

1. 개요
해당 분석을 진행하는 목표는 iot 펌웨어에서 파일 시스템을 추출할 때 binwalk로 바로 추출되지 않는 경우가 존재했다. 추출을 방지하기 위해 더미 값이 들어있었거나 정상적인 파일시스템의 구조에 맞지 않는 값 들이 들어가있는 경우가 있었다.
따라서 squashfs 구조를 정확하게 분석하는 것에 초점을 맞추기 보단. format이 어떻게 구성되어 있으며 010 editor의 template을 이용하여 어느 위치에 어떠한 데이터들이 들어있어야하 하는지 정도로 초점을 맞춰 분석을 진행해보고자 한다.
2. 특징
몇몇 임베디드 시스템에서는 변경 가능한 파일 시스템이 필요 없는 경우가 있다. 이때는 변경
불가능한 파일 시스템으로 충분하다. 리눅스는 다양한 읽기 전용 파일 시스템을 제공하는데, 가
장 유용한 두 가지는 CramFS와 SquashFS다.
SquashFS는 고압축 파일시스템으로 소형화된 Linux device에서 사용되는 파일시스템이기 때문에 작은 용량을 갖춰, 제한된 디스크나 메모리 용량의 임베디드 시스템에 효율적으로 사용 가능하다.
대표적인 특징은 다음과 같다
•
Data, i-node 및 directory 에 대해 압축
•
파일에 대해 최대 2^64 byte를 지원함
•
Big/Little Endian 모두 제공
•
Read-only file system
•
zlib, lz4, lzo 또는 xz 압축을 사용하여 파일, inode 및 디렉토리. 시스템의 i-node는 매우 작고 모든 블록은 데이터 오버헤드를 최소화
3. 구조
SquashFS은 최대 9개의 구조로 구성된다.
_______________
| | Important information about the archive, including
| Superblock | locations of other sections.
|_______________|
| | If non-default compression options have been used,
| Compression | they can optionally be stored here, to facilitate
| options | later, offline editing of the archive.
|_______________|
| |
| Data blocks | The contents of the files in the archive,
| & fragments | split into separately compressed blocks.
|_______________|
| | Metadata (ownership, permissions, etc) for
| Inode table | items in the archive.
|_______________|
| |
| Directory | Directory listings, including file names, and
| table | references to inodes.
|_______________|
| |
| Fragment | Description of fragment locations within the
| table | Datablocks & Fragments section.
|_______________|
| | A mapping from inode numbers to disk locations,
| Export table | required for NFS export.
|_______________|
| |
| UID/GID | A list of unique UID/GIDs. Inodes use an index into
| lookup table | this table to save memory.
|_______________|
| |
| Xattr | Extended attributes for items in the archive.
| table |
|_______________|
Bash
복사
1.
superblock
슈퍼블록은 squashfs의 첫 섹션에 해당한다. 슈퍼블록 사이즈는 항상 96byte로 고정이며 다음의 데이터들이 저장된다.
Type | Name | Description |
u32 | magic | hsqs로 세팅되야함 |
u32 | inode count | 저장된 inode 개수 |
u32 | mod time | 마지막 수정 시간 timestamp |
u32 | block size | data block 사이즈. 반드시 4k - 1Mib 사이여야함 |
u32 | fragment_entry_count | fragment table의 entry 개수 |
u16 | compression_id | 1 - GZIP : just zlib streams (no gzip headers!)
2 - LZMA
3 - LZO
4 - XZ : LZMA version 2 as used by xz-utils
5 - LZ4
6 - ZSTD |
u16 | block_log | 얜 머지 |
u16 | superblock flags | 아래서 따로 설명 |
u16 | id_count | id lookup table의 entry 개수 |
u16 | version_major | squashfs major 버전. 항상 4 |
u16 | version_minor | squashfs minor 버전. 항상 0 |
u64 | root_inode_ref | root directory의 inode 참조(잘 모르겠다) |
u64 | bytes_used | archive에서 사용중인 bytes수. |
u64 | id_table_start | id table이 시작되는 바이트 오프셋 |
u64 | xattr_table_start | xattr table이 시작되는 오프셋. (옵션으로 사용하지 않는다면 0xFFFFFFFFFFFFFFFF으로 세팅) |
u64 | inode_table_start | inode table이 시작되는 오프셋. |
u64 | directory_table_start | directory table이 시작되늰 오프셋. |
u64 | fragment_table_start | fragment table이 시작되는 오프셋. (옵션으로 사용하지 않는다면 0xFFFFFFFFFFFFFFFF으로 세팅) |
u64 | export_table_start | export table이 시작되는 오프셋. (옵션으로 사용하지 않는다면 0xFFFFFFFFFFFFFFFF으로 세팅) |
superblock flags
2.
Data and Fragment Blocks
data block과 fragment block에는 압축된 실제 데이터들이 포함된다.
3.
Inode Table
inode table은 superblock에 명시된 inode_table_start부터 directory_table_start까지를 뜻한다. 소유권, 권한 등과 같은 metadata 정보가 들어간다.
4.
Directory table
file name, inode 참조 등이 포함된 정보들이 들어간다.
5.
Fragment Table
datablock과 fragment 섹션에 위치한 fragment 위치 정보가 들어간다.
6.
Export Table
disk에 위치한 inode number에 매핑되는 값과 관련된 내용이 들어간다. 이는 NFS에서 필요로하는 정보이다.
7.
UID/GID lookup Table(id table)
uid/gid 정보들이 들어간다.
8.
Extended Attribute Table
사용자가 임의로 속성을 정의하고 싶을 때 사용하는 테이블로. xattr table로 표시된다.
4. 환경 설정
실제 squashfs을 구성하여 분석해보자.
1.
squashfs-tools 설치
$ sudo apt install squashfs-tools
Bash
복사
2.
파일시스템안에 들어갈 디렉토리 및 파일 생성

대충 디렉토리와 파일들에 내용을 채운 후
3.
squashfs 생성
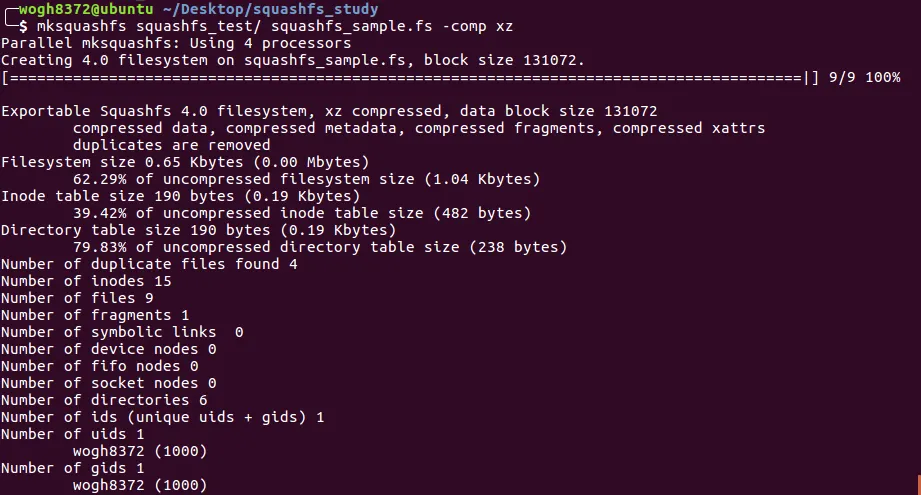
$ mksquashfs squashfs_test/ squashfs_sample.fs -comp xz
Bash
복사
5. 분석
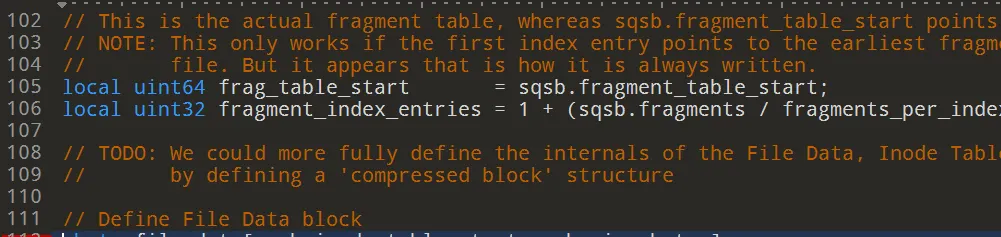
우선 010 editor의 squashfs 템플릿을 적용시켰다. 참고로 그냥 실행하면 에러가 발생하므로 105라인의 sqsb.fragment_table_start 부분을 수정해줬다. 원래는 ReadUInt64로 감싸져있었는데 캐스팅이 잘못되는건지 값이 틀어져서 그냥 지워졌다.
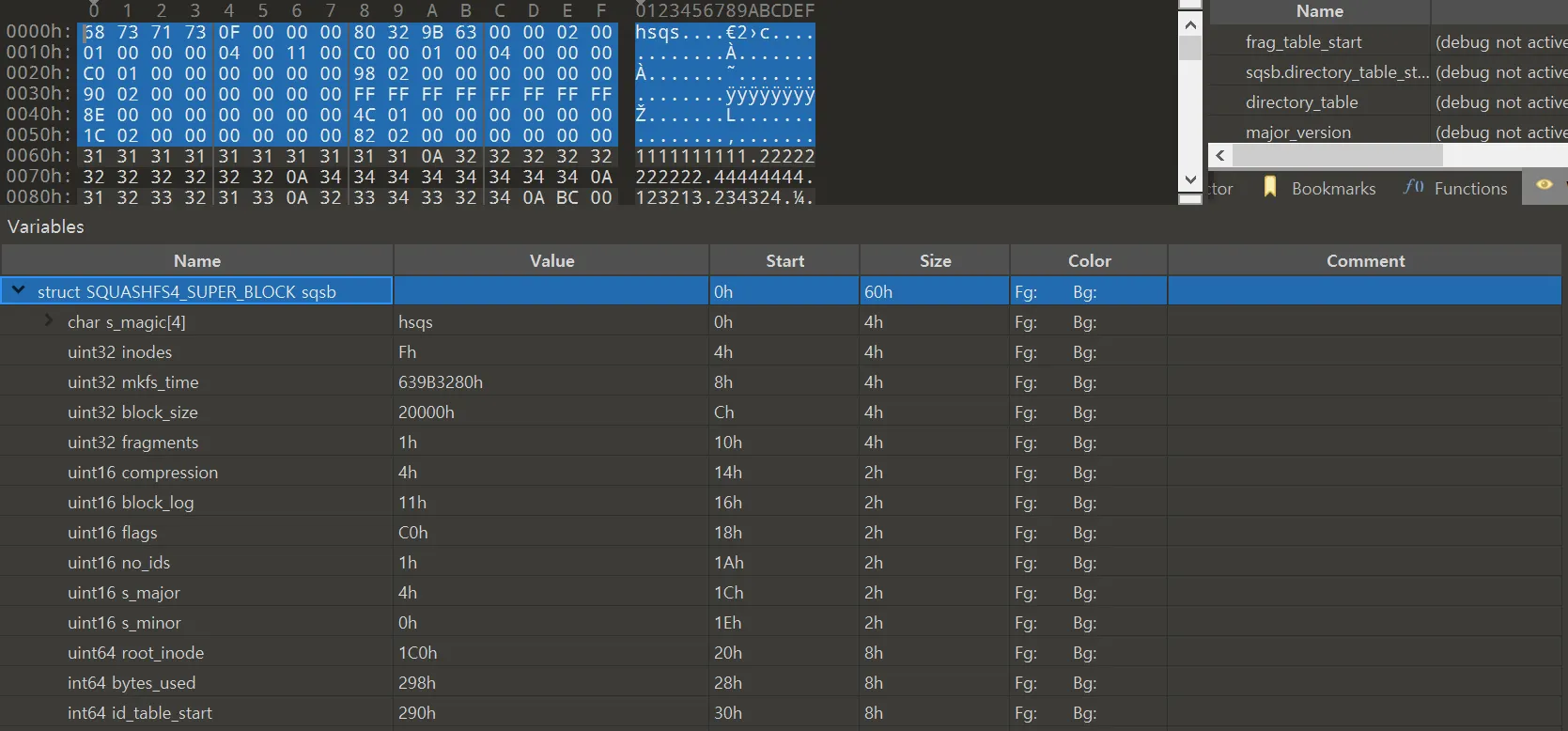
슈퍼블록에서 중요 필드들을 살펴보면 다음과 같다.
•
magic
◦
‘hsqs’ 파일 시그니처 값이 제일 처음 나온다
•
compression
◦
-comp xz 옵션을 설정하여 xz 압축 포맷을 사용했기 때문에 4 값으로 설정되어있다
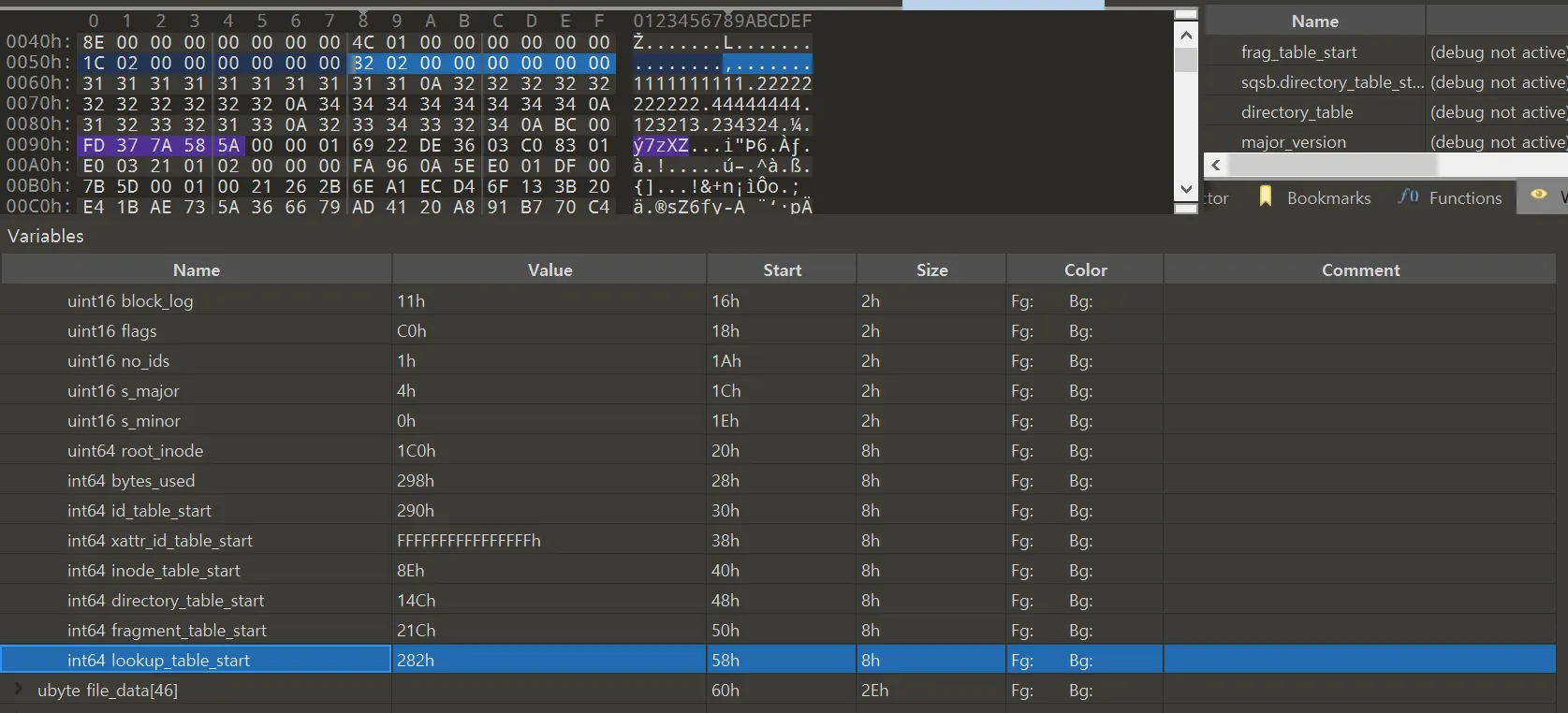
superblock
•
id_table_start
◦
id_table의 시작 주소는 0x290이다.
•
xattr_id_table_start
◦
xattr table은 사용하지 않기 때문에 0xFFFFFFFFFFFFFFFF로 설정되어 있다
•
inode_table_start
◦
offset 0x8e
•
directory_table_start
◦
offset 0x14c
•
fragment_table_start
◦
offset 0x21c
•
lookup_table_start
◦
offset 0x282
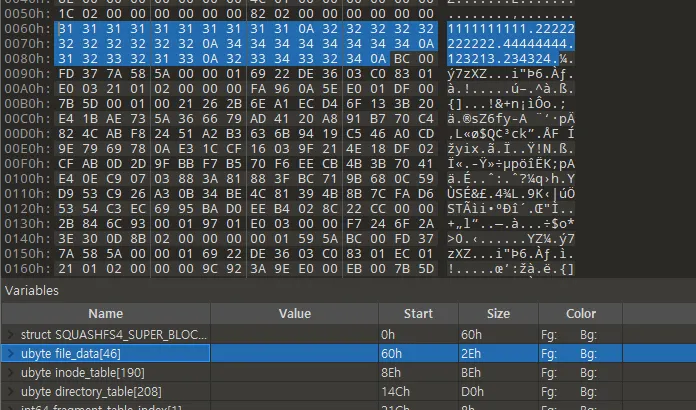
Data blocks
•
file_data 부분이 바로 Data_blocks 필드이다. 디렉토리와 파일들을 생성 후 안에 내용을 1111, 222 .. 이렇게 대충 몇개만 넣어둬서 그런지 해당 영역에 파일 내용이 압축되지 않고 다 그대로 보인다. 또한 xz이 아닌 gzip 으로 압축시에는 파일 내용이 보이지 않고 압축되어 보인다.
gzip 으로 압축시
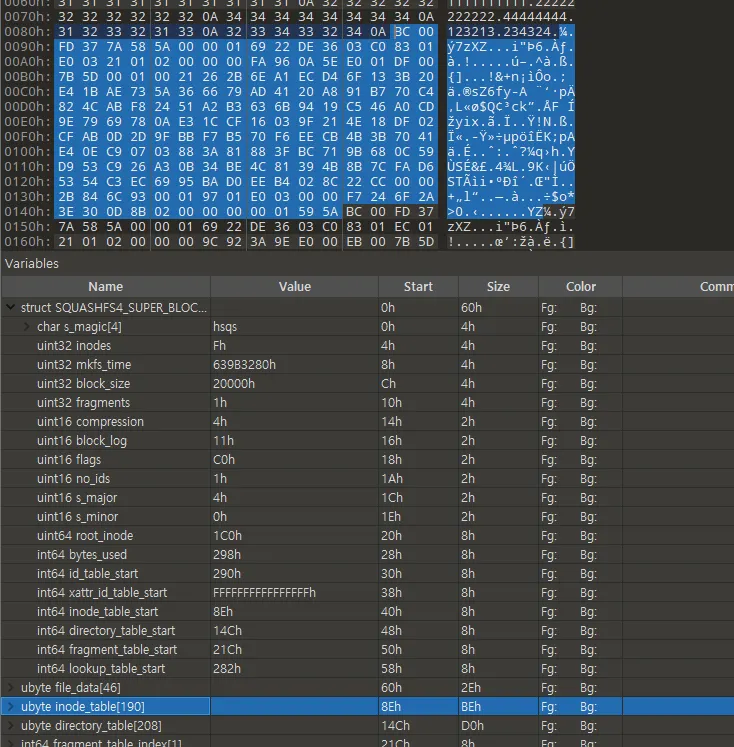
inode table
•
superblock의 inode_table_start 주소를 보면 0x8e로 설정되어 있다.
사실 이렇게만 보면 inode_table, directory_table, fragment_table 등의 시작주소만 확인이 가능하다. 참고한 자료를 봐도 이해가 잘 되지 않아, unsquashfs을 직접 빌드하여 해당 코드에서 실제 데이터를 추출하는 로직을 디버깅하였다.
소스코드는 아래 깃허브를 사용하였다.
task.json
launch.json
makefile 수정 // -g 옵션 추가
task.json과 launch.json을 사용하여 vscode에서 디버깅 환경 설정을 하였다.
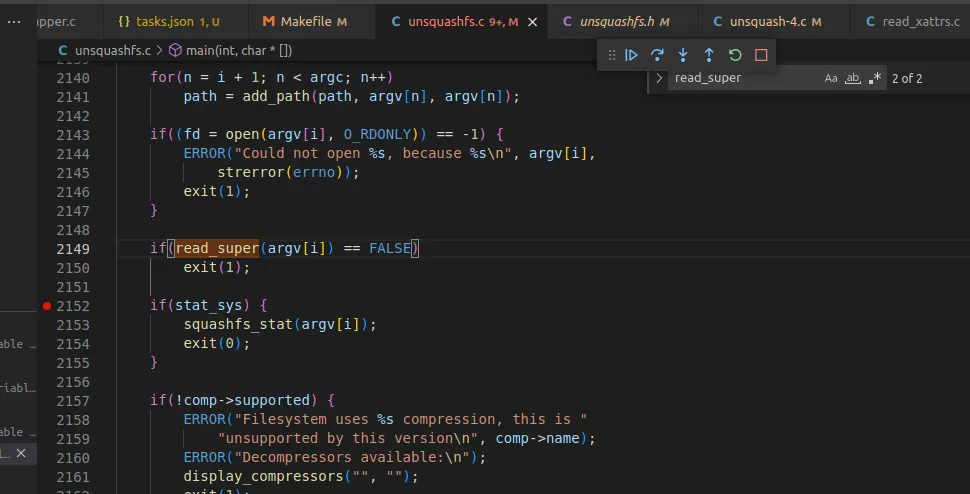
unsquashfs.c
•
unsquashfs.c 코드를 보면 가장 먼저 read_super 함수를 이용하여 슈퍼블록을 읽는다.

read_super
•
magic 값(hsqs)와 major 값이 4이면 함수 포인터들을 설정한다.
•
fragment_table, inode_table 등을 읽는 함수 포인터들을 설정하고
•
lookup_compressor_id를 통해 compression 필드를 통해 압축 알고리즘을 설정한다. 현재는 xz 이므로 4로 설정되어있다.
5.1 read_uids_guids
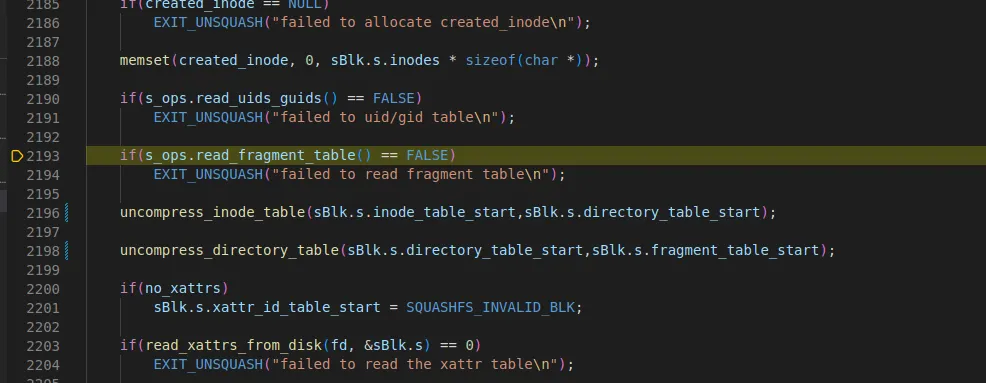
•
그다음 s_ops.read_uids_guids 함수 호출한다.
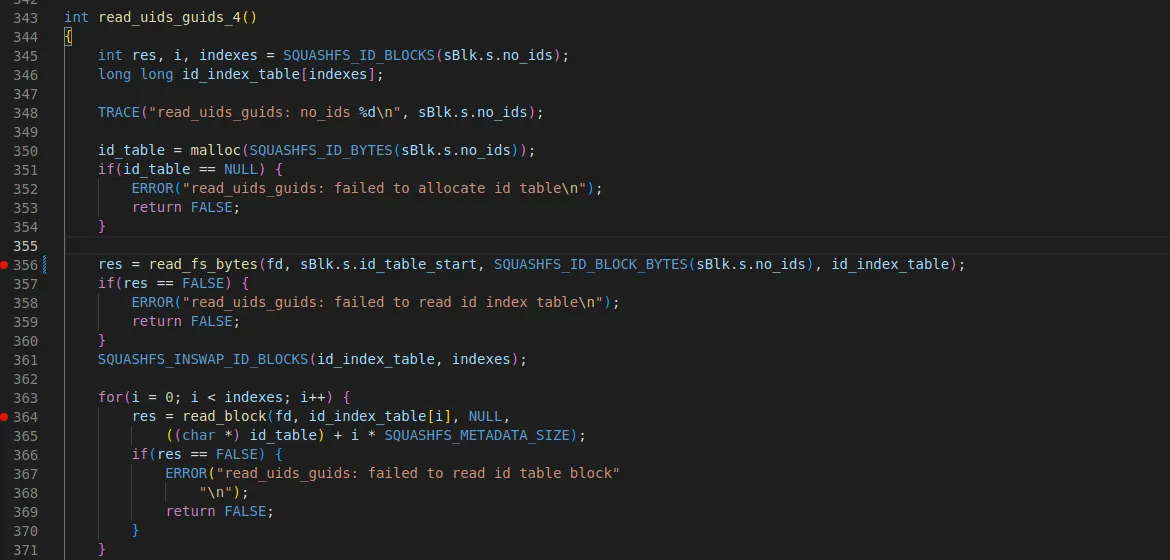
•
해당 함수는 read_uids_guids_4 함수포인터이다.
•
super block에 id_count 값이 바로 no_ids이다. id look up table의 개수를 확인한 뒤
•
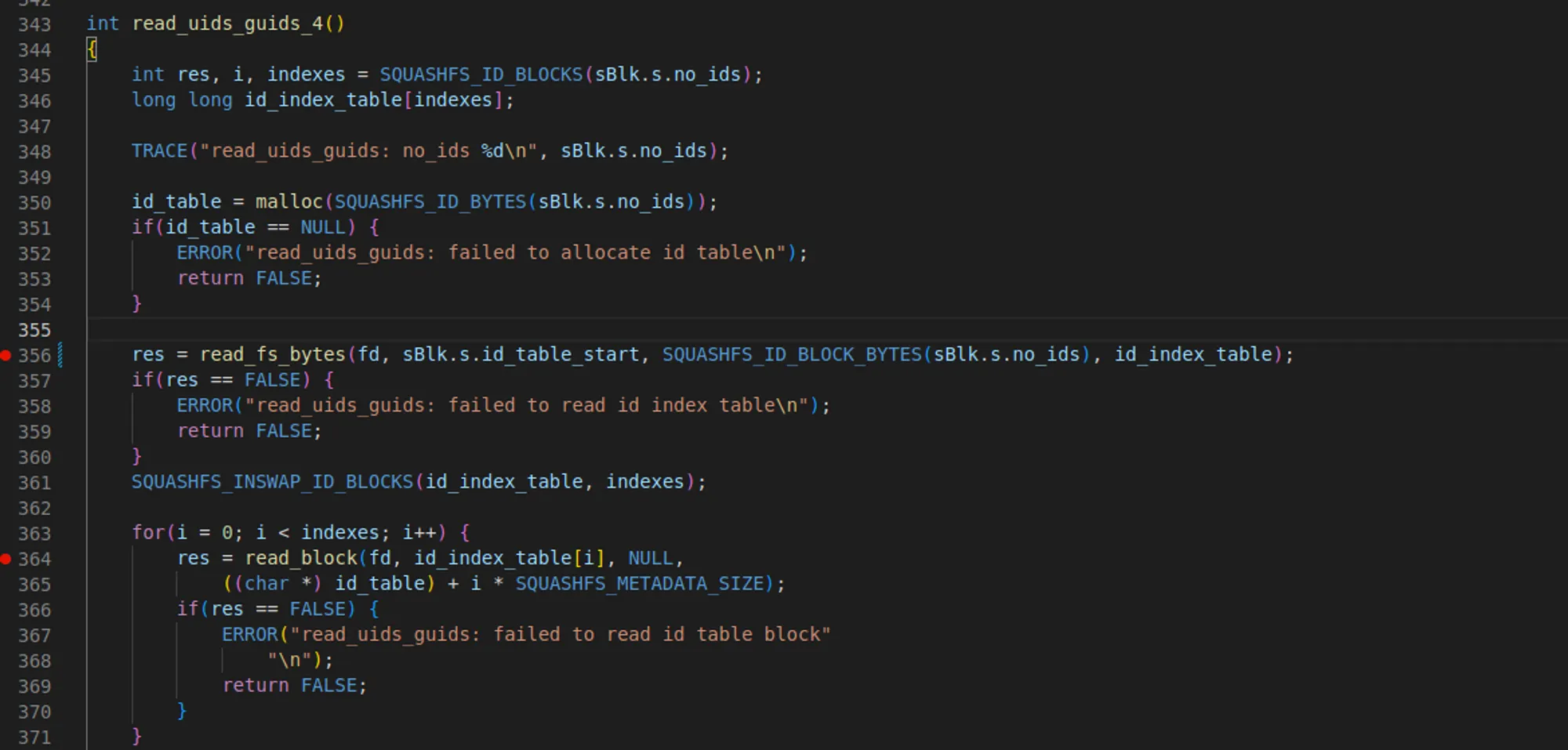
read_fs_bytes 호출
◦
id_table_start 주소(현재 0x290)부터 SQUASHFS_ID_BLOCK_BYTES 매크로 만큼 읽는다. 해당 매크로로 계산되는 값은 8바이트이다. 실제 010 editor로 확인해보면 다음과 같다.
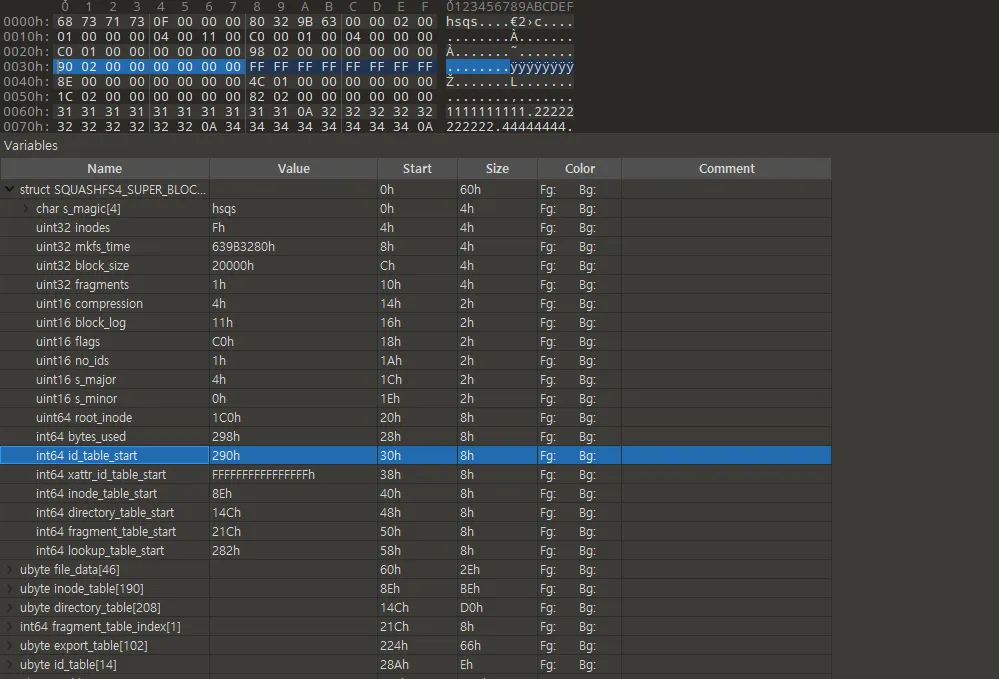
•
super block의 id_table_start는 0x290이다.
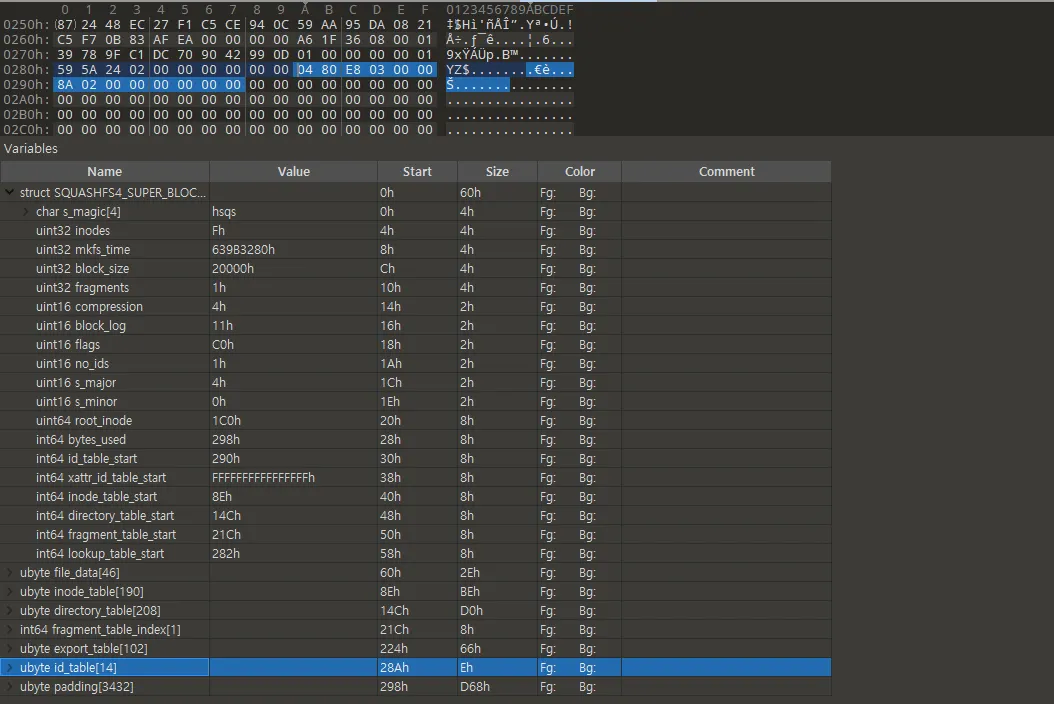
•
0x290 offset으로 가서 8바이트를 읽는다.
•
해당 8바이트는 0x28a로 id_table의 실제 시작 주소이다.
•
read_fs_bytes 호출 후
•
read_block 호출
◦
두번째 인자 값은 0x28a이다
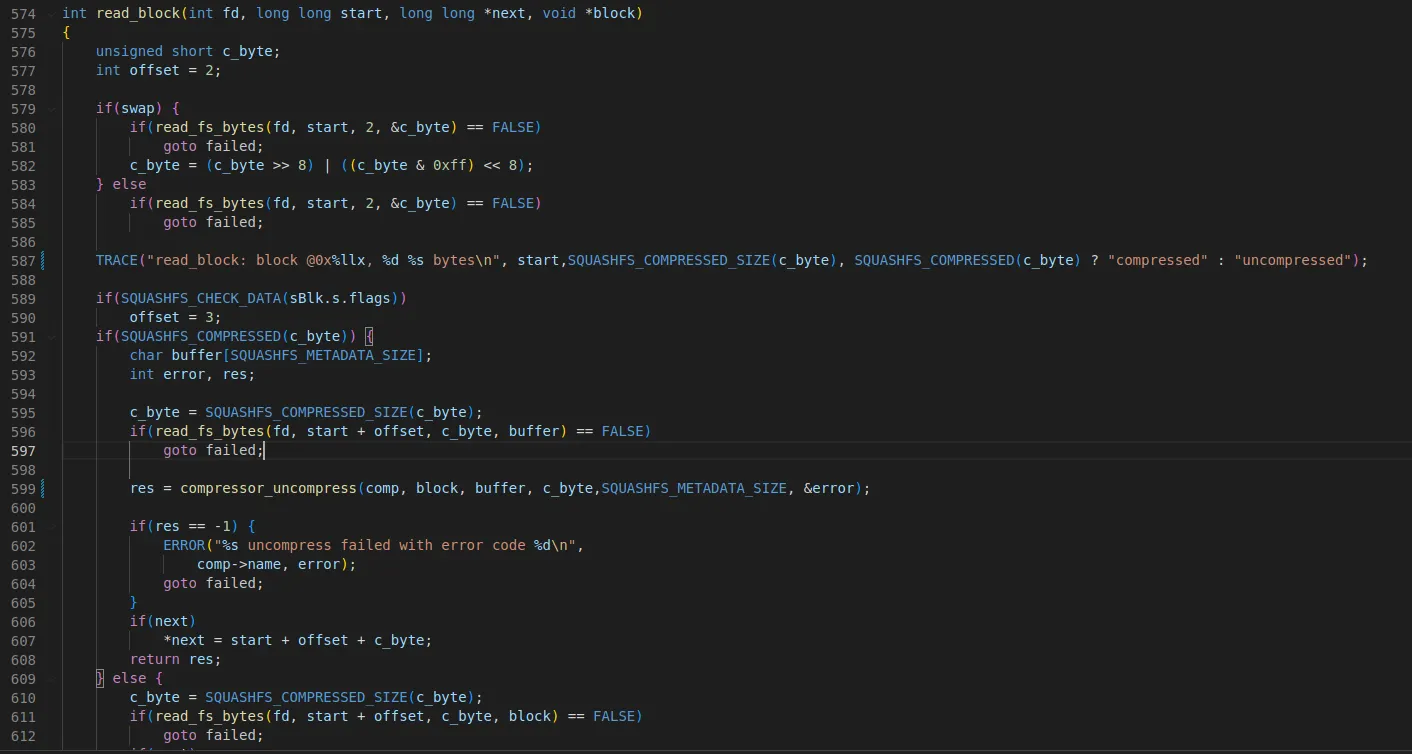
•
read_block 내부에서
•
read_fs_bytes를 호출한다. 현재 start(0x28a)에서 2byte를 읽는다. 0x28a offset의 2바이트는 0x8004이다.
◦
compression_bit(0x8000)가 설정되어 있다면 id table은 uncompress되어 있다는 의미이다.
◦
0x8004 & 0x8000 = 0x8000 이므로 id table은 uncompress되어 있기 때문에 591라인은 건너뛰게 된다.
◦
uncompress size는 4로 계산된다.(SQUASHFS_COMPRESSED_SIZE)
•
610 라인에서 0x28a+2 부터 SQUASHFS_COMPRESSED_SIZE(4) 만큼 읽는다.(0x3e8)
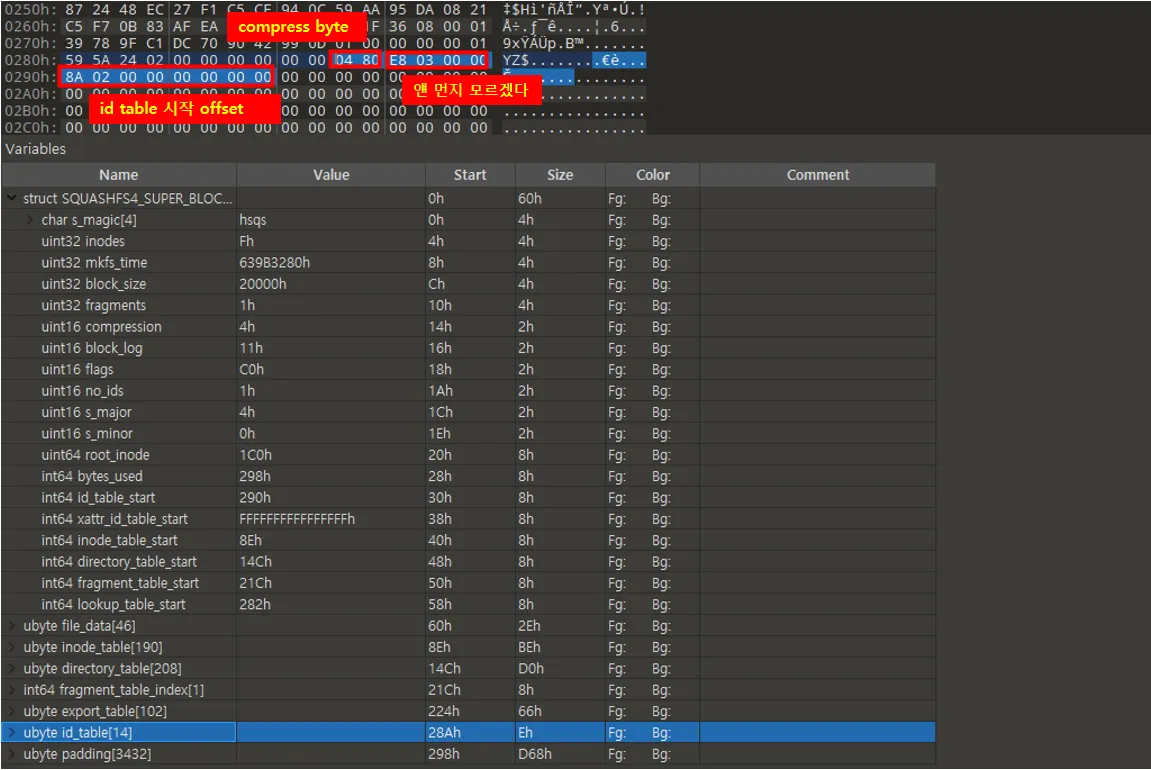
•
정리하면 다음과 같다. id_table_start 주소는 0x290이며
•
0x290 주소에는 id table의 실제 시작 주소인 0x28a가 들어있다
•
0x28a 에는 id table 압축 유무를 확인하는 2바이트 값이 들어가 있다.
◦
현재는 uncompress 4byte로 확인
•
그다음 0x28c 4바이트는 먼지 모르겠다.
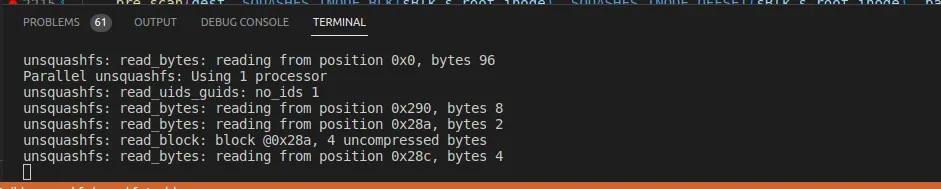
•
read_uids_guids 함수 호출의 최종 로그는 다음과 같다
5.2 s_ops_read_fragment_table
•
read_fragment_table을 호출한다.
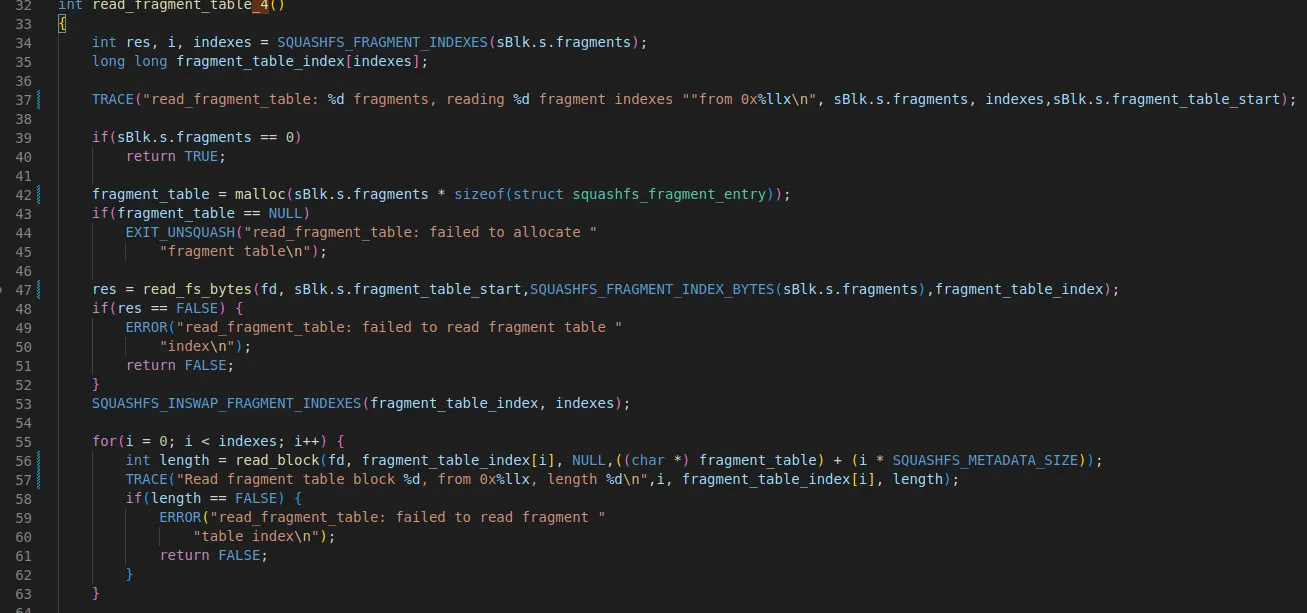
•
super block에 들어있는 fragment 개수(현재 1)와 fragment_table_start 주소를 확인한다
read_fs_bytes를 통해 fragment_table_start(0x21c)부터 8바이트 읽는다
•
56라인에서 read_block을 통해 block을 읽는다. 시작 offset은 0x21c에 들어있는 0x20a이다
•
read_block함수에선 아까와 동일하게 0x20a에 들어있는 2바이트 값과 그다음 4바이트를 읽는다.
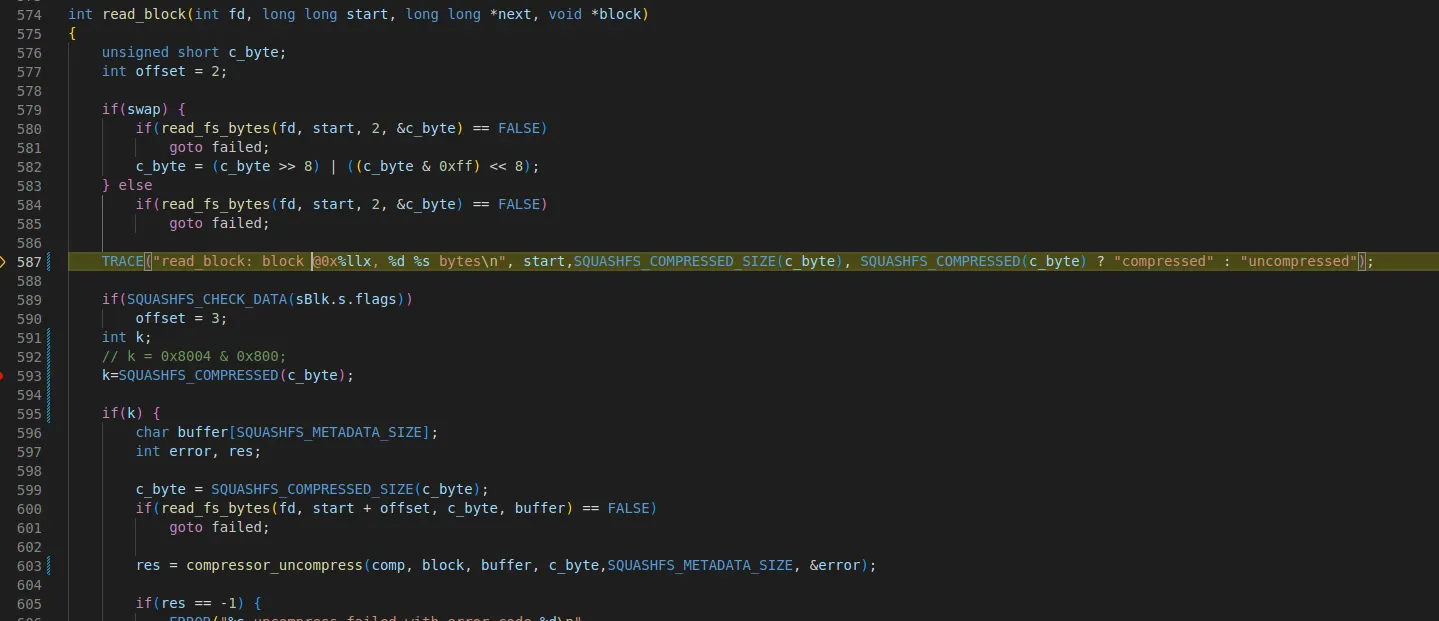
•
0x20a에서 2바이트(0x8010)을 읽고 압축 바이트를 계산한다.
◦
0x8000과 0x8010과 & 연산을 한 결과 압축되지 않는 SQUASHFS_COMPRESSED_SIZE(16bytes)가 계산된다..
•
0x20a+2 부터 계산된 SQUASHFS_COMPRESSED_SIZE(16) 만큼 읽는다.
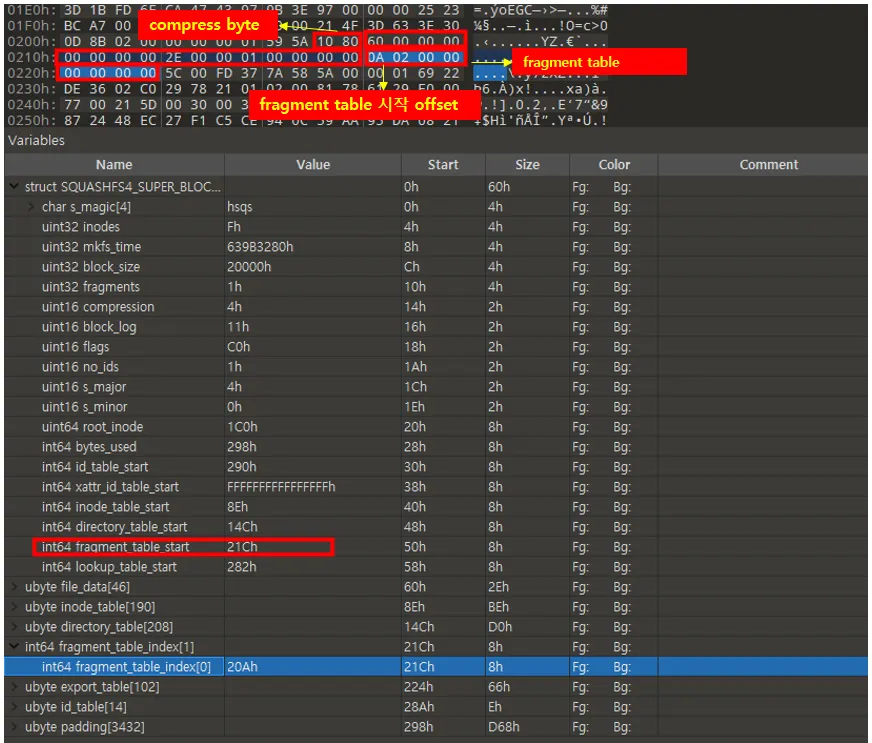
•
정리하면 다음과 같다.
•
super block에 있는 fragment_start주소는 0x21c
•
0x21c offset으로 가서 8바이트 읽기 → 0x20a
•
0x20a offset으로 가서 2바이트 읽기 → compress bytes
◦
16바이트의 uncompress 데이터 계산됨.

•
s_ops_read_fragment_table 함수의 호출이 끝난 후의 로그
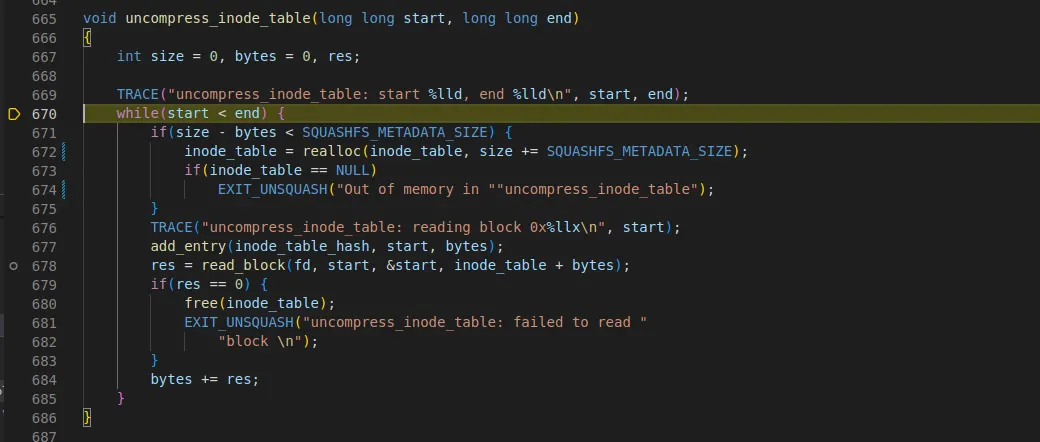
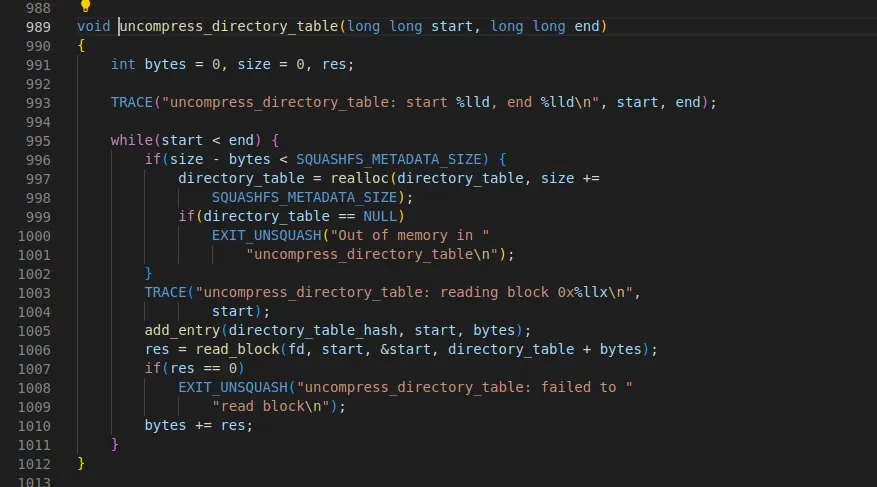
5.3 uncompress_inode_table
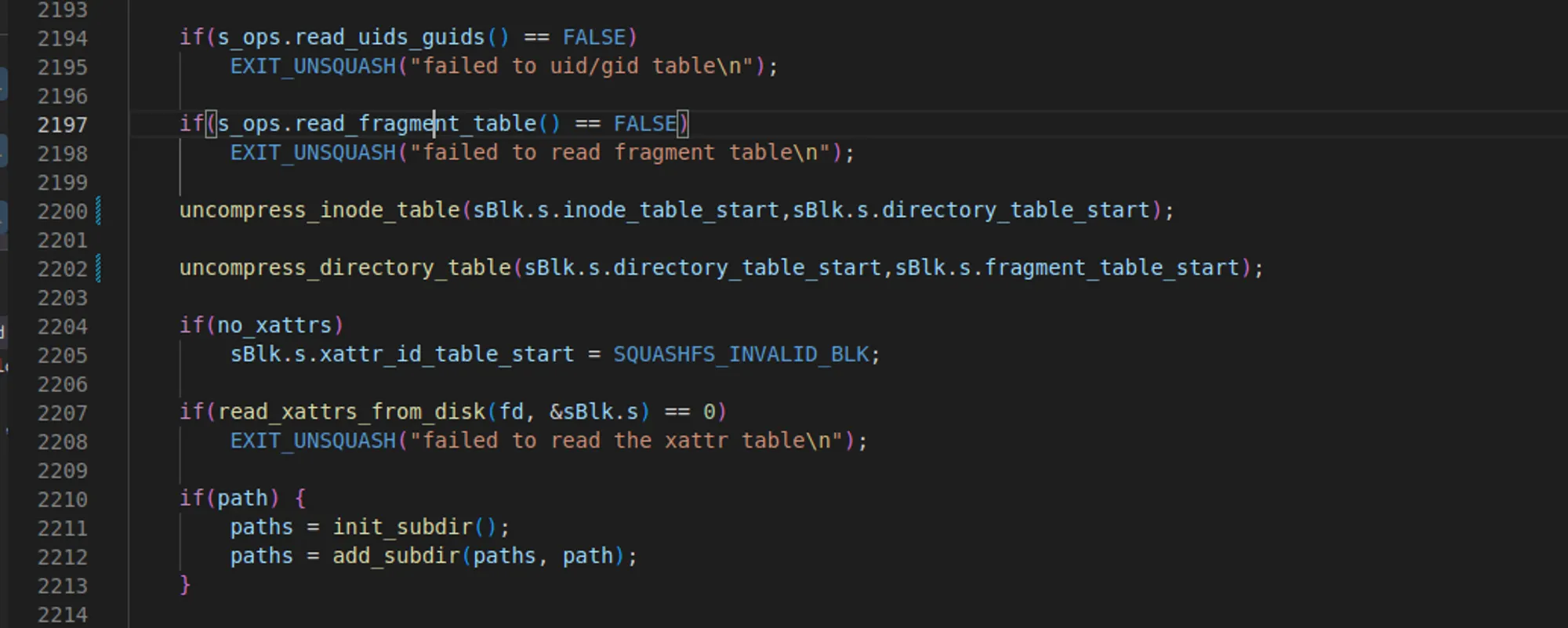
•
uncompress_inode_table을 호출한다.
•
super block에서 inode_table_start 부터 directory_table_start까지가 inode_table 이다
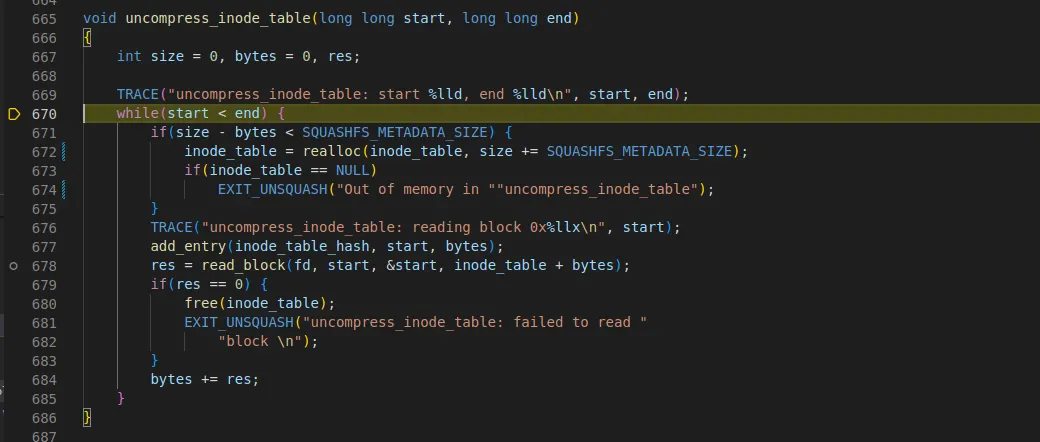
•
start : 0x8e, end : 0x14c
678라인에서 read_block을 호출한다. 시작 주소는 0x8e이다
•
670 라인의 while문이 한번 돈 후 start 값은 0x90 + 188 = 0x14c이다
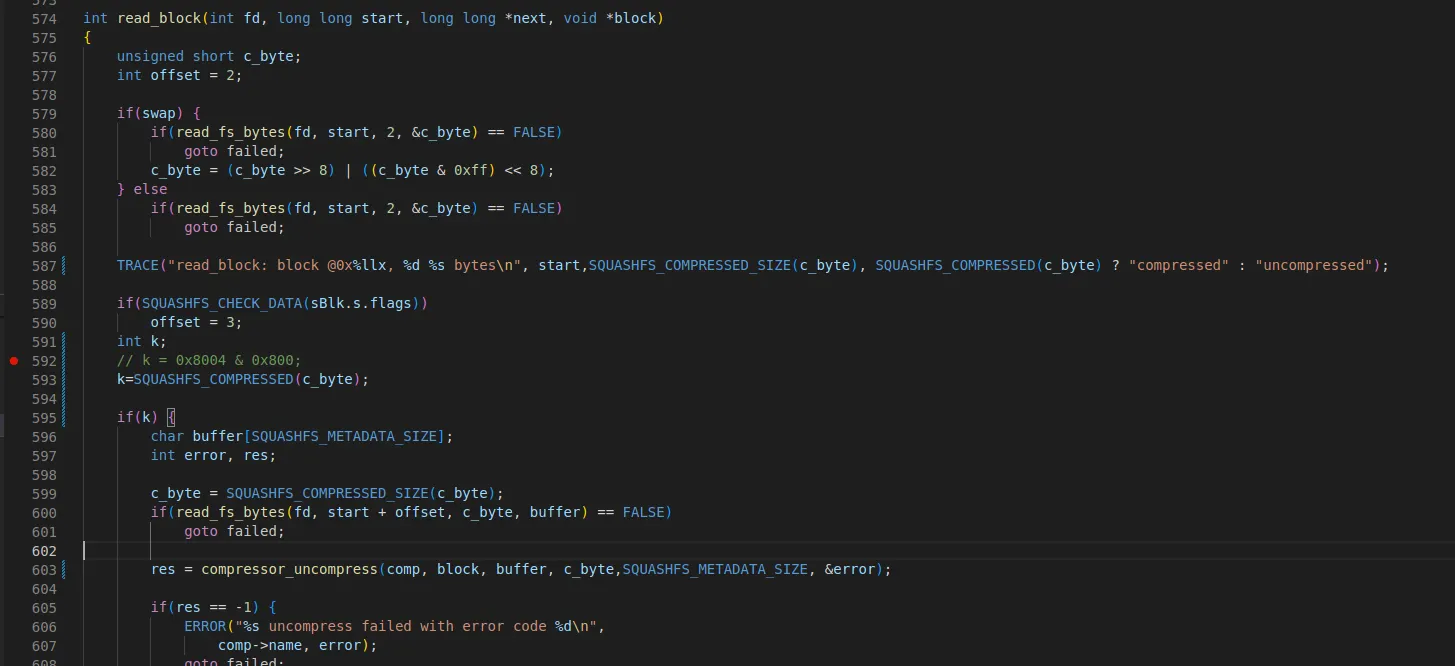
•
read_block 함수를 보면
•
0x8e에서 2byte는 현재 0xbc이다
•
595라인에서 압축 확인은 진행하는데 전에는 압축되지 않는 값으로 연산되었지만
•
inode_table은 0xbc * 0x8000 = 0 으로 압축된 것으로 확인된다.
◦
압축 사이즈 : (B) & ~SQUASHFS_COMPRESSED_BIT → 188byte
•
따라서 603라인 compressor_uncompress 함수를 통해 압축된 데이터를 해제한다.
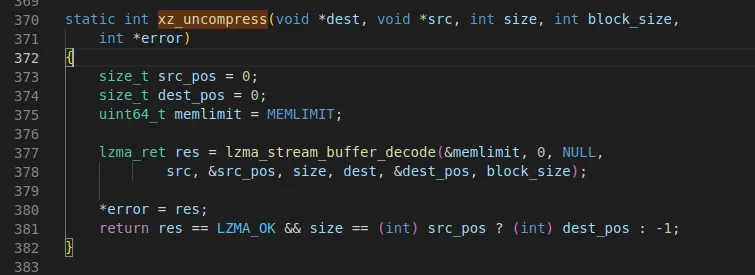
•
xz compression이기 때문에 xz_uncompress를 호출하여 188byte 압축 해제를 진행한다.
•
670 라인의 while문이 한번 돈 후 start 값은 0x90 + 188 = 0x14c이다
•
따라서 start와 end가 0x14c로 동일해져 loop는 한번만 돌고 끝나게 된다.
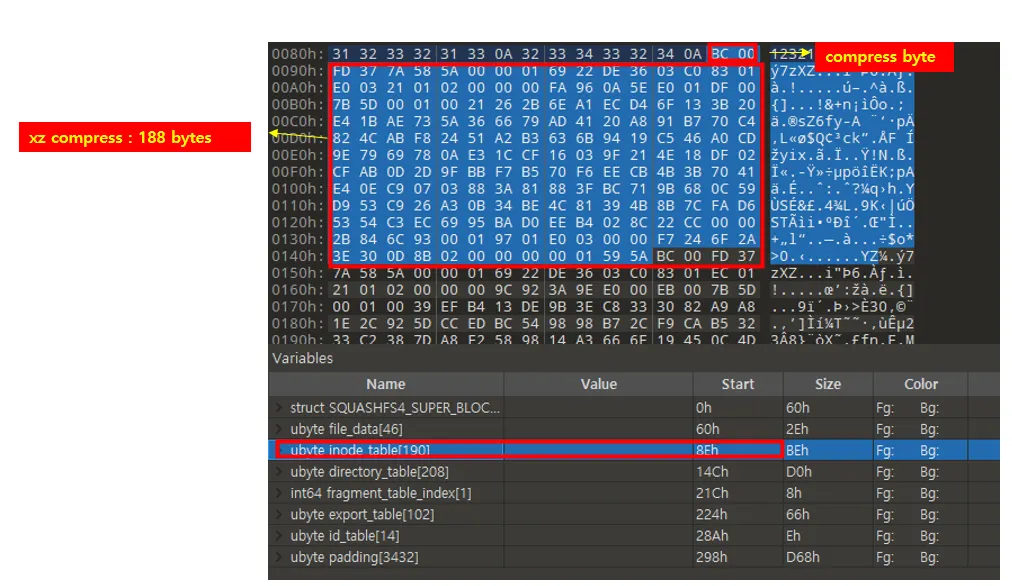
•
정리하면 다음과 같다
•
inode_table start offset : 0x8e
•
0x8e ~ +2 : compress byte
◦
0xbc & 0x8000 : 0
◦
즉 압축되어있다는 의미
◦
압축 사이즈 : (B) & ~SQUASHFS_COMPRESSED_BIT → 188bytes

•
uncompress_inode_table 함수 호출 이후 로그
5.4 uncompress_directory_table
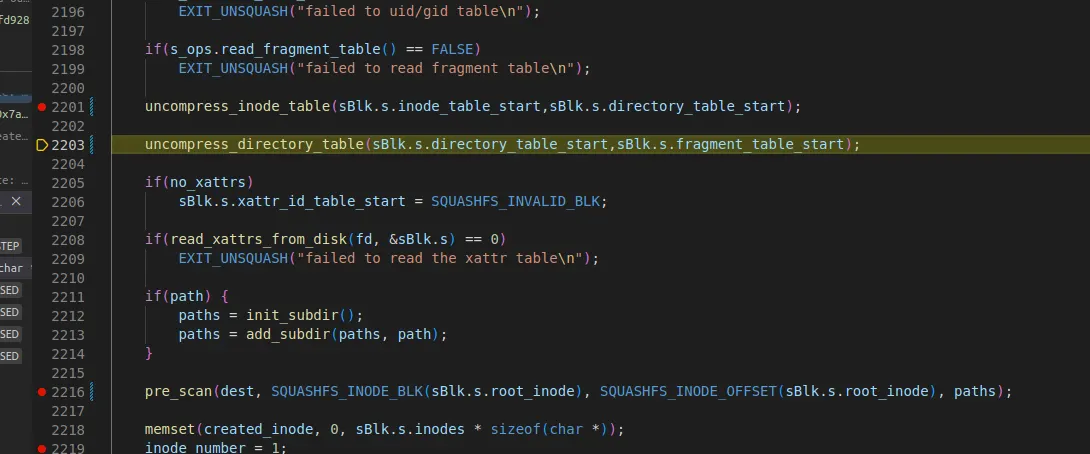
•
directory_table도 inode_table과 동일한 방식으로 진행된다.
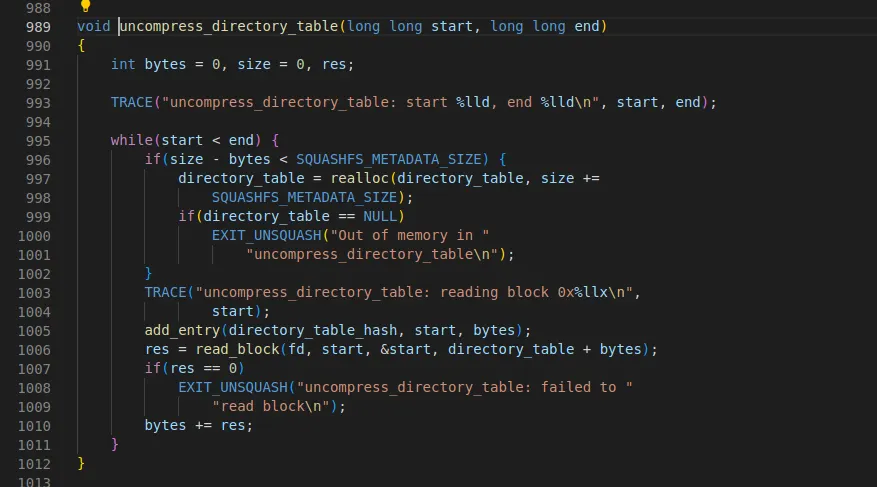
•
super block 상의 directory_table 주소는 0x14c ~ 0x21c이다.
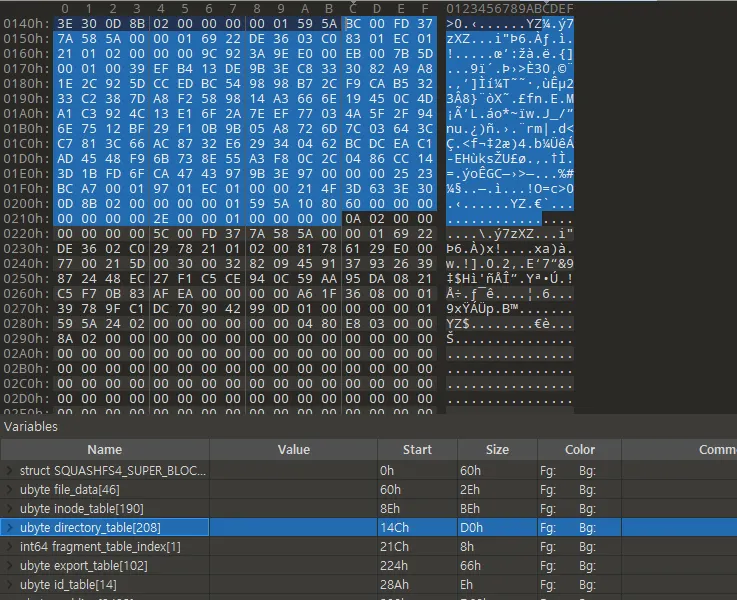
•
start : 0x14c end: 0x21c
•
0x14c ~ +2 : 0xbc
◦
따라서 위와 동일하게 압축된 directory table이며 크기는 188byte이다.
•
xz_compress 함수로 압축 해제가 된다
•
그다음 loop에서는 start : 0x14e+188 : 0x20a, end: 0x21c이기 때문에 한번 더 loop를 돈다.
•
start : 0x20a, end : 0x21c
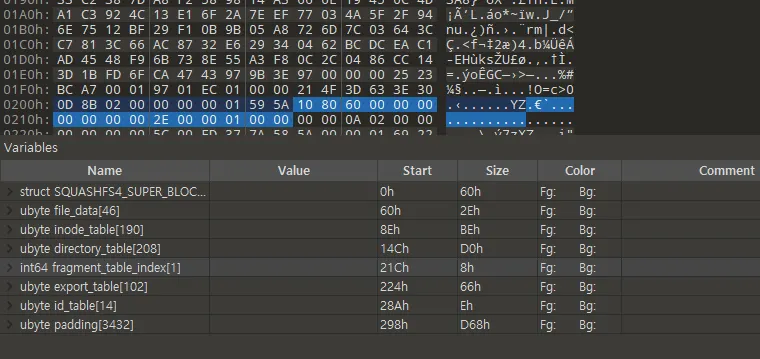
•
0x20a는 0x8010이다.
•
0x8010 * 0x8000 = 0x8000이므로 uncompress byte로 계산되어 압축되지 않았기 때문에 압축해제는 진행하지 않는다.
•
uncompress bytes : 0x10
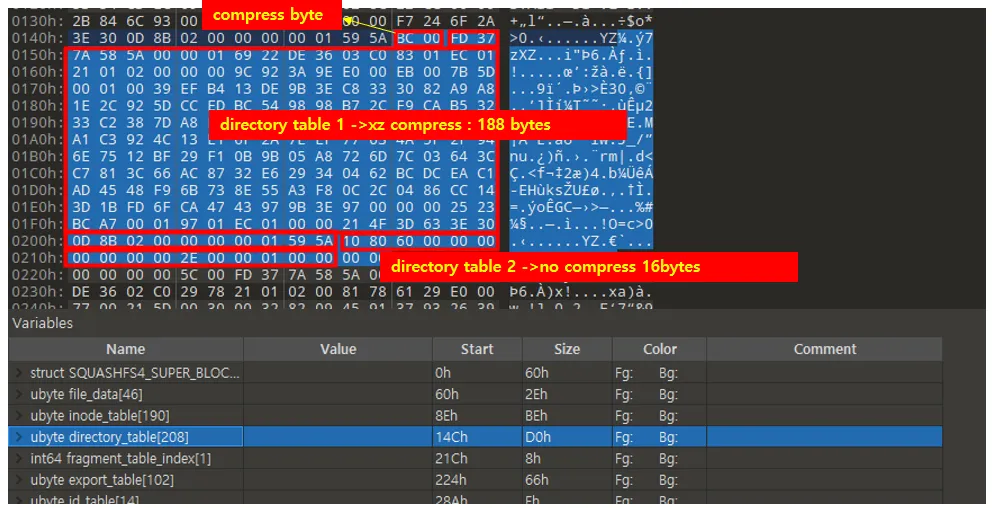
•
정리하면 다음과 같다
•
directory table 1
◦
0xbc → compress bytes : 0x188
◦
xz 압축 사용
•
directory table 2
◦
0x8010 → no compress bytes: 0x10
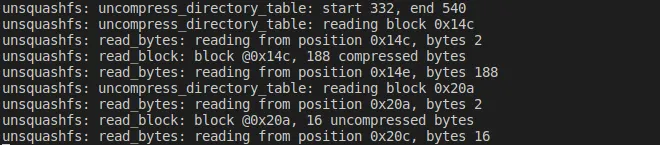
•
uncompress_directory_table 함수 호출 이후 로그
5.5 pre_scan
•
위에서 여태 수행한 작업을 토대로 fs 압축 해제를 진행한다.
•
squashfs_opendir, readdir 등의 함수를 이용하여 fs 내부 내용을 추출한다.
•
squashfs_opendir 함수 내부를 보면 directory_table_start 부터 inode 정보를 가져와 진행을 하는데,
•
현재 directort_table은 이미 압축해제된 상태이다. 압축 해제된 메모리 상태를 보면 다음과 같다.
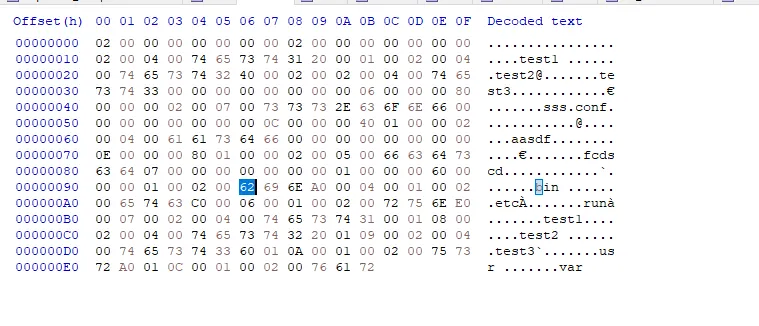
•
압축 해제된 directory_table을 보면 파일들과 폴더들의 이름이 들어가있다.
•
실제 디렉토리는 0x96 offset부터 시작되는데 실제 코드상에서도 0x96 offset부터 디렉토리 명을 추출한다.
6. 결과
unsquashfs: read_bytes: reading from position 0x0, bytes 96
Parallel unsquashfs: Using 1 processor
unsquashfs: read_uids_guids: no_ids 1
unsquashfs: read_bytes: reading from position 0x290, bytes 8
unsquashfs: read_bytes: reading from position 0x28a, bytes 2
unsquashfs: read_block: block @0x28a, 4 uncompressed bytes
unsquashfs: read_bytes: reading from position 0x28c, bytes 4
unsquashfs: read_fragment_table: 1 fragments, reading 1 fragment indexes from 0x21c
unsquashfs: read_bytes: reading from position 0x21c, bytes 8
unsquashfs: read_bytes: reading from position 0x20a, bytes 2
unsquashfs: read_block: block @0x20a, 16 uncompressed bytes
unsquashfs: read_bytes: reading from position 0x20c, bytes 16
unsquashfs: Read fragment table block 0, from 0x20a, length 16
unsquashfs: uncompress_inode_table: start 142, end 332
unsquashfs: uncompress_inode_table: reading block 0x8e
unsquashfs: read_bytes: reading from position 0x8e, bytes 2
unsquashfs: read_block: block @0x8e, 188 compressed bytes
unsquashfs: read_bytes: reading from position 0x90, bytes 188
unsquashfs: uncompress_directory_table: start 332, end 540
unsquashfs: uncompress_directory_table: reading block 0x14c
unsquashfs: read_bytes: reading from position 0x14c, bytes 2
unsquashfs: read_block: block @0x14c, 188 compressed bytes
unsquashfs: read_bytes: reading from position 0x14e, bytes 188
unsquashfs: uncompress_directory_table: reading block 0x20a
unsquashfs: read_bytes: reading from position 0x20a, bytes 2
unsquashfs: read_block: block @0x20a, 16 uncompressed bytes
unsquashfs: read_bytes: reading from position 0x20c, bytes 16
unsquashfs: squashfs_opendir: inode start block 0, offset 448
unsquashfs: read_inode: reading inode [0:448]
unsquashfs: squashfs_opendir: Read directory header @ byte position 130, 8 directory entries
unsquashfs: squashfs_opendir: directory entry bin, inode 0:96, type 1
unsquashfs: squashfs_opendir: directory entry etc, inode 0:160, type 1
unsquashfs: squashfs_opendir: directory entry run, inode 0:192, type 1
unsquashfs: squashfs_opendir: directory entry test1, inode 0:224, type 2
unsquashfs: squashfs_opendir: directory entry test2, inode 0:256, type 2
unsquashfs: squashfs_opendir: directory entry test3, inode 0:288, type 2
unsquashfs: squashfs_opendir: directory entry usr, inode 0:352, type 1
unsquashfs: squashfs_opendir: directory entry var, inode 0:416, type 1
unsquashfs: pre_scan: name bin, start_block 0, offset 96, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 96
unsquashfs: read_inode: reading inode [0:96]
unsquashfs: squashfs_opendir: Read directory header @ byte position 0, 3 directory entries
unsquashfs: squashfs_opendir: directory entry test1, inode 0:0, type 2
unsquashfs: squashfs_opendir: directory entry test2, inode 0:32, type 2
unsquashfs: squashfs_opendir: directory entry test3, inode 0:64, type 2
unsquashfs: pre_scan: name test1, start_block 0, offset 0, type 2
unsquashfs: read_inode: reading inode [0:0]
unsquashfs: pre_scan: name test2, start_block 0, offset 32, type 2
unsquashfs: read_inode: reading inode [0:32]
unsquashfs: pre_scan: name test3, start_block 0, offset 64, type 2
unsquashfs: read_inode: reading inode [0:64]
unsquashfs: pre_scan: name etc, start_block 0, offset 160, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 160
unsquashfs: read_inode: reading inode [0:160]
unsquashfs: squashfs_opendir: Read directory header @ byte position 51, 1 directory entries
unsquashfs: squashfs_opendir: directory entry sss.conf, inode 0:128, type 2
unsquashfs: pre_scan: name sss.conf, start_block 0, offset 128, type 2
unsquashfs: read_inode: reading inode [0:128]
unsquashfs: pre_scan: name run, start_block 0, offset 192, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 192
unsquashfs: read_inode: reading inode [0:192]
unsquashfs: pre_scan: name test1, start_block 0, offset 224, type 2
unsquashfs: read_inode: reading inode [0:224]
unsquashfs: pre_scan: name test2, start_block 0, offset 256, type 2
unsquashfs: read_inode: reading inode [0:256]
unsquashfs: pre_scan: name test3, start_block 0, offset 288, type 2
unsquashfs: read_inode: reading inode [0:288]
unsquashfs: pre_scan: name usr, start_block 0, offset 352, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 352
unsquashfs: read_inode: reading inode [0:352]
unsquashfs: squashfs_opendir: Read directory header @ byte position 79, 1 directory entries
unsquashfs: squashfs_opendir: directory entry aasdf, inode 0:320, type 2
unsquashfs: pre_scan: name aasdf, start_block 0, offset 320, type 2
unsquashfs: read_inode: reading inode [0:320]
unsquashfs: pre_scan: name var, start_block 0, offset 416, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 416
unsquashfs: read_inode: reading inode [0:416]
unsquashfs: squashfs_opendir: Read directory header @ byte position 104, 1 directory entries
unsquashfs: squashfs_opendir: directory entry fcdscd, inode 0:384, type 2
unsquashfs: pre_scan: name fcdscd, start_block 0, offset 384, type 2
unsquashfs: read_inode: reading inode [0:384]
9 inodes (9 blocks) to write
unsquashfs: squashfs_opendir: inode start block 0, offset 448
unsquashfs: read_inode: reading inode [0:448]
unsquashfs: squashfs_opendir: Read directory header @ byte position 130, 8 directory entries
unsquashfs: squashfs_opendir: directory entry bin, inode 0:96, type 1
unsquashfs: squashfs_opendir: directory entry etc, inode 0:160, type 1
unsquashfs: squashfs_opendir: directory entry run, inode 0:192, type 1
unsquashfs: squashfs_opendir: directory entry test1, inode 0:224, type 2
unsquashfs: squashfs_opendir: directory entry test2, inode 0:256, type 2
unsquashfs: squashfs_opendir: directory entry test3, inode 0:288, type 2
unsquashfs: squashfs_opendir: directory entry usr, inode 0:352, type 1
unsquashfs: squashfs_opendir: directory entry var, inode 0:416, type 1
unsquashfs: dir_scan: name bin, start_block 0, offset 96, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 96
unsquashfs: read_inode: reading inode [0:96]
unsquashfs: squashfs_opendir: Read directory header @ byte position 0, 3 directory entries
unsquashfs: squashfs_opendir: directory entry test1, inode 0:0, type 2
unsquashfs: squashfs_opendir: directory entry test2, inode 0:32, type 2
unsquashfs: squashfs_opendir: directory entry test3, inode 0:64, type 2
unsquashfs: dir_scan: name test1, start_block 0, offset 0, type 2
unsquashfs: read_inode: reading inode [0:0]
unsquashfs: create_inode: pathname fuck2/bin/test1
unsquashfs: create_inode: regular file, file_size 11, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name test2, start_block 0, offset 32, type 2
unsquashfs: read_inode: reading inode [0:32]
unsquashfs: create_inode: pathname fuck2/bin/test2
unsquashfs: create_inode: regular file, file_size 11, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name test3, start_block 0, offset 64, type 2
unsquashfs: read_inode: reading inode [0:64]
unsquashfs: create_inode: pathname fuck2/bin/test3
unsquashfs: create_inode: regular file, file_size 11, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_bytes: reading from position 0x60, bytes 46
unsquashfs: writer: regular file, blocks 1
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name etc, start_block 0, offset 160, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 160
unsquashfs: read_inode: reading inode [0:160]
unsquashfs: squashfs_opendir: Read directory header @ byte position 51, 1 directory entries
unsquashfs: squashfs_opendir: directory entry sss.conf, inode 0:128, type 2
unsquashfs: dir_scan: name sss.conf, start_block 0, offset 128, type 2
unsquashfs: read_inode: reading inode [0:128]
unsquashfs: create_inode: pathname fuck2/etc/sss.conf
unsquashfs: create_inode: regular file, file_size 12, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name run, start_block 0, offset 192, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 192
unsquashfs: read_inode: reading inode [0:192]
unsquashfs: dir_scan: name test1, start_block 0, offset 224, type 2
unsquashfs: read_inode: reading inode [0:224]
unsquashfs: create_inode: pathname fuck2/test1
unsquashfs: create_inode: regular file, file_size 9, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name test2, start_block 0, offset 256, type 2
unsquashfs: read_inode: reading inode [0:256]
unsquashfs: create_inode: pathname fuck2/test2
unsquashfs: create_inode: regular file, file_size 9, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name test3, start_block 0, offset 288, type 2
unsquashfs: read_inode: reading inode [0:288]
unsquashfs: create_inode: pathname fuck2/test3
unsquashfs: create_inode: regular file, file_size 9, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name usr, start_block 0, offset 352, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 352
unsquashfs: read_inode: reading inode [0:352]
unsquashfs: squashfs_opendir: Read directory header @ byte position 79, 1 directory entries
unsquashfs: squashfs_opendir: directory entry aasdf, inode 0:320, type 2
unsquashfs: dir_scan: name aasdf, start_block 0, offset 320, type 2
unsquashfs: read_inode: reading inode [0:320]
unsquashfs: create_inode: pathname fuck2/usr/aasdf
unsquashfs: create_inode: regular file, file_size 7, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
unsquashfs: dir_scan: name var, start_block 0, offset 416, type 1
unsquashfs: squashfs_opendir: inode start block 0, offset 416
unsquashfs: read_inode: reading inode [0:416]
unsquashfs: squashfs_opendir: Read directory header @ byte position 104, 1 directory entries
unsquashfs: squashfs_opendir: directory entry fcdscd, inode 0:384, type 2
unsquashfs: dir_scan: name fcdscd, start_block 0, offset 384, type 2
unsquashfs: read_inode: reading inode [0:384]
unsquashfs: create_inode: pathname fuck2/var/fcdscd
unsquashfs: create_inode: regular file, file_size 7, blocks 0
unsquashfs: write_file: regular file, blocks 0
unsquashfs: read_block_list: blocks 0
unsquashfs: writer: regular file, blocks 1
unsquashfs: read_fragment: reading fragment 0
created 9 files
created 6 directories
created 0 symlinks
created 0 devices
created 0 fifos
Markup
복사
•
최종적으로 pre_scan, dir_scan을 통하여 디렉토리와 파일들을 추출하게 된다.
•
실제 squashfs을 만들고 unsquashfs를 디버깅하면서 전체적인 구조정도는 알것 같다.
•
기회가 되면 실제 inode 를 어떻게 처리하는지도 다뤄볼 예정이다.
•
뿐만 아니라 ubifs, jiffs 등도 다뤄보면 좋을 것 같다.

