

여태까지 Linux FIie System을 공부하기 위해 먼저 Unix의 File System에 대해서 학습을 했다. 유닉스가 기반이 되야지 후에 설명될 Linux가 더 쉽게 이해가 된다. 이제 Linux의 파일 시스템에 대해서 학습을 해보자.
1. Linux FIie System Virtual File System(VFS)

잠깐 유닉스 파일시스템 복습을 해보자. 파일 시스템은 크게 4가지로 구성된다. 부팅시에 필요한 정보를 담고있는 Bootblock, 파일시스템 전체의 메타데이터를 가지고 있는 Superblock, 각각의 파일들의 메타데이터를 가지고 있는 Inode list, 실제 데이터가 저장된 Data block 이 이에 해당한다.
Superblock의 메타데이터에는 현재 비어있는 sector들을 관리하는 정보도 들어있다고 했는데, 이러한 정보는 어떻게 관리할까?. 이는 파일시스템을 만드는 회사마다 다른다. 어떤 회사는 Bitmap을 가지고 free list들을 관리하고, 어떤회사는 linked list, 어떤회사는 Tree 형태로 관리하게끔 만든다.
이렇게 파일시스템은 각 회사마다 다르기 때문에, 다른 회사의 파일시스템끼리는 호환성이 없다. 위 사진에서 나오는 것 전부다 파일시스템의 종류이다.
이러한 호환성의 문제로 비교적으로 후에 나온 DVD, CD 같은 디바이스들은 표준 규격을 맞춰서 파일시스템을 구성한다.
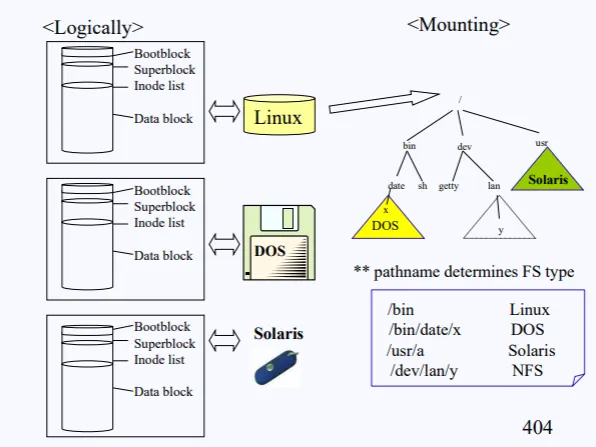
이처럼 옛날 유닉스 환경에서는 오로지 유닉스 파일시스템들만 마운트가 가능했다. 위 사진을 보면 리눅스, 윈도우, 솔라리스 3개의 파일 시스템이 있다.
맨 위꺼를 root 파일 시스템으로 지정한뒤 부팅을 했다고 가정했을때, 다른 파일시스템에 접근하기 위해선 마운트가 필요한데, 지금 3개의 파일시스템의 종류가 다 다르기 때문에 유닉스 환경에서는 마운트가 불가했다.
하지만 리눅스는 다르다. 리눅스는 다른 종류의 파일시스템도 마운트가 가능하다. 어떻게 이게 가능한 것일까?
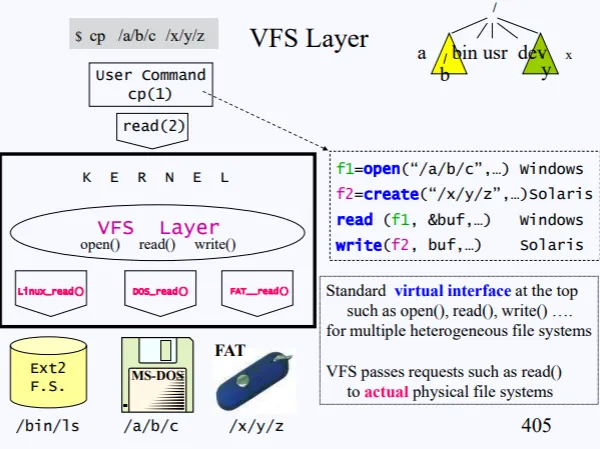
현재 윈도우, 솔라리스 의 파일시스템이 마운트가 되어있다고 해보자.
•
Window : /a/b/
•
Solaris : /x/y/
이 상태에서 cp /a/b/c /x/y/z 명령이 수행되면서, 내부적으로 read, write, open 등의 syscall이 수행될것이다. 헌데 linux 파일시스템을 open하는거랑 윈도우의 파일시스템을 open하는거랑 내부 구현 로직이 다르기 때문에 유의해야한다.
따라서 리눅스에선 이러한 각기 다른 파일 시스템을 서포팅하기 위해 VFS Layer라는 걸 추가했다.
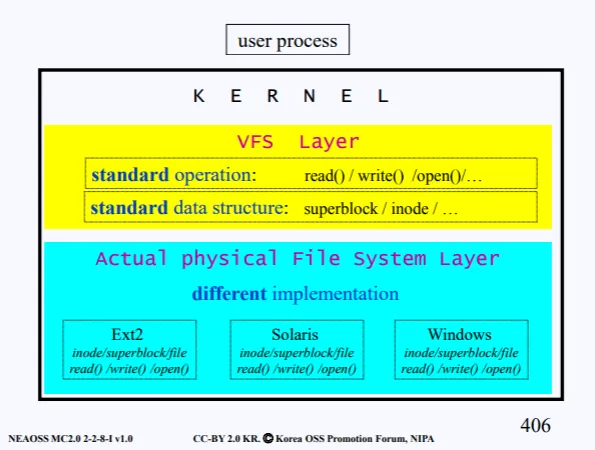
리눅스에선 어떠한 파일시스템이 사용되든간에 VFS Layer를 통하게 되어있다.
VFS는 파일시스템 인터페이스를 유저공간 프로그램에 제공하기 위해 구현된 커널의 서브 시스템이라고 볼수 있다. VFS에서는 서로 다른 디바이스의 서로 다른 파일 시스템에 대해 읽고 쓰는 작업을 하기 위해 표준 시스템 콜을 사용할 수 있게 해준다.
VFS는 추상화 계층이므로 실제 구현을 Actual Physical File System layer에서 수행한다. 여기에는 각각의 파일 시스템에 따른 구현로직이 들어있다.

정리를 해보자.
•
리눅스는 여러개 다양한 파일시스템을 서포트 해준다
•
모든 파일 시스템을 위해서 표준 인터페이스를 제공한다(VFS)
•
VFS는 표준 인터페이스이다 - VFS standard objects
◦
standard data structures
◦
standard operations
그럼 이제 VFS standard objects 에 대해서 좀더 자세히 알아보자
2. Linux VFS Standard Objects

리눅스는 파일시스템이 윈도우꺼든, IBM꺼든 상관없이 4가지의 Objects들을 정의한다.
1.
Superblock object : 파일 시스템 전체에 대한 structure
2.
inode object : 각각의 파일에 대한 structure
3.
file object : 실제 데이터
4.
dentry object : pathname에 매핑된 inode 정보가 담김
1 ~ 3 은 전에 설명을 했으니 dentry object 대해서만 자세히 설명하겠다.
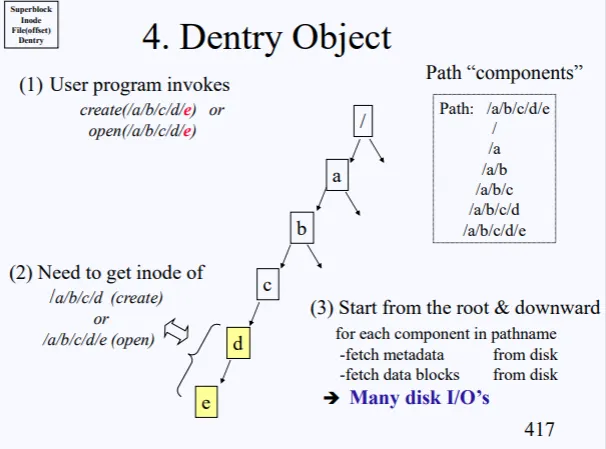
현재 open(/a/b/c/d/e) 를 하려고한다. 그럼 디스크에서 루트부터 시작해서 루트의 inode를 가져오고, inode의 data-block을 보고 또 a inode를 가져오고 쭉쭉 진행해서 결국 e에대한 inode를 얻었을것이다.
⇒ 이러한 과정을 Path Components 라고 한다.
결국 루트로부터 /a/b/c/d/e 파일을 open하기 위해서 많은 작업을 하게 되고, 이는 수많은 disk I/O가 발생하고, 개발자들은 이러한 단점을 해결해야 했다.
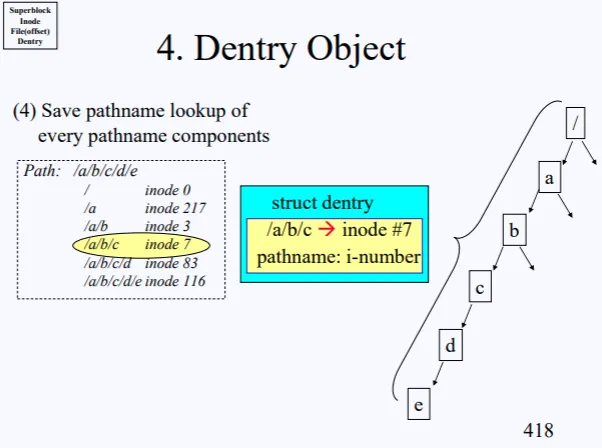
수많은 disk I/O가 발생한다는 소리는, 이렇게 생각하면 된다. 우리는 보통 특정 디렉토리 파일 영역에서 주로 작업을 하는데, 거기에 접근하거나 read or write를 하기 위해 또 상위 루트로부터 path component 를 하게되면 /a/b/c/ 로 접근하기 위해 또 / → /a → /a/b → /a/b/c 이렇게 inode에 접근해서 지랄을 해야한다.
이게 바로 많은 disk I/O가 걸린다는 의미다. 따라서 path component 를 통해 특정 filepath들의 inode를 가져올때마다 path-inode 정보를 구조체 형태로 저장하는데 이를 dentry structure라고 부른다.
즉 dentry object가 Dentry Cache에 저장된다고 생각하면 된다. path-inode에 대항 정보를 캐시로 저장을 해놓는것이다.
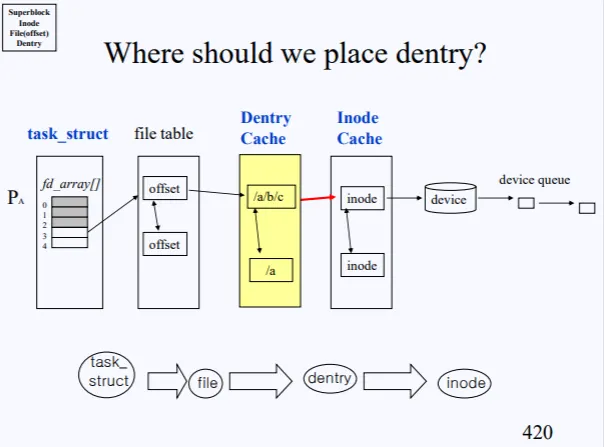
노란색 부분이 Dentry Cache이다. file table 뒤에 위치해 놓음으로써 캐시의 역할을 한다. 하지만 캐시에 저장되는 dentry object 정보가 무수히 많아지면 이 역시 오버헤드가 발생할수 있으므로, 용량을 정해놓고 용량이 꽉차면 오래된 object를 빼거나 하는 식으로 관리를 하게 된다.
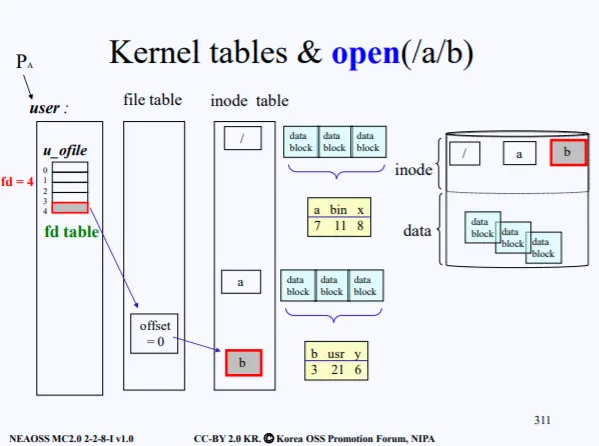
캐시가 필요한 이유를 다시한번 전 강의의 사진을 통해 이해해보자. 전 강의에서 open(/a/b) 를 하기 위해 루트로부터 a, b 파일의 inode 정보를 가져오고, 이 정보는 inode table에 저장되었다.
여기서 b가 아니라 a 파일에서 또 어떤 작업을 하려면, inode table에서 루트를 찾고 루트의 data-block에서 a의 inode-number를 찾고 이게 현재 inode table에 있는지 확인하고 .. 이렇게 진행된다.
하지만 캐시 테이블이 file table 과 inode table 사이에 존재한다면, /a로 한번에 접근할수 있다. ㅇㅋ?
3. /proc file system
여태 리눅스에서는 다양한 파일 시스템을 지원하기 위해 VFS 라는 추상화 계층을 만들었다고 했다. 이번에는 그 VFS 하위에 존재하는 proc 라는 파일 시스템에 대해서 설명하고자 한다.

/proc 파일 시스템은 소프트적으로 생성되는 dynamic한 파일시스템이라고 불린다. 이 말뜻은 다음과 같이 이해하면 된다.
리눅스에서는 모든걸 파일로 취급하기 때문에 ls /proc 하면 proc 디렉토리 파일 하위에 존재하는 파일들이 다 보인다. 하지만 proc 하위에 존재하는 파일들은 실제 파일이 아닌, 특정 커널 함수를 호출시키는 파일이다. 실제 한번 확인을 해보자.
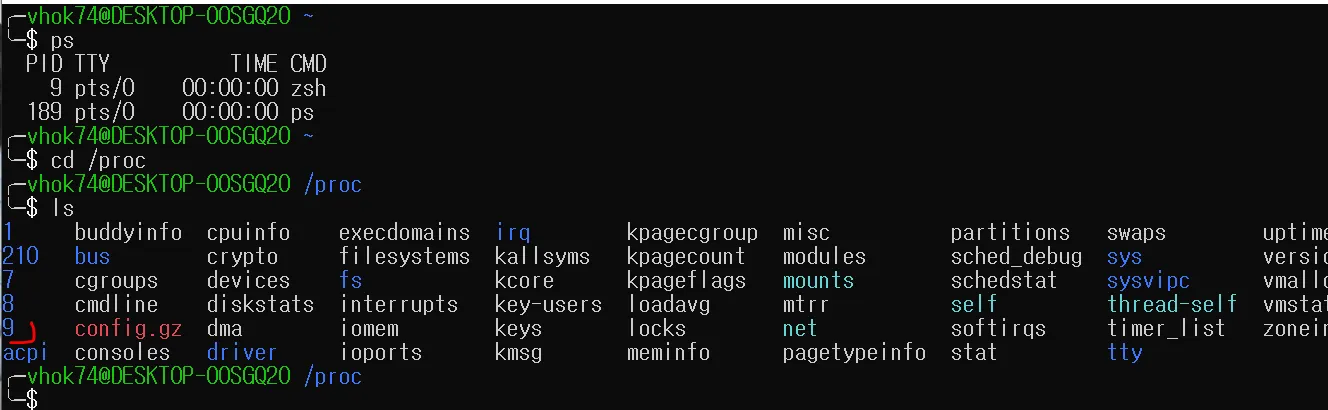
ps 명령어를 치면 현재 9번 pid가 내 zsh 프로세스인걸 확인할수 있다. /proc로 이동해서 ls를 출력해주면 다양한 정보가 나온다.
현재 내 zsh 프로세스는 9번이고, 해당 폴더로 들어가보면 zsh 프로세스에 대한 정보가 나온다. 여기에 나오는 모든 파일들은 실제 파일이 아닌, 커널함수를 호출시키는 놈이라고 생각하면 된다.
예를 들어 meminfo 라는 파일이 현재 있다. cat meminfo 명령어을 치면 meminfo 파일에 들어있는 내용을 출력시켜주는게 아닌, 현재 내 메모리의 정보를 커널 내부의 함수 호출을 통해 출력시켜주는 것이다.
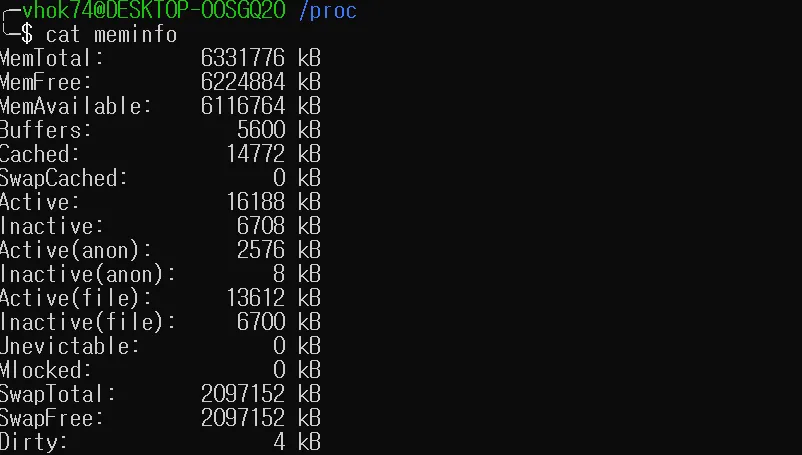
이번엔 현재 내 zsh 프로세스의 정보가 들어있는 9 폴더로 들어가보자.

해당 폴더에는 zsh 프로세스의 모든 정보를 얻을수 있는 파일들이 있다. 각 파일들에 실제 내용이 들어있는게 아니라 해당 파일을 사용할때 커널 내부의 특정 함수가 호출되면서 그 정보를 보여주는 것이다. cat maps을 해보면, 현재 내 zsh 프로세스가 메모리에 매핑된 주소 정보를 커널 함수가 호출되면서 나한테 보여준다.
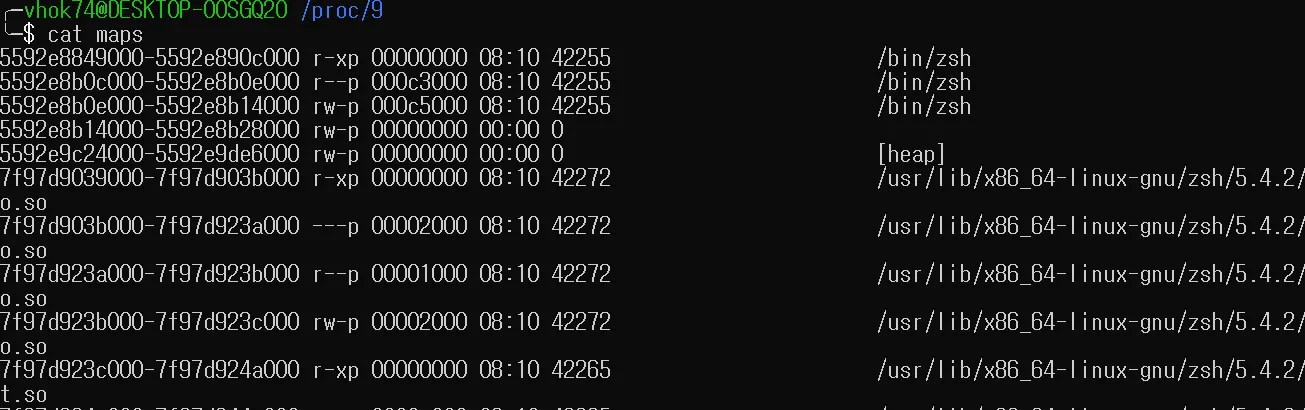
따라서 이러한 /proc 파일 시스템을 Special file system이라고 부른다. 해당 파일 시스템 하위에는 어떠한 미디어나 디스크 파일이 들어있는게 아닌, 각각이 커널 함수로써 그 기능을 한다. 위에서 설명한 cat이나 ls 이외에도 write 같은 걸 통해 실시간으로 커널 파라미터를 변경할수 있다. 물론 권한이 존재한다는 가정헤 말이다.
4. Process Address space
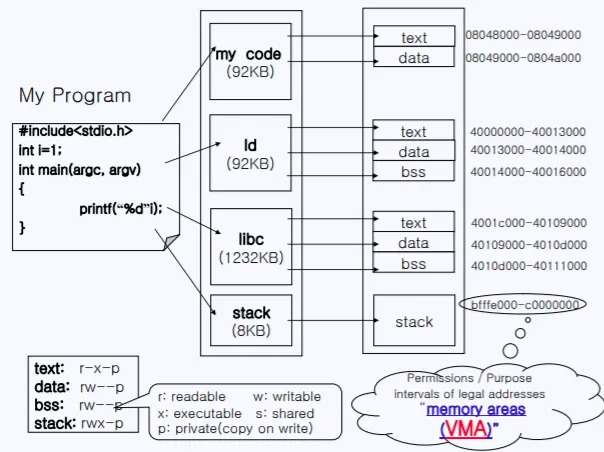
실제 내가 짠 코드를 컴파일해서 실행을 하게 되면 메모리에 위와 같은 형태로 올라간다. 코드영역, 동적 링킹이면 런타임시에 올라오게 되는 라이브러리 영역, static이면 아예 컴파일시에 올라오는 라이브러리, 스택 등등이 올라간다.
이러한 주소 영역은 Process Address space라고 부르고 각 주소 영역을 memory areas = VMA 라고 부른다. 실제 물리 메모리가 아닌, 가상 메모리 주소이기 때문이다.
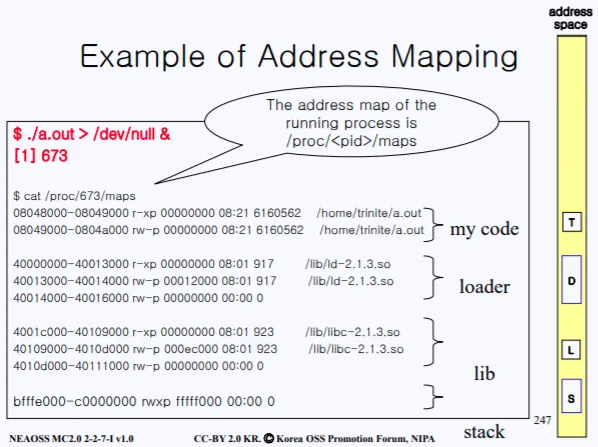
실제 maps을 보면 저렇게 구성되어 있다.

이러한 매핑된 주소의 정보는 PCB에 들어있다. PCB는 6가지로 분류되어있다고 했는데 그중 mm 구조체에 해당 정보가 들어가 있다.
참고로 mm에 직접 들어가 있는건 아니고 mm 포인터를 따라가보면 거기서 실제 메모리 관련 구조들을 찾을수 있다.
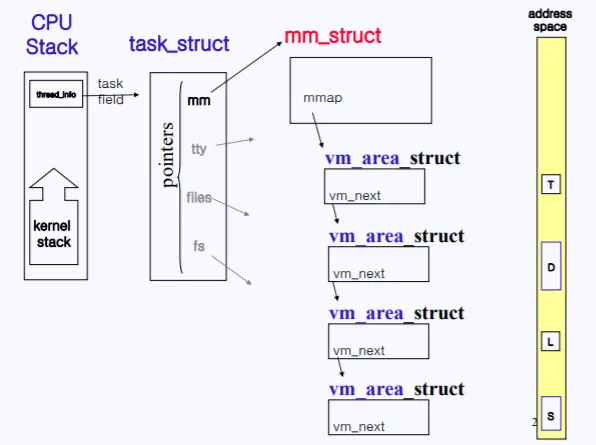
task_struct 즉 PCB 내부의 mm 구조체 포인터를 따라가보면 현재 프로세스가 사용중인 메모리에 관련된 정보들이 들어있다. 그렇기 때문에mm_struct에는 사진 오른쪽과 같은 address space 에 대한 정보도 들어있다.
실제 mm_struct가 메인 메모리에 들어있고, 그 안에 vma 주소들의 리스트가 들어있다. 따라서 mm_struct를 통해 현 프로세스에서 사용중인 vma_area 주소들을 접근할수 있다.

위 사진이 실제 mm_struct의 내용이다. mm_struct는 메인 메모리에 존재하면 mm_struct의 mmap 필드를 통해서 vm_area_struct에 접근할수 있다.
5. 정리
이번 강의부터 실제 Linux의 파일시스템의 간략한 구조에 대해서 학습하였다. 그다음 프로세스가 메모리에 올라올때의 매핑되는 주소에 대해서 학습을 하였다. 다음시간에 바로 위에서 설명한 VMA를 이어서 설명하고 마무리가 될것같다.
5. VMA
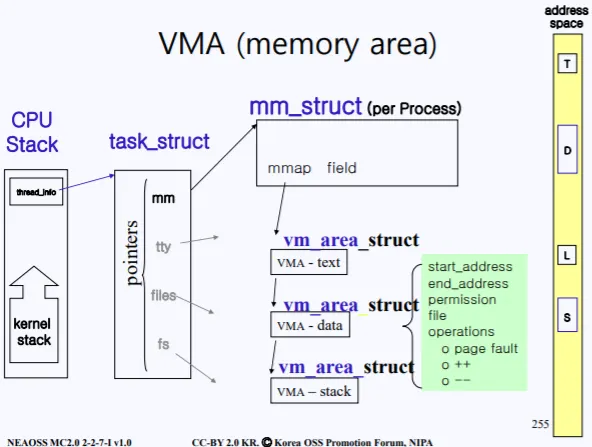
VMA에 대해서 다시한번 설명을 해보자. 현재 실행중인 프로세스마다 각각의 task_struct 즉, PCB가 존재하고 PCB의 mm struct를 따라가보면 여러 필드가 있고, 그중 mmap 필드를 통해 현재 프로세스가 사용중인 메모리의 정보를 알수 있다.
실제 mmap 필드는 vm_ares_struct 현태로 되어있으며 각 vm_area_struct가 우측 노란색 address space 중 흰색 영역의 정보를 가지고 있다.
vm_aread_struct에는 현재 예를 들어 코드 영역이면 코드영역의 시작주소, 끝 주소, 권한, 등의 정보가 들어있다.
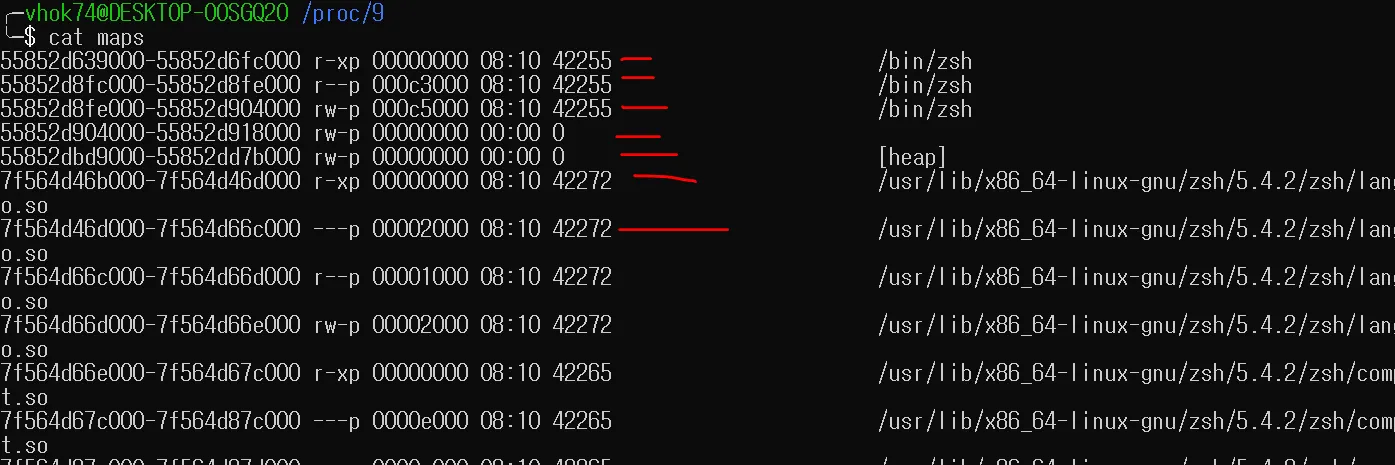
저 한줄한줄이 vm_area_struct 필드에 담겨있다.

