

목차
2장. 핵심 방어 메커니즘
1. 사용자 접근처리
애플리케이션에서 필요로하는 주요 보안 요구사항은 결국 데이터나, 특정 기능에 대한 사용자의 불법적인 접근을 통제하는 것이 주다. 허용된 사용자가 정상적인 방법으로 특정 데이터 및 기능에 접근하는건 당연히 가능해야함. 하지만 불법적인 루트로 허용되지 않은 사용자가 접근하는 것은 막아야함.
1) 인증
대표적인 인증은 로그인 이 있음. 로그인은 예전부터 사용된 인증방법임. 보안이 올라가면서 로그인에서 발생할 수 있는 인증메커니즘이 고도화됨.
2) 세션관리
사용자를 위해 세션을 만들어주고, 만들어준 세션을 확인하는 용도로 토큰을 발행해줌. 세션 자체는 서버에 할당돼 있는 데이터임. 요게 많아지면 서버에 부하가 발생할수 있음. 보통 세션 토큰은 HTTP 쿠키를 사용해서 전송함.
요 세션 관리 메커니즘은 토큰에대한 의존도가 높음. 따라서 요 토큰이 만약 탈취되거나 그러면, 다른 사용자로 위장가능. 따라서 세션토큰을 사용하지 않고 사용자를 확인하는 다른방법들도 사용됨
3) 접근 통제
말그대로 접근을 통제하는 것임. 사용자 인증, 세션관리가 정상적으로 동작했다면, 서버에서는 사용자를 정상적으로 관리가 가능함. 따라서 사용자의 권한을 체킹하여 접근을 통제할 수 있음.
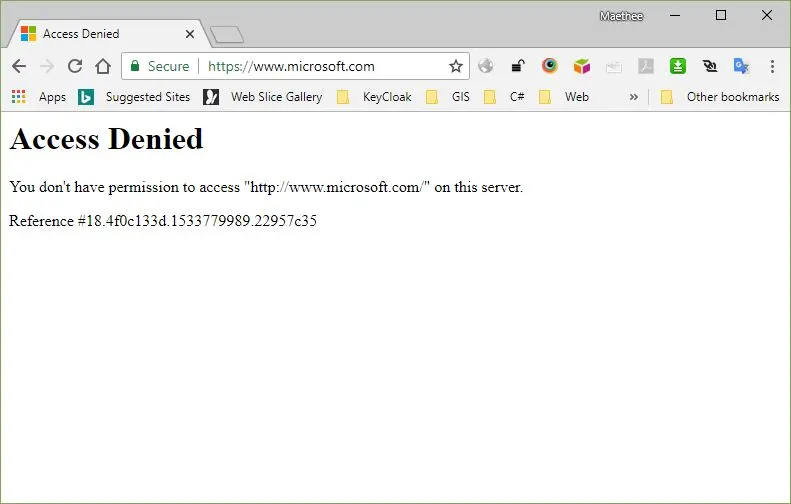
요런 게 접근통제로 볼수있음. 권한이 없음.
2. 사용자 입력 값 처리
사용자가 입력한 값을 안전하게 처리하는 것을 입력 값 검증이라고 함. 일단 사용자는 입력은 어떠한 값도 할 수 있음. 보안적인 측면이 들어가면 입력한 값을 어떻게 처리를 해서 공격자의 위협을 막는냐! 그 문제인거같음
1) 다양한 입력 값
사용자의 입력값을 검증하지 않는다면 아주 주옥됨. 따라서 애플리케이션에서 입력값의 엄격한 검증이 이루어져야함.
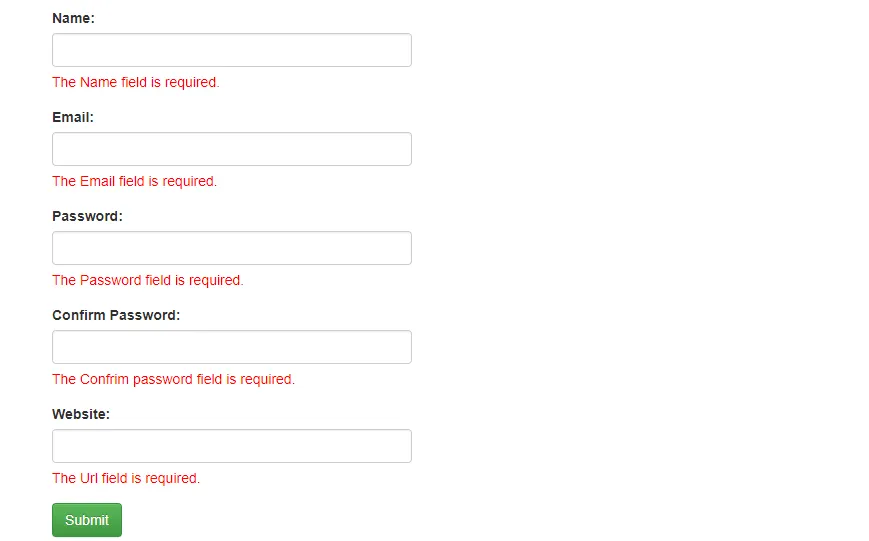
코드이그나이터 프레임워크에서 보면 form_validation 이라는 기능이 있음. 즉, 입력값을 검증할수 있는 라이브러리임. 주어진 조건에 부합하지 않는 입력값이 들어오면 저렇게 경고를 줌. 입력값에 대한 규칙을 통해 검사를 함.
또한 조심해야하는건, 애플리케이션은 사용자가 입력한 값 뿐만 아니라, 브라우저를 통해 전달되는 다양한 데이터 항목을 받아드림. 일반적인 사용자는 저 값들을 건드릴 필요가 없지만, 공격자는 이부분을 타겟으로하여 공격을 시도할 수도 있음. 히든필드값은게 바로 그런거임.
따라서 애플리케이션은 저러한 데이터들도 아주 세밀하게 검사해야함.
2) 입력 값 조작에 대한 처리방법
•
블랙리스트
알려진 문자열이나 특정 패턴을 포함하는 블랙리스트를 만들고, 해당 리스트에 걸리는 입력 값을 처리하는 방법이다. 하지만 해당 방법을 우회하는 루트는 매우 많다. 따라서 안좋음.
select가 막히면 Select로 하면되고, or1=1— 가 막히면 or2=2—로 하면되고 요런식으로..ㅋ
또한 특정 키워드를 막는 필터가 있으면 수식 사이에 비표준 문자를 넣거나, 널바이트 공격을 이용할수 있음. C에서처럼 NULL 바이트를 만나면, 거기를 URL의 끝으로 인식하여 뒤에 로직을 필터링안하는 고런 방법도 있다고 함.
•
화이트리스트
요건 올바른 입력 값과 허용되는 문자열만 통과시키는 방법이다.
•
불순물 제거(Sanitization)
불안전한 데이터를 받아들일 필요가 있는 상황에서는 입력값이 페이지에 삽입되기 전에 HTML인코딩을 한다거나 하는 방식을 말한다
3. 확인문제
5. xss 공격을 차단하게 설계된 입력값 검증 메커니즘은 다음과 같다
1.
발견되는 <script>를 제거함
2.
입력값을 50문자로 자른다
3.
입력값에 포함되는 따옴표를 제거함
4.
입력값을 URL 디코딩함
5.
빠진항목이 있다면 1로 돌아감
"><script>alert("foo")</script> 를 삽입하기 위한 방법은?
⇒ 내 답
저대로 넣는다면 1단계에서 바로 걸림. 그렇다면 4번에서 URL디코딩을 진행하기 때문에, ", 1단계를 통하려면 인코딩을 해주면 됨. 3단계도 똑같이 인코딩을 해주면 됨.
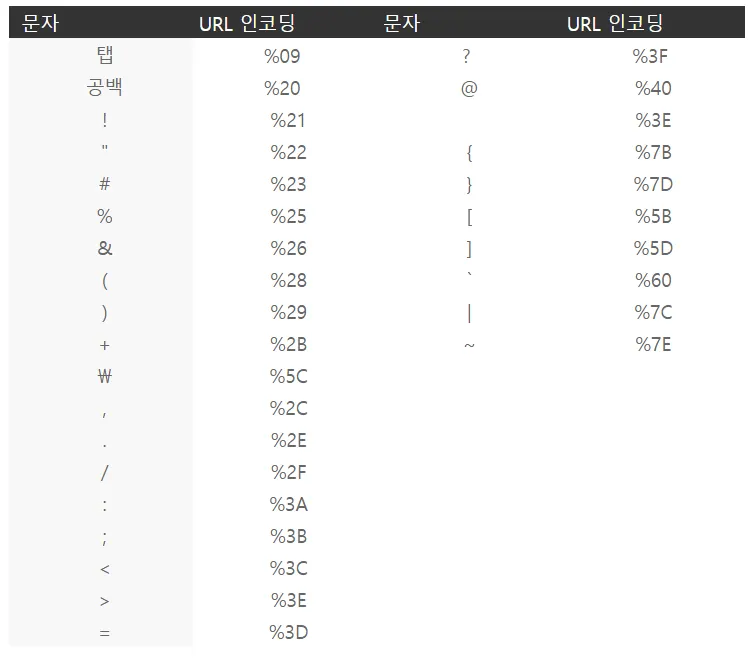
저 표를 참조해서 인코딩을 함
⇒ %22>%3cscript>alert(%22foo%22)</script>
요렇게 입력하면 4단계에서 디코딩이 진행되면서 원래의 쿼리로 돌아감

3. 웹 애플리케이션 기술
1. HTTP 프로토콜
1) HTTP 요청
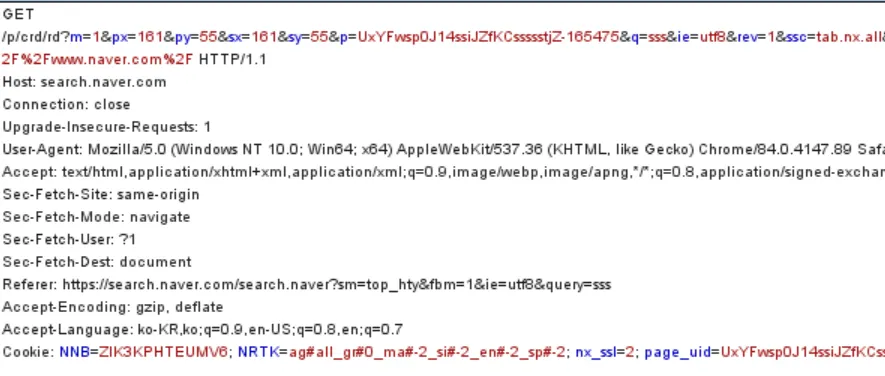
•
Referer 헤더 : 해당 요청이 어디서부터 요청을 받았는지에 대한 URL
•
User-Agent : 브라우저나 기타 클라이언트의 소프트웨어 정보를 보여줌
2) HTTP 응답
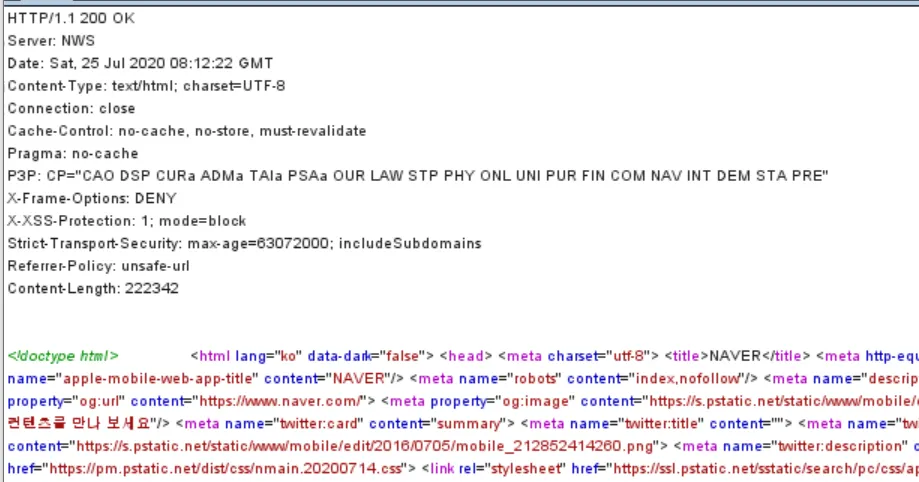
•
Pragma : 브라우저가 응답한 내용을 캐시에 저장하지 않게 함.
•
X-Frame-Options : 현재 응답이 브라우저 프레임에 로드되는지 여부와 어떻게 로드되는지
◦
DENY: "이 홈페이지는 다른 홈페이지에서 표시할 수 않음"
◦
SAMEORIGIN: "이 홈페이지는 동일한 도메인의 페이지 내에서만 표시할 수 있음"
◦
ALLOW-FROM origin: "이 홈페이지는 도메인의 페이지에서 표함하는 것을 허용함"
3) HTTP 메소드
1.
HEAD
GET과 비슷. 하지만 서버가 클라한테 응답할때 바디를 안보냄. GET 요청 전에 자료가 있는지 확인하는 용도
2.
TRACE
진단을 위한 목적. 어떤 프록시 서버가 요청을 조정하는지 여부 판단.
3.
OPTION
특정 자원에 맞는 HTTP 방식을 요청할때 사용. 즉 사용가능한 메소드 식별가능
4) 쿠키
•
Expires : 쿠키 유효 기간
•
domain : 사용할 수 있는 도메인을 나타냄
•
path : 쿠키가 사용할 수 있는 URL 경로를 나타냄
•
secure : 이 속성이 설정되면 쿠키는 HTTPS 요청으로만 전송함
2. 웹기능
1. 서버측 기능
1) HTTP에서 애플리케이션에게 인자를 보내는 방법
•
URL 쿼리 스트링 (GET)
•
REST 스타일 URL의 파일 경로 이용
•
HTTP 쿠키 이용
•
요청 바디에 POST
2) 자바 플랫폼
•
EJB
•
POJO
•
Servlet
•
web container
3) ASP 닷넷, PHP, 루비온레일즈, SQL, XML,
4) 웹 서비스
SOAP (Simple Object Access Protocol)은 일반적으로 널리 알려진 HTTP, HTTPS, SMTP 등을 통해 XML 기반의 메시지를 컴퓨터 네트워크 상에서 교환하는 프로토콜
애플리케이션에서 브라우저에 접근하는 경우 서버 측 애플리케이션이 다양한 백엔드 시스템과 통신하기 위해 SOAP사용하고 있는게 있음.
2. 클라이언트 측 기능
1) HTML, 하이퍼링크, form, css, js
2) Ajax
Ajax의 핵심 기술을 XMLHttpRequest임. 요걸 이용해서 요청을 함. xml로 메시지 데이터를 포맷함
3) Json
임의의 데이터를 직렬화 할때 사용 가능한 데이터 전송 형식. 일반적으로 Json은 Ajax 애플리케이션에서 데이터 전송을 할 때 사용하는 XML 형식의 대안용으로 사용.
사용자가 액션을 취하면, 클라이언트 측의 js는 서버와의 통신을 위해 XMLHttpRequest를 사용해 요청을 보내면, 서버는 데이터가 담긴 응답을 JSON형식으로 전송함.
4) SOP (동일 출처 정책)
브라우저가 사용하는 주요 메커니즘 중 하나. 다른 사이트에서 가져온 콘텐츠에 접근할 수 없게 제한함.
3. 인코딩 스키마
1) URL 인코딩
URL은 아스키 문자 집합에서 출력 가능한 문자들만 포함. url 인코딩 형태는 16진수 아스키와 %를 붙여서 표현함
•
%3d ⇒ '='
•
%25 ⇒ '%'
2) 유니코드 인코딩
3) HTML 인코딩
문제가 있을 만한 문자를 인코딩함
•
< ⇒ '<'
•
> ⇒ '>'
4. 확인문제
1.
OPTION 메소드란?
어떤 method 기능을 제공하는지 체크함. URL에 대한 기능적인 체크동작을 확인함
2.
If-Modified-Since, If-None-Match 헤더는 어떨때 사용되고, 왜 공격할때 필요함?
첫번째꺼는 브라우저가 마직막으로 받은 요청 리소스 시간을 나타냄, 두번째는 서버가 요청된 리소스와 함께 발송한 엔티티 태그를 타나냄. 요게 왜 필요하냐면, 서버에서 캐시 기능을 이용해서 동일한 페이지가 요청들어왔으면 캐시에 저장된 거를 반환해줌. 근데 만약 동일한 페이지에서 수정을 한뒤에 서버에게 요청했는데, 서버는 요청 페이지가 캐시에 있기 때문에 그거를 돌려주면 문제가 됨. 그거를 방지하기 위해서 저 ETAG를 반환해주는 헤더가 필요함. 저거는 해쉬값인데 해쉬값으로 수정여부를 알수 있음.
3.
서버가 쿠키 만들때 secure 플래그는 왜 중요?
secure 플래그는 브라우저가 쿠키를 HTTPS로만 전송하도록 지시하고 절대 HTTP를 통해서는 암호화 되지 않도록 함
4장. 애플리케이션 지도 작성
애플리케이션을 공격하는 방법이 있음. 그냥 무작정 달라붙는게 아닌 마인드 맵을 그리면서 접근해야함. 가장 중요한것은 공격대상을 이해하기 위해 정보들을 모으는 것부터 시작함.
1.
애플리케이션의 콘텐츠와 기능을 확인 및 나열 하기 - 정보수집
2.
클라나 서버에 적용된 기술과 핵심 보안 메커니즘, 기능방식을 검토
3.
공격 가능성을 검토하고, 유력한 대상 영역 확인
4.
공격 진행
크게 요렇게 루틴이 진행됨
1. 콘텐츠와 정보 수집
기본적인 접근방법 → 애플리케이션의 첫 메인 페이지에서부터 모든 링크를 따라 다단계의 기능조사를 하는 것임. 요 기능조사를 위한 자동화 툴도 있음. 직접 만들어도 됨
1) 웹 스파이더링
웹페이지를 요청 → 해당 페이지에 또다른 콘텐츠로의 링크가 있는지를 파싱해서 있으면 다시 요청
요거를 더이상 새로운 콘텐츠가 없을때까지 진행함. 요런 기초적 기능 + HTML 폼을 파싱해서 사전 설정값이나 임의의 설정값을 붙여서 시도를 함. 버프의 target → sitemap 기능이 해당 기능임
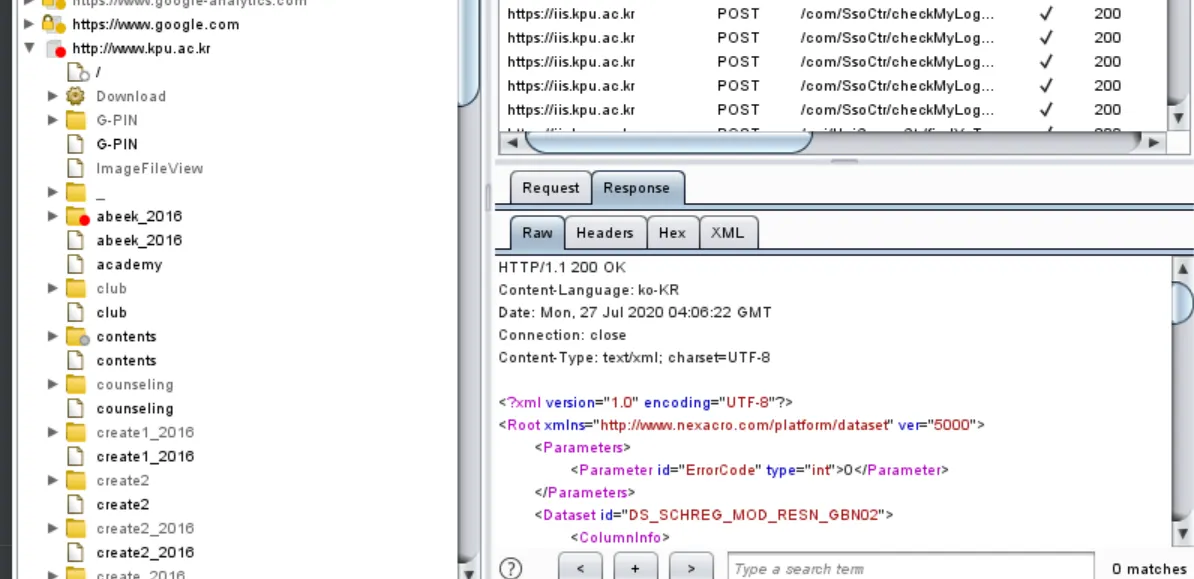
요렇게 sitemap을 확실하지는 않지만 확인 가능. but 요 자동화 도구는 한계가 있음.
•
js를 이용해서 메뉴가 동적으로 생성되는거는 저 자동화 도구에서 제대로 처리되지 않음
•
클라이언트 측 객체에 엮여 있는 링크는 못알아낼 수 도 있음
•
정교한 입력 값 검증이 포함되는 링크들은 인증불가로 인해 다음 단계로 못넘어가고 그 다음 단계의 콘텐츠를 이러한 자동화 툴은 확인 불가
•
자동화된 스파이더링 도구들은 일반적으로 URL을 기반으로 콘텐츠를 확인함. 동일한 URL에 대해서는 반복적인 요청을 안보내게 해버리면, 같은 URL이라도 POST 방식으로 넘어온 값들은 바디 부분에 담기기 때문에 정확한 처리가 불가하고 그 부분을 놓침.
2) User-Directed 스파이더링
버프 pro 버전을 쓰면 크롤링된 요청, 응답을 파싱하여 사이트 맵을 업데이트함. 쫌더 디테일한 부분까지 신경써준다고 생각하면 될듯
스파이더링을 이용한 해킹 단계
1.
프록시 세팅
2.
버프나 자동화 프록시 툴을 이용해서 브라우저에서 발견한 모든 링크, URL을 열어보고, 값 제출하기. 즉 전체적으로 애플리케이션 전체 기능 정보 수집하기
3.
스파이더 도구를 사용할 경우 생성된 sitemap을 보고, 수작업으로 열어보지 않았던 링크중에 있는것들을 확인.
4.
더 세부적인 정보수집을 위해 이미 수집된 콘텐츠를 스파이더링 시작점으로 하여 다시 돌리기
3) 숨겨진 콘텐츠의 발견
디버깅 목적으로 설치되서 사용자에게는 안보이는 기능이나 그런 숨겨진 콘텐츠를 발견하는 것도 매우 중요함.
•
백업파일
•
백업 아카이브
•
테스트용
•
서버에서 제거되지 않은 예전 버전 파일
3-1) 브포
로직은 대충 이케됨.
정보수집을 얼추 했다면 나온 정보를 가지고 파라미터를 브포 때림. 응답코드를 보면서 유추가능함
존재하는 페이지에서는 보통 200 ok가 나오고, 존재하지 않은 페이지는 404 error가 나올텨, but 아닐수 도 있음. 존재하지 않는 페이지에 대해서 미리 정해진 에러 메시지와 함께 200 응답 코드로 응답하게 수정된 방식으로 응답하는 애플리케이션도 있다고 함.
숨겨진 콘텐츠를 강제로 찾아내기 위해 요청을 보내는 과정에서 마주칠수 있는 주요 응답코드
•
302 Found
어떤 페이지에서 로그인 페이지로 자동으로 넘어간다면, 그 페이지는 인증된 사용자들에 의해서만 접근 가능한 것일 수 있음.
•
400 Bad Request
애플리케이션에서는 디렉터리나 파일명을 URL 내에서 쓰는 원칙을 정해둬을수 있음. 이를 못맞춰서 요청하는 경우일 가능성이 큼
•
401 Unauthorized or 403 Forbidden
요청된 리소스가 존재하지만 인증 여부나 권한 여부에 관계없이 접근 불가한 경우를 나타냄. 이를 바탕으로 요청한 디렉토리가 존재하는 것으로 추측할 수 있음
•
500 internal Server error
콘텐츠 확인 과정에서 이 에러 메시지는 일반적으로 해당 애플리케이션이 요청값으로 특정 매개변수 값을 기다리고 있다는 것을 가리킴
해킹 단계
1.
존재 여부를 이미 알고 있는 리소스들에 대해 수작업으로 요청하고 서버가 어케 처리하는지 확인
2.
User-directed 스파이더링을 통해 생성한 사이트맵을 기초 정보로 자동화된 숨음 콘텐츠 찾기
3.
존재할 가능성이 있는 파일이나 디렉토리 찾기. 애플리케이션이 리소스에 대한 요청을 어케 처리하는지 파악했다면 그 점을 이용하기
4.
유효한 리소스 정리 → 후에 이것으로 타겟 선정하면 됨
3-2) 제시된 콘텐츠에서 추측
애플리케이션에서는 내부의 콘텐츠나 기능에 규칙이 있음. 그걸 파악했다면, 정보수집을 할때 좀더 정교하게 수집가능함
3-3) 공개된 정보 이용
3-4 ) 웹 서버 프로그램의 이용
Wikto, Nikto 라는 웹 스캐닝 도구가 있음
3-5 ) 애플리케이션 페이지와 기능 경로
URL에서 수집할수 있는 정보뿐만 아니라 하나의 URL을 통해서 여러 요청이 이루어 질수도있음. 실행할 서블릿, 메소드를 매개변수로 지정해서 전달하는 경우도 있기 때문임.
URL이 아니라 요청되는 매개변수 명을 통해 기능이 정해지는 애플리케이션이라면 콘텐츠 수집 방식을 달리 해야함.
해킹단계
1.
/admin/editUser.jsp 같이 기능에 상응하는 페이지를 요청해서 수행하는것이 아니라
/admin.jsp?action=editUser 와 같이 함수명을 매개변수 값으로 전달하는 경우가 있는지 확인하기
2.
흔이 쓰이는 이름들의 목록에서 관찰된 서블릿이나 메소드이름을 추가해서 요청을 보내보기
3.
적용이 된다면, 콘텐츠 지도를 기능 경로에 맞춰서 구상도를 그려본다
3-5) 숨겨진 변수 발견
해킹 단계
1.
debug, test, hide등 많이 쓰이는 디버깅용 변수명과 true, yes, on, 1 등의 일반적인 값을 여러가지로 조합해서 이미 알고 있는 페이지나 함수에 반복적으로 요청을 보내기. POST 요청인 경우 url 쿼리문과 바디에 매개변수를 동시에 써본다
2.
응답값을 확인하면서 어떨때 어떠한 결과가 오는지 체킹
4) 애플리케이션 분석
이제 정보수집을 했다면, 실 기능을 분석해야함.
1.
애플리케이션의 핵심기능으로, 의도한 대로 조작하면 어떤 다른 일을 수행하는 기능
2.
추가적인 기능 확인
3.
보안 적 측면을 어케 구성했나 확인
4.
사용자의 입력값이 처리되는 로직 확인
5.
클라이언트 측에 적용된 기술(폼, 스크립트, 쿠키 등)
6.
서버 측 기술
7.
서버측 기능과 내부 구조를 수집할수 있는 정보 확인
1) 사용자 입력이 가능한 곳 확인
•
쿼리문
•
URL 쿼리문 내에 포함돼 전달되는 매개변수
•
POST 요청의 바디에 포함되는 매개변수
•
쿠키
•
HTTP 헤더로 특히, User-Agent, Referer, Accept, Accept-Language, Host 헤더들
1-1 ) URL 파일 경로
1-2 ) 요청 매개변수
어떤 애플리케이션은 비표준 포맷으로 쿼리문을 사용하기도 함
•
/dir/file;foo=bar&foo2=bar2
1-3 ) HTTP 헤더
많은 애플리케이션에서 사용자 로그인 기능을 사용하며, 로그인 기능으로 Referer와 User-Agent 등의 HTTP 헤더 콘텐츠에 로그할수 있음. 이런 헤더는 입력 기반 공격의 엔트리 포인트가될 수 있음
일부 애플리케이션은 Referer 헤더에 추가적인 프로세스를 하기도 함. 예를 들어 애플리케이션은 사용자가 특정 검색 엔진을 통해 들어왔다는 것을 알수 있으며, 사용자 쿼리에 맞춘 응답을 제공할 수 있음.
각기 다른 장치(노트붓, 휴대폰 등)로 애플리케이션을 사용자에게 각기 다른 콘텐츠를 보여준다. 이런 기능을 하는 것이 바로 User-Agent 헤더임. 이 헤더를 사용하면 입력 기반 공격도 가능함. 휴대폰에서 User-Agent 헤더를 스푸핑하면 주요 인터페이스와는 다르게 작동하는 간편화된 인터페이스에 접근 가능. 보안 수준이 약한 곳에서 테스트 됐을 가능성도 있으니까 중요함.
2) 서버 측 기술 확인
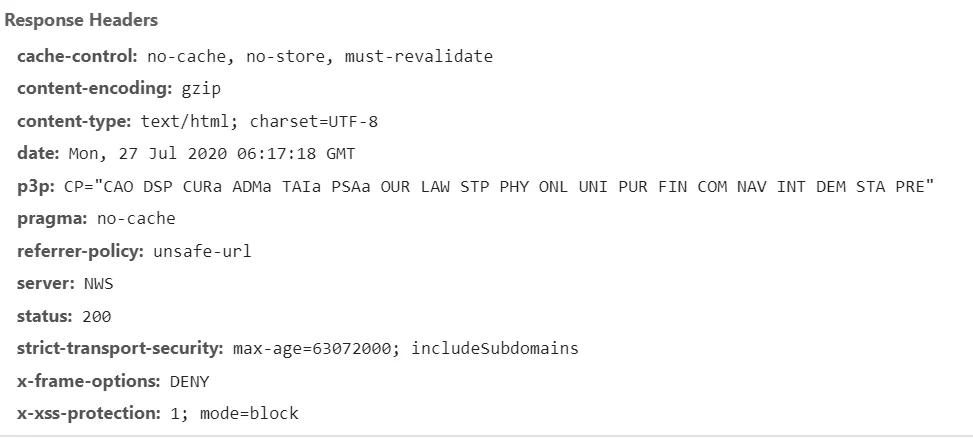
2-1) 배너 가져오기
HTTP server 헤더를 통해 서버에 대한 정보를 유추 가능
2-2) 파일 확장자
URL 내에 사용된 파일 확자자들은 관련되 기능들을 구현하는데 사용돈 플랫폼이나 프로그래밍 언어에 대한 정보가 들어남.
2-3) 디렉토리 명
•
servlet : 자바 서블릿
•
pls : 오라클 애플리케이션 서버 PL/SQL 게이트웨이
•
cfdocsk나 cfide : 콜드 퓨전
•
SilverStream : 실버스트림 웹 서버
•
WebObjects, {function}.woa : 애플 WebObjects
•
rails : 루비온레일즈
2-4) 세션 토큰
•
JSESSIONID : 자바 플랫폼
•
ASPSESSIONID : iis 서버
•
ASP.NET_SessionId : ASP 닷넷
•
CFID/CFTOKEN : 콜드 퓨전
•
PHPSESSID : PHP
2-5) 서드파티 코드 컴포넌트
서드파티란 플러그인 혹은 라이으러리 같은 기능을 말함. 자체 개발을 하거나 구매해서 사용하는 경우가 있음. 이를 통해 로직 파악 및 서드파티 코드 컴포넌트에 취약점이 있으면 해당 기능을 사용하는 곳 전부다 타겟이 될수 있음
3. 서버 측 기능 확인
3-1) 요청 값 분석
3-2) 애플리케이션 행동 추측
3-3) 특이한 애플리케이션 행동 분류
4. 핵심 공격 취약 영역 매핑
여태 말한 정보를 이용하여 attack surface를 확인하고, 취약점을 확인하면 됨.
•
클라이언트 측 검증 : 서버측에는 없을수도..
•
데이터베이스가 연동됨 : SQL 인젝션 가능
•
파일 업로드 및 다운로드 : Path travel, xss
•
사용자가 입력한 데이터를 표시 : XSS
•
동직 리다이렉트 : 리다이렉션과 헤더 인젝션
•
세션 : 토큰 추측, 취약한 토큰 탈취이용
•
외부링크 : Referer 값을 통한 쿼리문과 매개변수 정보 유출
•
서드파티 애플리케이션 컴포넌트 : 알려진 취약점을 이용한 공격
•
웹 서버 소프트웨어 식별 : 알려진 취약한 설정 및 버그 이용
5. 정리
•
정보 수집 - user-directed 스파이더링
•
숨겨진 콘텐츠 찾기 → 브포 + 알아낸 정보이용
•
애플리케이션 주요 기능 및 보안 메커니즘 파악
•
attack surface 조사
6. 문제
1.
https://wahh-app.com/CookieAuth.dll?GetLogon?curl=Z2Fdefault.aspx 이 url을 통해 어떤 서버에 어떤 기술이 적용됐으며, 어떻게 동작함?
•
CookieAuth.dll을 통해 MS의 ISA가 쓰이는걸 알수 있음.

해당 url은 로그인기능이며, 로그인에 성공하면 default.aspx로 리다이렉트됨
2.
http://wahh-app.com/forums/ucp.php?mode=register 여기서 포럼 사용자 목록을 획득하려면?
•
이 url은 phpBB 웹 포럼 sw임을 알려준다.
3.
https://wahh-app.com/public/profile/Address.asp?action=view&location=default
•
.asp 파일로 보아 ms의 asp를 사용함을 알수 있음. action으로view가 있으므로 add, edit, 등과 같은 action을 유추할수 있음. Location에는 default 값이 아닌 다른 값들을 넣으면서 확인할 필요가 있음
4.
Server : Apache-Coyote/1.1
•
서버는 아파치 톰캠을 사용함.
5.
두개의 애플리케이션을 매핑하고 있다. 각 애플리케이션에 대해 /admin.cpf 라는 url을 요청했는데 응답이 다음과 같음. 이 헤더 정보만으로 요청했던 리소스의 존재여부를 파악해보라
HTTP/1.1 200 OK
Server : Miscrosoft-IIS/5.0
Expires: Mon, 25 Jun 2007 14.49.21 CMT
Contenxt-Location: Http://wahh-app.com/includes/error.htm?404;http://wahh-app.com/admin.cpf
Date : Mon, 25 Jun 2007 14.49.21 GMT
Content-Type : text/html
Accept-Ranges : bytes
Content-Length : 2117
--------------------------------------------
Http/1.1 401 Unauthorized
Server : APcahe-Coyote/1.1
WWW-Authenticate: Basic realm="Wahh Administration Site"
Content-type : text/html;charset=utf-8
Content-Length : 954
Data : ..
Connection : close
JavaScript
복사
•
첫번째 응답코드를 보면 200 코드로 보아 요청이 성공했다고 착각할 수 있으나, Loation 헤더를 보면 그 응답이 온 곳을 알수 있다. URL을 보면 error 404를 볼수 있는데, 이는 동적으로 생성한 에러페이즈를 200으로 응답한것으로 유추할 수 있고 첫번째 애플리케이션에서는 해당 리소스가 없다고 유추 할수 있따
•
두번째는 401 상태코드가 보이는데, 이 코드의 의미는 해당 리소스는 존재하지만, 인증이 되지 않은 사용자가 요청했다는 의미이다. 이것을 확인하기 위해 명백히 존재하지 않는 fuck.cpf같은 페이지를 요청하고, 그 응답결과를 확인하면 좀더명확히 리소스의 존재 여부를 구분지을 수 있다.

