 0, zone DMA32 8 108 4 0
/ #
Bash
복사
아래 그림에서 pageblock 의 구성요소를 확인 할 수 있다
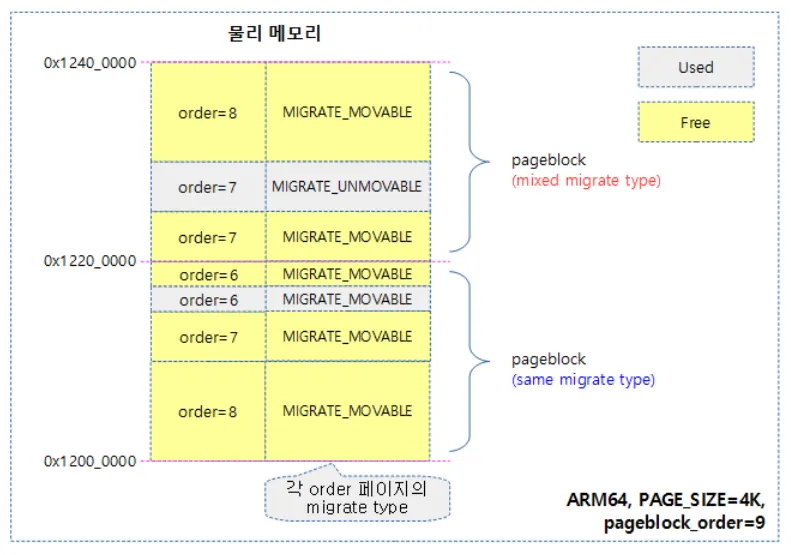
현재 pageblock_order 가 9이므로 하나의 pageblock 에는 총 512byte 사이즈의 페이지로 구성된다
•
Order-6(2^6)+Order-6(2^6)+Order-6(2^7)+Order-6(2^8) = 512(2^9)
•
Order-6(2^7)+Order-6(2^7)+Order-6(2^8) = 512(2^9)
아래의 pageblock 에는 동일한 MIGRATE 타입을 가진 Order-n로 구성되어 있고 그 위의 pageblock 은 서로 다른 MIGRATE 타입의 Order-n로 구성되어있다. order-n 들이 대표 MIGRATE 타입으로 관리되는 것 처럼 pageblock들도 각각의 MIGRATE 타입을 관리하는데,
만일 위와 같이 pageblock 내에서 여러개의 MIGRATE 타입을 사용하는 Order-n 페이지들로 구성되는 경우 동일하게 가장 많이 사용되는 타입을 대표로 선정한다.
선정된 대표 타입은 3bit로 표현되며 usemap에 추가하여 pageblock을 관리하게 된다
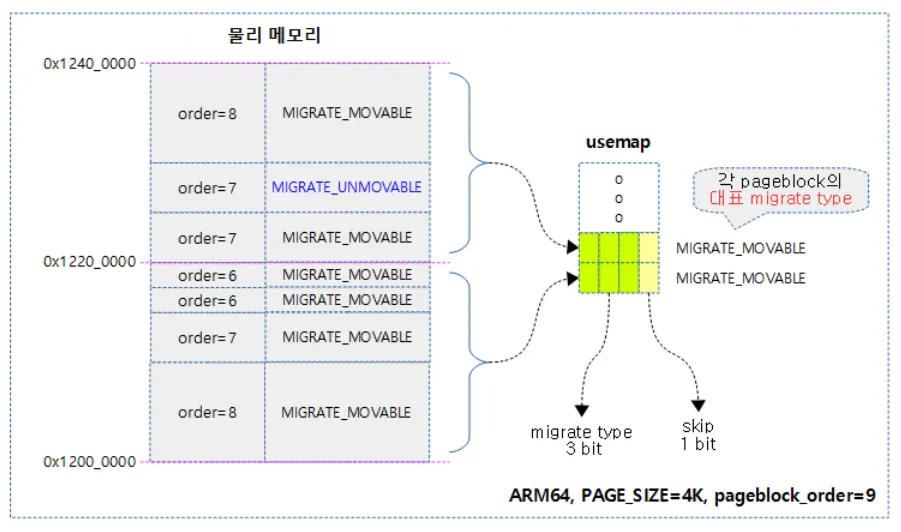
아래 pageblock 모두 동일한 타입인 MOVABLE 이므로 MOVABLE 을 표현하는 3bit를 usemap에 추가한다. 그 위 pageblock 은 서로 다른 타입의 Order-n이기 때문에 3개의 타입중 많이 사용된 MOABLE 타입을 usemap에 추가한다.
따라서 만약 메모리 할당 요청이 오면 usemap을 참고하여 현재 요청한 페이지의 타입과 동일한 pageblock을 찾고, 그 안에서 알맞은 사이즈의 Order-n 리스트를 뒤져서 할당해 준다.
결국 버디 시스템에서는 이렇게 최대한 단펴화를 줄이기 위하여 migrate 타입 같은걸 또 이용한다
case1 ) Memory Alloc
그럼 이제 메모리 할당시에 어떻게 되는지 쉽게 이해해보자. 현재 52Kb 사이즈의 메모리가 존재하며 free_list에는 다음과 같이 되어있는 상태에서 8kb의 공간을 요청했다고 가정하자
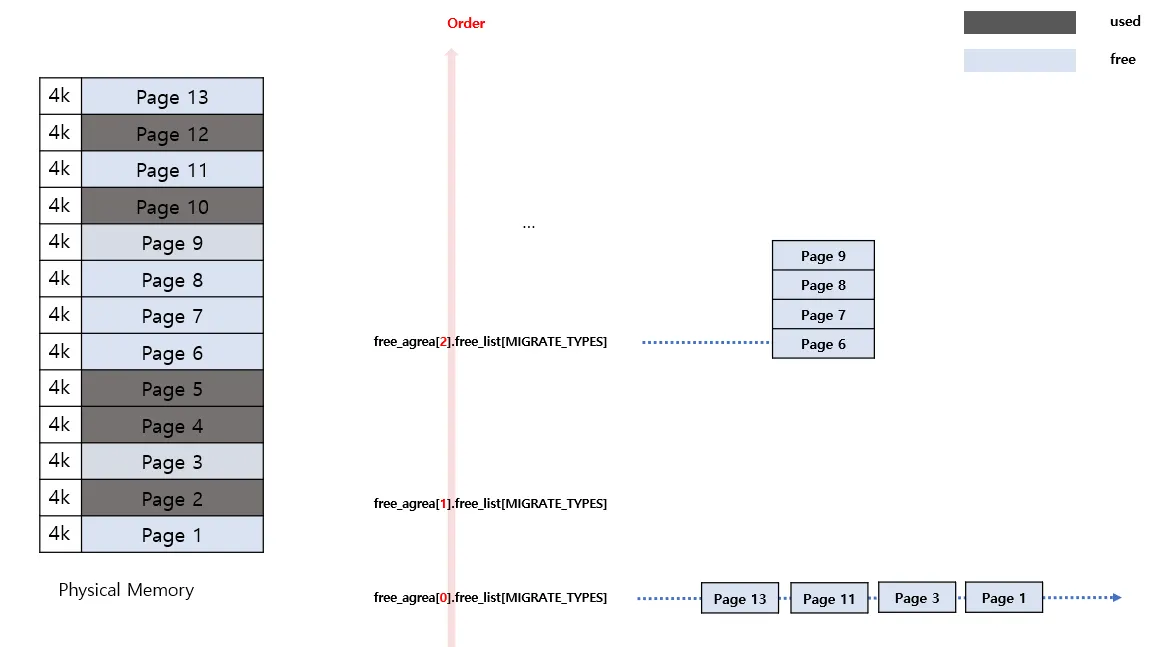
•
8kb >> 12 의 결과는 1이고 bit수가 1개이기때문에 Order-1 page를 찾아간다
•
현재 order-1에는 사용가능한 놈이 없다. 따라서 상위 order-2에서 찾는다
•
현재 order-2에는 1개가 존재한다.
•
저놈에는 총 page6 ~ page9 의 연속된 4개의 페이지가 있으므로 page6,7를 할당한다

•
order-2에서 절반을 쪼개어 할당을 해줬기 때문에 나머지 절반을 처리해 줘야한다.
•
Order-2 에 들어있는 쪼개진 놈은 더이상 Order-2 사이가 아니므로 하위로 내린다
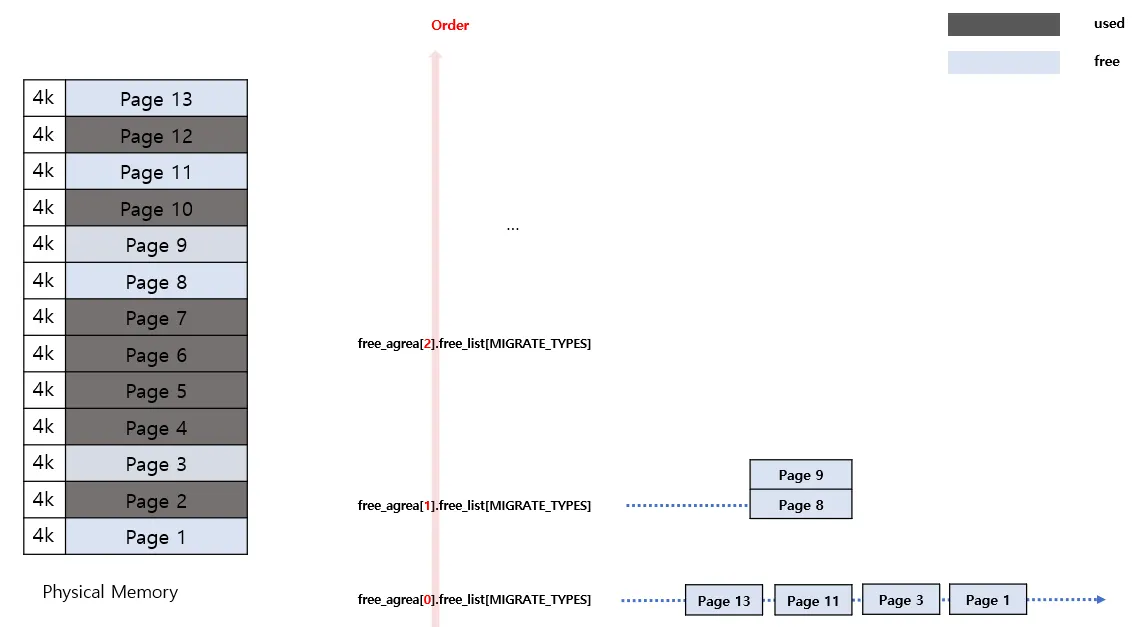
•
최종적으로 위와같이 free_list들이 조정된다
case 2) Memory 해제
자 이상태에서 이번엔 page2의 free 요청이 들어왔다.

여기서 잠깐 Buddy 의 원론적인 개념을 확인해보자. Buddy의 사전적 의미는 동료 라는 의미이다. 동료라는 의미를 페이지 프레임에 적용시켜보자.
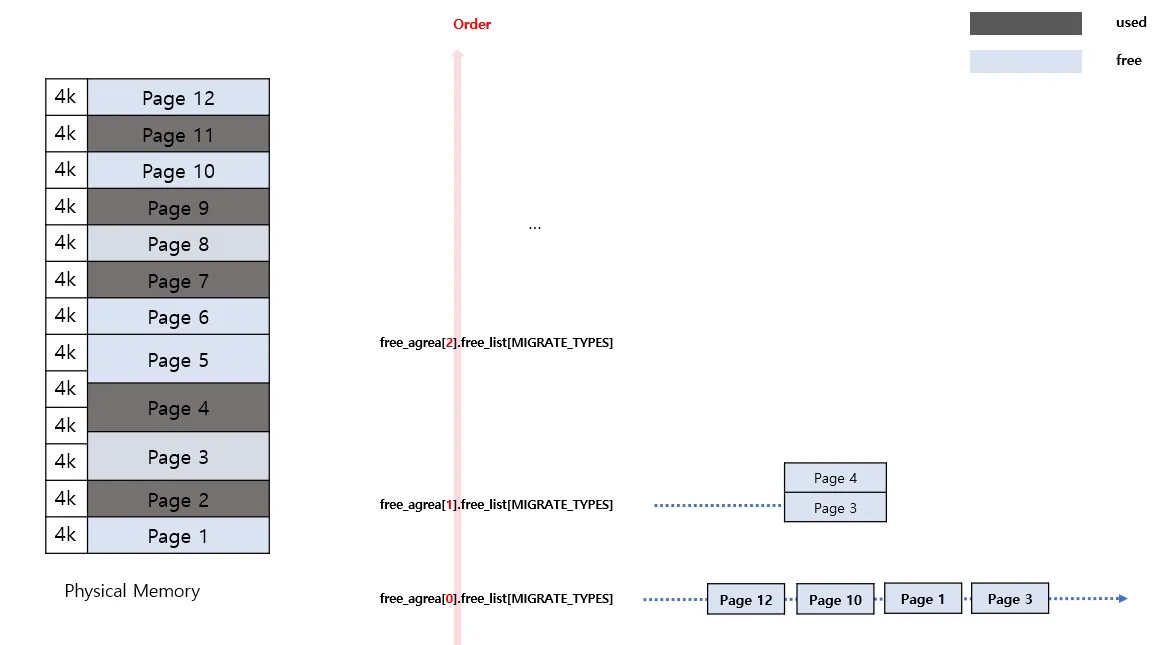
buddy 시스템에서는 order-n이 하나의 단위라고 했다.
그럼 다음과 Buddy를 다음과 같이 묶을 수 있다. Order-0 기준 버디는 각각 [0,1] [2,3] 이고, Order-1 기준 버디는 각각 [ (4,5),(6,7) ] 과 [ (8,9),(10,11) ] 이다.
그럼 다시 돌아가서
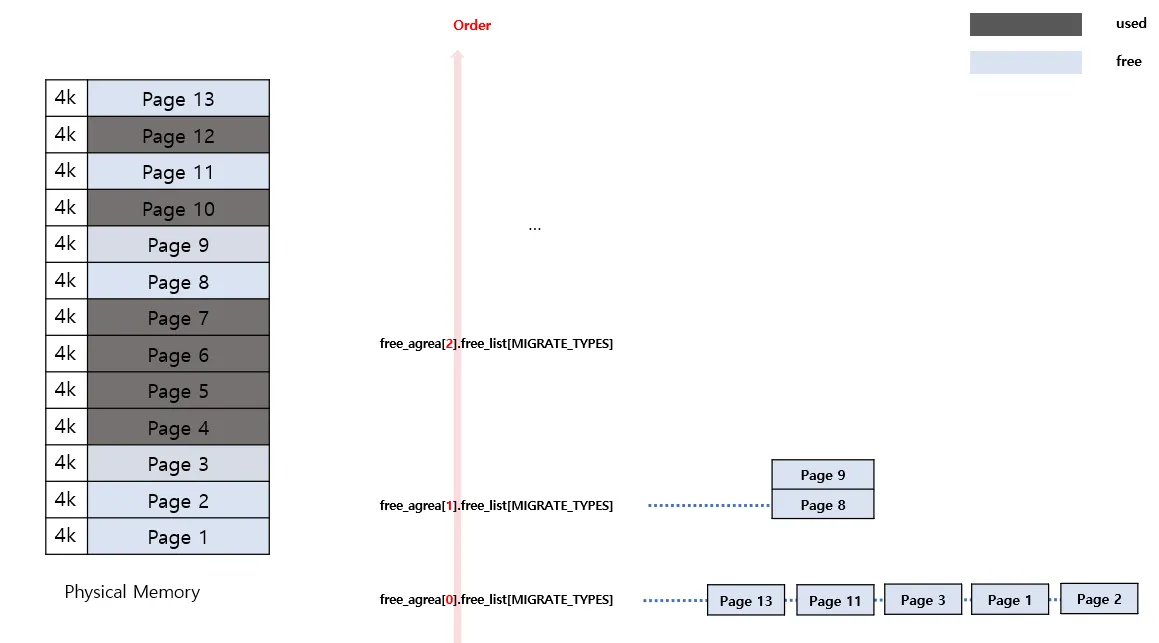
Buddy란 개념을 인식하면서 진행해보자. 현재 Page2은 Order-0 단위이므로 free 될때에 우선 자신의 Buddy를 확인한다. Order-0 에서의 Buddy 묶음은 [1,2] [3,4] ... 이므로 page1의 상태를 확인한다. Page1은 현재 사용중이므로 Page2는 그냥 free_list에 업데이트된다
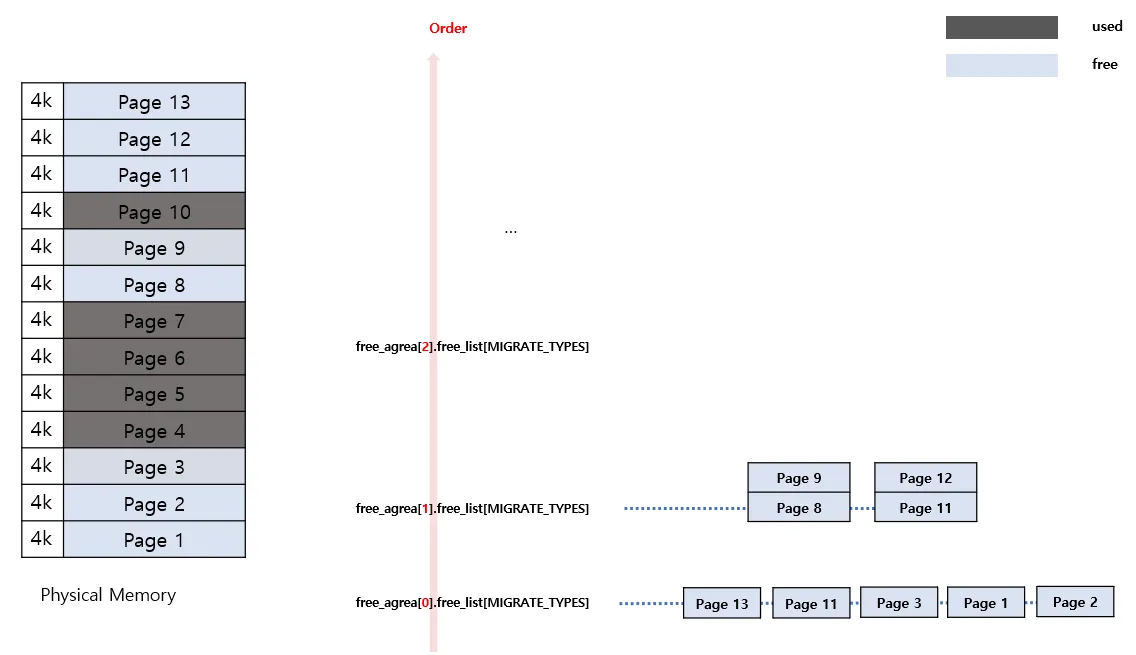
이번엔 Page12의 free 요청이 들어왔다.
Page12도 Order-0 에 속하므로 자신의 버디인 Page11을 확인한다. 현재 Page11 은 free되어 있기 때문에 병합이 발생하고 Page11,Page12가 Order-1 로 묶여서 free_list에 추가된다
3. Source code - free
초기 커널이 부팅되면서 동작하는 과정 가운데 여태 설명한 버디 시스템에 대한 부분을 간략하게 살펴보자
asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
/*
* Set up the the initial canary and entropy after arch
* and after adding latent and command line entropy.
*/
add_latent_entropy();
add_device_randomness(command_line, strlen(command_line));
boot_init_stack_canary();
mm_init_cpumask(&init_mm);
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
boot_cpu_state_init();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
build_all_zonelists(NULL);
page_alloc_init();
pr_notice("Kernel command line: %s\n", boot_command_line);
parse_early_param();
after_dashes = parse_args("Booting kernel",
static_command_line, __start___param,
__stop___param - __start___param,
-1, -1, NULL, &unknown_bootoption);
if (!IS_ERR_OR_NULL(after_dashes))
parse_args("Setting init args", after_dashes, NULL, 0, -1, -1,
NULL, set_init_arg);
jump_label_init();
/*
* These use large bootmem allocations and must precede
* kmem_cache_init()
*/
setup_log_buf(0);
pidhash_init();
vfs_caches_init_early();
sort_main_extable();
trap_init();
mm_init();
ftrace_init();
/* trace_printk can be enabled here */
early_trace_init();
.....
/* Do the rest non-__init'ed, we're now alive */
rest_init();
}
C
복사
mm_init()에서 메모리 관련 초기화를 한다
static void __init mm_init(void)
{
/*
* page_ext requires contiguous pages,
* bigger than MAX_ORDER unless SPARSEMEM.
*/
page_ext_init_flatmem();
mem_init();
kmem_cache_init();
pgtable_init();
vmalloc_init();
ioremap_huge_init();
/* Should be run before the first non-init thread is created */
init_espfix_bsp();
/* Should be run after espfix64 is set up. */
pti_init();
}
C
복사
mm_init() 함수안에서 mem_init() 함수를 호출한다
void __init mem_init(void)
{
pci_iommu_alloc();
#ifdef CONFIG_FLATMEM
BUG_ON(!mem_map);
#endif
/*
* With CONFIG_DEBUG_PAGEALLOC initialization of highmem pages has to
* be done before free_all_bootmem(). Memblock use free low memory for
* temporary data (see find_range_array()) and for this purpose can use
* pages that was already passed to the buddy allocator, hence marked as
* not accessible in the page tables when compiled with
* CONFIG_DEBUG_PAGEALLOC. Otherwise order of initialization is not
* important here.
*/
set_highmem_pages_init();
/* this will put all low memory onto the freelists */
free_all_bootmem();
after_bootmem = 1;
mem_init_print_info(NULL);
printk(KERN_INFO "virtual kernel memory layout:\n"
" fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
" cpu_entry : 0x%08lx - 0x%08lx (%4ld kB)\n"
#ifdef CONFIG_HIGHMEM
" pkmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
#endif
" vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"
" lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"
" .init : 0x%08lx - 0x%08lx (%4ld kB)\n"
" .data : 0x%08lx - 0x%08lx (%4ld kB)\n"
" .text : 0x%08lx - 0x%08lx (%4ld kB)\n",
FIXADDR_START, FIXADDR_TOP,
(FIXADDR_TOP - FIXADDR_START) >> 10,
CPU_ENTRY_AREA_BASE,
CPU_ENTRY_AREA_BASE + CPU_ENTRY_AREA_MAP_SIZE,
CPU_ENTRY_AREA_MAP_SIZE >> 10,
.....
C
복사
내부에서 free_all_bootmem() 함수를 호출한다. 영어 뜻 그대로 부팅시에 모든 free 메모리를 설정하는 함수이다. 주석에서 말하는 lowmem은 ZONE_DMA + ZONE_NORMAL 을 뜻한다
unsigned long __init free_all_bootmem(void)
{
unsigned long total_pages = 0;
bootmem_data_t *bdata;
reset_all_zones_managed_pages();
list_for_each_entry(bdata, &bdata_list, list)
total_pages += free_all_bootmem_core(bdata);
totalram_pages += total_pages;
return total_pages;
}
C
복사
reset_all_zones_managed_pages 함수에선 모든 존들을 초기화 한다. 그다음 free_all_bootmem_core 를 호출한다.
static unsigned long __init free_all_bootmem_core(bootmem_data_t *bdata)
{
struct page *page;
unsigned long *map, start, end, pages, cur, count = 0;
if (!bdata->node_bootmem_map)
return 0;
map = bdata->node_bootmem_map;
start = bdata->node_min_pfn; // 처음 페이지
end = bdata->node_low_pfn; // 마지막 페이지
bdebug("nid=%td start=%lx end=%lx\n",
bdata - bootmem_node_data, start, end);
while (start < end) { // 모든 페이지를 돌면서
unsigned long idx, vec;
unsigned shift;
idx = start - bdata->node_min_pfn;
shift = idx & (BITS_PER_LONG - 1);
/*
* vec holds at most BITS_PER_LONG map bits,
* bit 0 corresponds to start.
*/
vec = ~map[idx / BITS_PER_LONG];
if (shift) {
vec >>= shift;
if (end - start >= BITS_PER_LONG)
vec |= ~map[idx / BITS_PER_LONG + 1] <<
(BITS_PER_LONG - shift);
}
/*
* If we have a properly aligned and fully unreserved
* BITS_PER_LONG block of pages in front of us, free
* it in one go.
*/
// 초기 모든 페이지들은 reserved 되있음
if (IS_ALIGNED(start, BITS_PER_LONG) && vec == ~0UL) {
int order = ilog2(BITS_PER_LONG);
__free_pages_bootmem(pfn_to_page(start), start, order);
count += BITS_PER_LONG;
start += BITS_PER_LONG;
} else {
cur = start;
start = ALIGN(start + 1, BITS_PER_LONG);
while (vec && cur != start) {
if (vec & 1) {
page = pfn_to_page(cur);
__free_pages_bootmem(page, cur, 0);
count++;
}
vec >>= 1;
++cur;
}
}
}
cur = bdata->node_min_pfn;
page = virt_to_page(bdata->node_bootmem_map);
pages = bdata->node_low_pfn - bdata->node_min_pfn;
pages = bootmem_bootmap_pages(pages);
count += pages;
while (pages--)
__free_pages_bootmem(page++, cur++, 0);
bdata->node_bootmem_map = NULL;
bdebug("nid=%td released=%lx\n", bdata - bootmem_node_data, count);
return count;
}
C
복사
__free_pages_bootmem 함수를 통해 실제 페이지들을 buddy 시스템으로 세팅한다.
void __init __free_pages_bootmem(struct page *page, unsigned long pfn,
unsigned int order)
{
if (early_page_uninitialised(pfn))
return;
return __free_pages_boot_core(page, order);
}
C
복사
__free_pages_boot_core 함수 ㄱㄱ
static void __init __free_pages_boot_core(struct page *page, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
unsigned int loop;
prefetchw(p);
for (loop = 0; loop < (nr_pages - 1); loop++, p++) {
prefetchw(p + 1);
__ClearPageReserved(p);
set_page_count(p, 0);
}
__ClearPageReserved(p);
set_page_count(p, 0);
page_zone(page)->managed_pages += nr_pages;
set_page_refcounted(page);
__free_pages(page, order);
}
C
복사
__free_pages 함수 ㄱㄱ
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_cold_page(page, false);
else
__free_pages_ok(page, order);
}
}
C
복사
__free_pages_ok 함수 ㄱㄱ
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page);
if (!free_pages_prepare(page, order, true))
return;
migratetype = get_pfnblock_migratetype(page, pfn);
local_irq_save(flags);
__count_vm_events(PGFREE, 1 << order);
free_one_page(page_zone(page), page, pfn, order, migratetype);
local_irq_restore(flags);
}
C
복사
free_one_page 함수 ㄱㄱ
/*
* Freeing function for a buddy system allocator.
*
* The concept of a buddy system is to maintain direct-mapped table
* (containing bit values) for memory blocks of various "orders".
* The bottom level table contains the map for the smallest allocatable
* units of memory (here, pages), and each level above it describes
* pairs of units from the levels below, hence, "buddies".
* At a high level, all that happens here is marking the table entry
* at the bottom level available, and propagating the changes upward
* as necessary, plus some accounting needed to play nicely with other
* parts of the VM system.
* At each level, we keep a list of pages, which are heads of continuous
* free pages of length of (1 << order) and marked with _mapcount
* PAGE_BUDDY_MAPCOUNT_VALUE. Page's order is recorded in page_private(page)
* field.
* So when we are allocating or freeing one, we can derive the state of the
* other. That is, if we allocate a small block, and both were
* free, the remainder of the region must be split into blocks.
* If a block is freed, and its buddy is also free, then this
* triggers coalescing into a block of larger size.
*
* -- nyc
*/
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long combined_pfn;
unsigned long uninitialized_var(buddy_pfn);
struct page *buddy;
unsigned int max_order;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype);
VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
continue_merging:
while (order < max_order - 1) {
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
if (max_order < MAX_ORDER) {
/* If we are here, it means order is >= pageblock_order.
* We want to prevent merge between freepages on isolate
* pageblock and normal pageblock. Without this, pageblock
* isolation could cause incorrect freepage or CMA accounting.
*
* We don't want to hit this code for the more frequent
* low-order merging.
*/
if (unlikely(has_isolate_pageblock(zone))) {
int buddy_mt;
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
buddy_mt = get_pageblock_migratetype(buddy);
if (migratetype != buddy_mt
&& (is_migrate_isolate(migratetype) ||
is_migrate_isolate(buddy_mt)))
goto done_merging;
}
max_order++;
goto continue_merging;
}
done_merging:
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
*/
if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {
struct page *higher_page, *higher_buddy;
combined_pfn = buddy_pfn & pfn;
higher_page = page + (combined_pfn - pfn);
buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);
higher_buddy = higher_page + (buddy_pfn - combined_pfn);
if (pfn_valid_within(buddy_pfn) &&
page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}
C
복사
실제 위 함수에서 여태 설명한 버디 시스템 초기화를 진행한다. zone 구조체의 free_area.free_list에 page_block들을 추가하는걸 볼 수 있다.
초기 커널이 부팅 될 때 날 것의 page들을 free_list에 추가하는 과정을 정말 간단하게 살펴봤다.
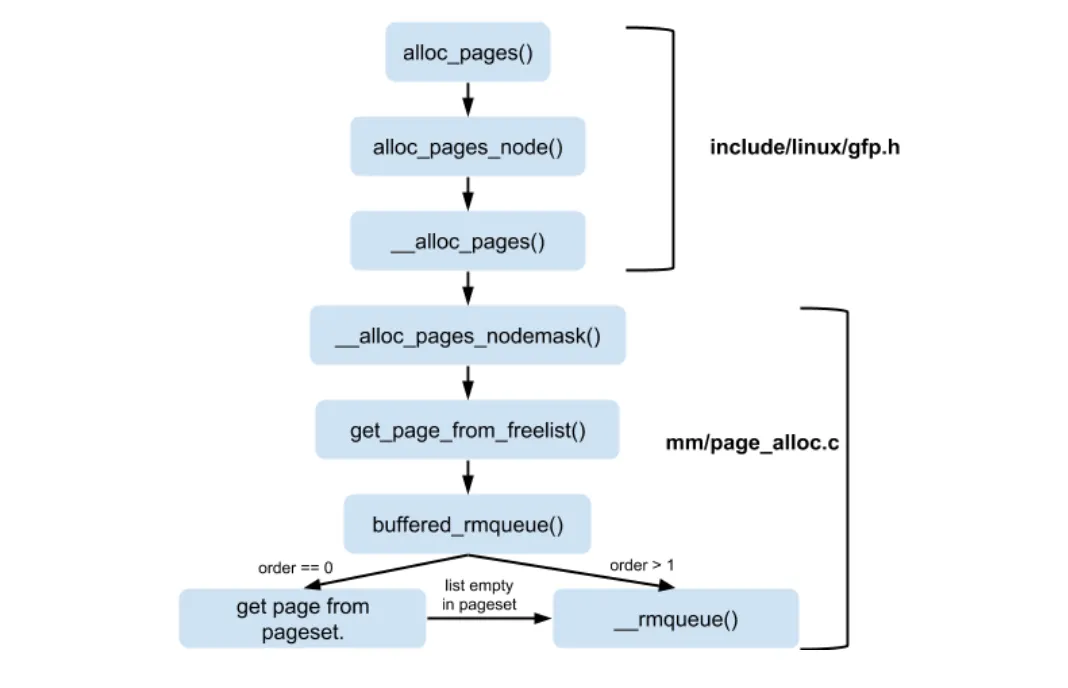
Source code - alloc
버디 시스템에서 페이지 요청시에 수행되는 코드는 다음의 그림으로 잘 표현된다