
NUMA?
numa를 설명하기 앞서 이전에 smp, amp에 대해서 설명한 적이 있다.

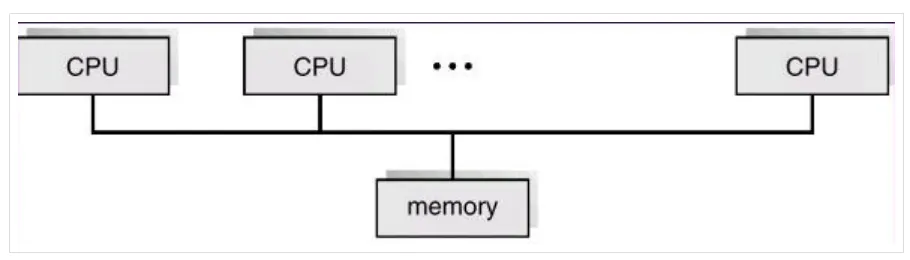
SMP 멀티 프로세싱 환경에서 여러개의 CPU가 하나의 공유된 메모리, 입출력 버스를 사용하는 멀티 프로세싱 아키텍쳐이다.
장점
SMP 시스템은 다중 CPU를 지원하기 때문에 병렬 프로그래밍 쉽고 각 프로세스들의 작업 부하를 효율적으로 분배 할 수 있다는 장점이 있다.
단점
단일 버스를 공유하여 사용하기 때문에 많은 수많은 복수개의 CPU 중 하나의 CPU가 메모리에 접근하기 되면 나머지 CPU들은 block되어 메모리의 처리가 늦어진다. 이를 병목현상이라 부른다.
따라서 SMP 시스템에서 확장되어 NUMA 시스템이 나오게 되었다
SMP 시스템에서의 가장 큰 문제점은 바로 병목현상이였다. 카페 알바로 예를 들어보자. 엄청 큰 카페가 새로 오픈하였고 일할 직업을 100명 뽑았다. 하지만 커피머신은 하나를 사용해서 커피를 뽑는다.
커피를 뽑을 수 있는 사람이 100명이여도 실제 한번에 하나의 커피만을 뽑을 수 있기 때문에 주문이 엄청 밀릴것이다. 그렇다면 커피 머신을 개조해서 한번에 4개씩 커피를 뽑을 수 있게 하면 전보다 훨신 더 많은 양의 일을 처리 할 수 있을 것이다.
바로 이런 단점을 해결한 것이 NUMA 시스템이다. NUM 시스템에서는 CPU를 몇개의 그룹으로 나누고 각 그룹에게 별도의 지역 메모리를 할당해준다
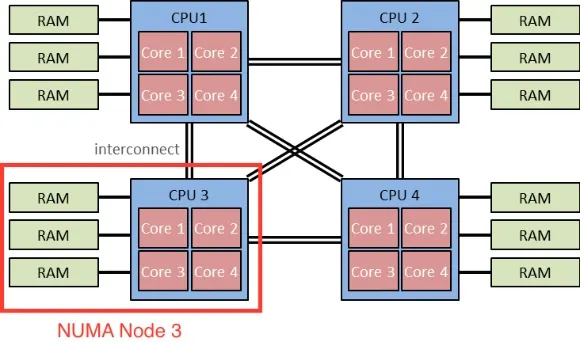
위 그림은 NUMA 구조를 잘 표현한다. 4개의 CPU를 각 그룹으로 나누고 메모리 일부(bank)를 연결 지었다. 이렇게 분류된 CPU-메모리 를 하나의 Node라 지칭하며 동일한 CPU 내의 메모리 접근은 Local Access라 부르고, 서로 다른 노드들간의 메모리 접근을 Remote Access라 한다
좀더 직관적으로 살펴보면 다음과 같다
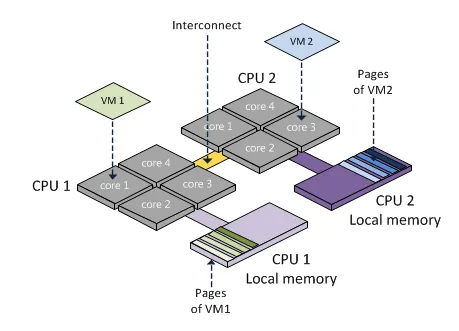
2개의 CPU 그룹에는 각각 구분된 메모리 지역을 할당해준것을 볼 수 있다. Local memory란 실제 CPU 근처에 위치해 있는 메모리이다. (흔히 말하는 RAM)
램은 실제 아래처럼 생겼다
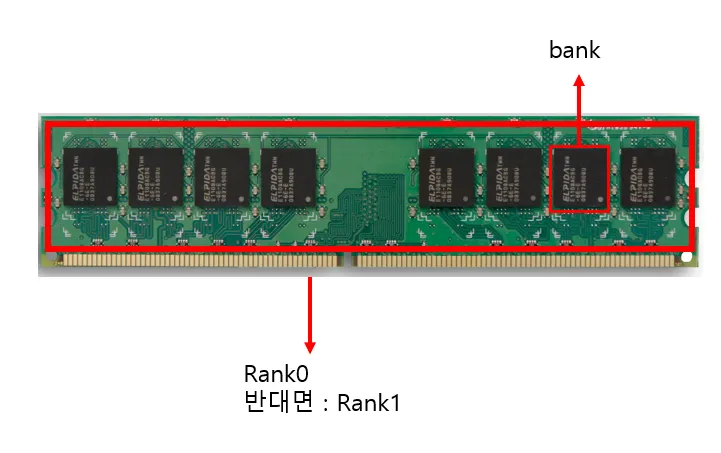
길다란 칩 단면을 Rank라 부르며 Rank에 달려있는 검윽색 놈들을 bank라고 부른다
RAM의 각 뱅크들이 각 CPU들에게 할당된다고 보면 된다. NUMA 시스템은 메모리에 접근하는 시간이 메모리와 프로세서간의 상대적인 위치에 따라 달라진다. 상대적인 위치에 따라 달라진단 의미는 아래의 그림을 보면 쉽게 이해 할 수 있다
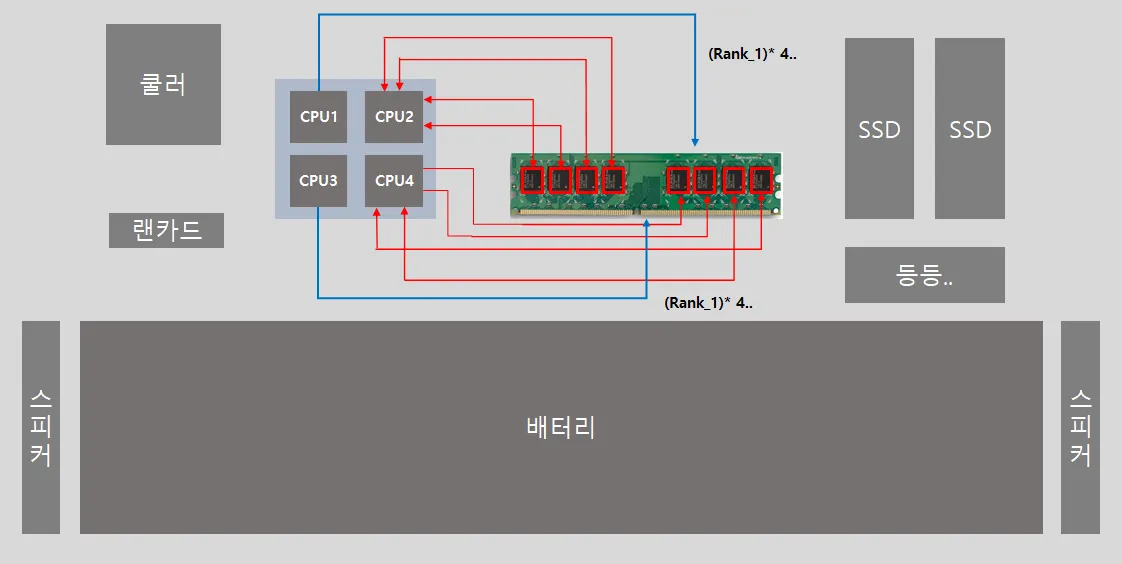
메인 보드 구성도이다. 현재 보이는 메모리 단면이 Rank_0이고 그 뒷면이 Rank_1로 이해하면 된다.
대충 메인보드의 주 부품을 나열해봤다. 저기서 램의 각 뱅크들이 실제 CPU들과 연결되어 있고, 메모리와-CPU 사이의 거리가 가까울수록 메모리에 접근하는 시간이 빨라진다는 의미이다.
2. NUMA 구조
위에서 설명한 NUMA 구조도 결국 코드로 구현되어 관리된다. x86에서 NUMA 시스템을 위한 초기화 설정 부분은 x86_numa_init 함수에서 동작한다
void __init x86_numa_init(void)
{
if (!numa_off) {
#ifdef CONFIG_ACPI_NUMA
if (!numa_init(x86_acpi_numa_init))
return;
#endif
#ifdef CONFIG_AMD_NUMA
if (!numa_init(amd_numa_init))
return;
#endif
}
numa_init(dummy_numa_init);
}
C
복사
https://elixir.bootlin.com/linux/v4.14.62/source/arch/x86/mm/numa.c#L709
x86_numa_init 내부에서 numa_init 를 호출한다. 해당 함수안에서도 또 다양한 함수가 호출되는데 중요 flaw는 다음과 같다.

x86_numa_init ⇒ numa_init ⇒ numa_init_array ⇒ numa_set_node
를 통해서 cpu에 NUMA 노드를 설정한다. (자세한건 소스코드를 분석하길 하면 알 수 있다)
NUMA의 각 메모리 Node들은 struct pglist_data로 관리된다
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
struct bootmem_data *bdata;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* Lock serializing the migrate rate limiting window */
spinlock_t numabalancing_migrate_lock;
/* Rate limiting time interval */
unsigned long numabalancing_migrate_next_window;
/* Number of pages migrated during the rate limiting time interval */
unsigned long numabalancing_migrate_nr_pages;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
/* Number of non-deferred pages */
unsigned long static_init_pgcnt;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this node's LRU. Maintained by the pageout code.
*/
unsigned int inactive_ratio;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
C
복사
결국 하나의 노드는 pg_data_t 구조체를 통해 관리되고 . 이 구조체는 해당 노드에 속해있는 물리메모리의 실제 양(node_present_pages)이나 해당 물리메모리가 메모리 맵의 몇 번지에 위치하고 있는지를 나타내기 위한 변수(node_start_pfn) 등이 정의 되어 있다.
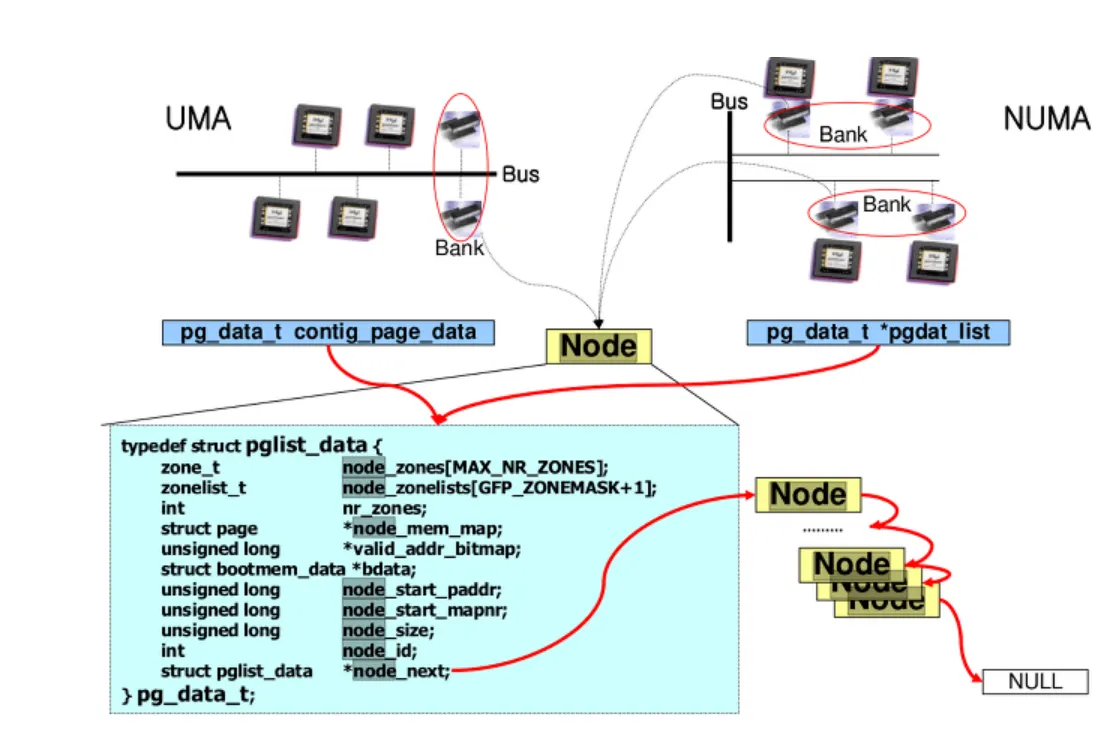
위 그림은 NUMA 구조의 Node를 잘 표현되어 있다
이제 NUMA가 먼지 개념은 잡을 수 있을 것이다. 끝으트으읕
Referrence

