
1. What is Memory Zone?
메모리 존이란 유사한 속성들의 페이지들의 집합을 뜻한다. 리눅스에서 커널에서는 물리 메모리 주소 영역(페이지 프레임)을 각 Zone 이라는 단위로 구분하여 관리한다.
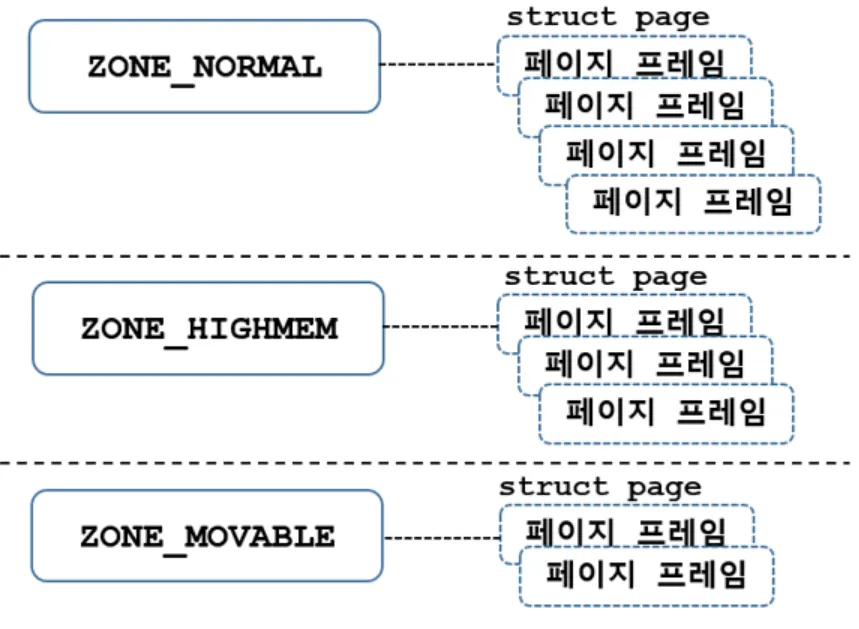
위 사진에서처럼 zone은 유사항 속성을 가지고 있는 페이지 프레임들을 관리하는 자료구조를 지칭한다. zone은 다음과 같은 종류가 있다
1.
ZONE_DMA
2.
ZONE_DMA32
3.
ZONE_NORMAL
4.
ZONE_HIGHMEM
5.
ZONE_MOVABLE
6.
ZONE_DEVICE
실제 커널 소스코드에선 열거체로 zone의 종류가 구성되어있다
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
C
복사
2. ZONE_DMA & ZONE_DMA32
ZONE_DMA를 설명하기 앞서 DMA가 무엇인지 간단하게 알아보자.
DMA란 Direct Memory Access의 약자로서 데이터를 읽거나 쓸때 CPU의 개입없이 DMA Controller가 대신 그 역할을 수행하는 것을 의미한다.
CPU가 관여하여 처리하게 되면 그동안에는 CPU가 다른일을 처리하지 못하기 때문에 속도가 느려지는 단점이 있다. 하지만 DMA를 이용하게 되면 CPU는 DMAC(Direc Meory Access Controller)에게 일을 시작해라! 라는 신호만 주고 다시 자기 일을 한다.
데이터 처리는 DMAC에 의해서 수행되고, 처리가 다 끝나면 인터럽트를 발생시켜 CPU에게 그 결과를 돌려준다. 다음의 그림은 DMA가 적용되지 않는 구조이다
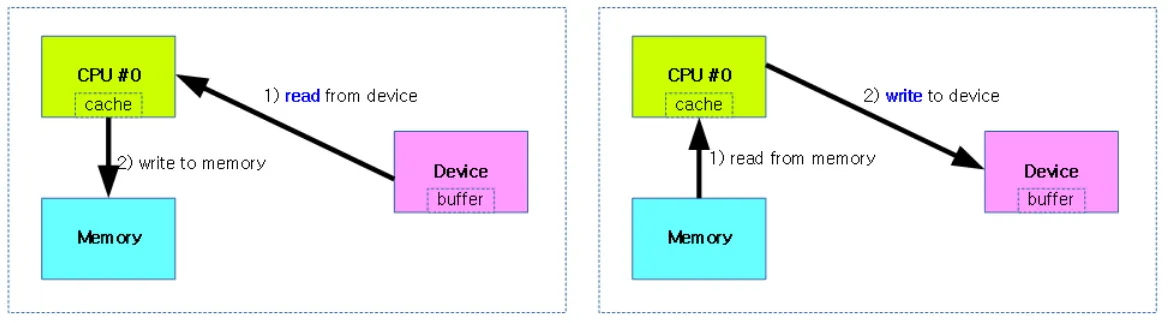
DMA가 적용되지 않은 Read, Write
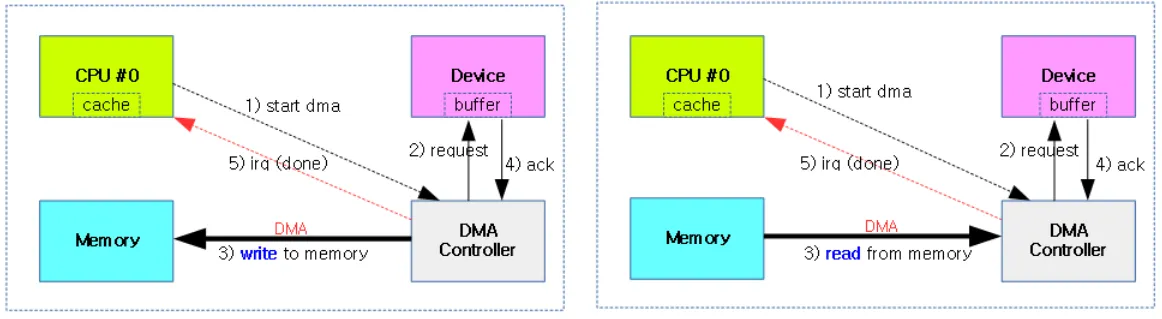
DMA가 적용된 Read, Write
DMA를 사용하게 되면 CPU는 디바이스에게 DMA 시작 신호와 DMA 완료 인터럽트만 수신하고, 직접적으로는 처리에 관여하지 않는다. 단 DMA를 사용하기 위해선 버스 아키텍처에 DMA 컨트롤러 h/w가 구성되어 있어야 한다.
DMA을 사용하는 디바이스들은 일반적으로 버스 주소공간을 사용한다. 유저가 바라보는 주소가 가상 주소 공간인 것처럼 말이다. 따라서 크게 3가지 주소공간 형태가 존재한다
•
가상 주소 공간
•
물리 주소 공간
•
버스 주소 공간
이 중 버스 주소공간 때문에 Zone_DMA, Zone_DMA32 가 생겼다. 일반적으로 CPU가 바라보는 주소공간과 디바이스가 바라보는 주소공간은 다르다. 따라서 DMA를 사용하는 디바이스의 주소 버스가 시스템의 물리 메모리 주소에 전부 접근할 수 없는 경우가 발생한다
예를 들어 32bit 시스템에서 DMA를 사용하는 디바이스에게 할당된 물리 메모리 영역이 존재한다고 해보자. 헌데 디바이스는 16bit의 주소공간만을 지원한다. 결국 16bit로 32bit 시스템에서 할당한 물리 메모리 영역에 접근할 수가 없다.
이런 경우를 대비해서 DMA를 사용하는 디바이스가 시스템이 지원하는 물리 메모리 주소보다 작은 경우에는 별도로 ZONE_DMA를 구성해서 DMA 디바이스용으로 메모리 할당을 제한된 주소 미만으로 만들어놔야 그 DMA 디바이스가 접근할 수 있다.
ZONE_DMA 사이즈는 아키텍처마다 차이가 있다
•
32bit x86
◦
16MB로 고정되어 자동 구성된다.
•
64bit x86-x64
◦
4GB로 고정되어 자동 구성된다.
만약 디바이스의 주소공간이 32bit 주소를 지원한다면 ZONE_DMA를 설정하지 않아도 된다.
x86, x86-64 에서의 ZONE_DMA 사이즈는 고정이고 32bit ARM에서는 동적으로 계산된다

x32 ARM
26bit의 주소공간을 가지는 디바이스 ⇒ 2^26 사이즈로 ZONE_DMA 구성
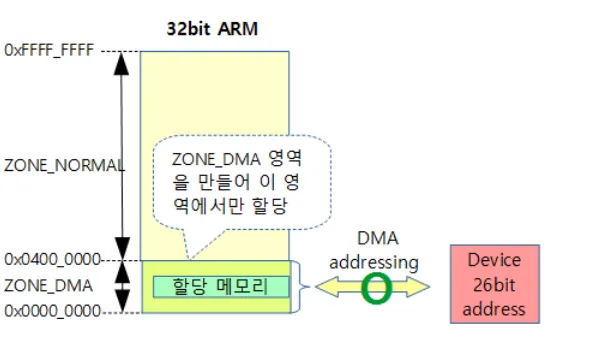
32bit ARM ⇒ ZONE_DMA 사용
ZONE_DMA32 영역은 64bit 시스템에서 32bit 주소를 사용하는 DMA 장치를 위해 사용한다.
(kmalloc의 flag에 GFP_DMA32를 사용하여 ZONE_DMA32 영역에 메모리를 할당할 수 있다.)
3. ZONE_NORMAL & ZONE_HIGHMEM
32bit 시스템에서는 유저 영역과 커널 영역이 구분되어 있다.
User space 3GB /Kernel space 1GB
0x00000000 ~ 0xBFFFFFFF : User space
0xC0000000 ~ 0xFFFFFFFF : Kernel space
유저영역(3G)에서 사용되는 가상 주소들을 다양한 페이징 기법을 통하여 물리 주소로 변환이 되고 실제 메모리에 참조하여 데이터를 읽거나 쓴다.
1Gb 의 공간을 갖는 커널 영역은 다시 3가지로 크게 구분된다
•
ZONE_DMA
•
ZONE_NORMAL
•
ZONE_HIGHMEM
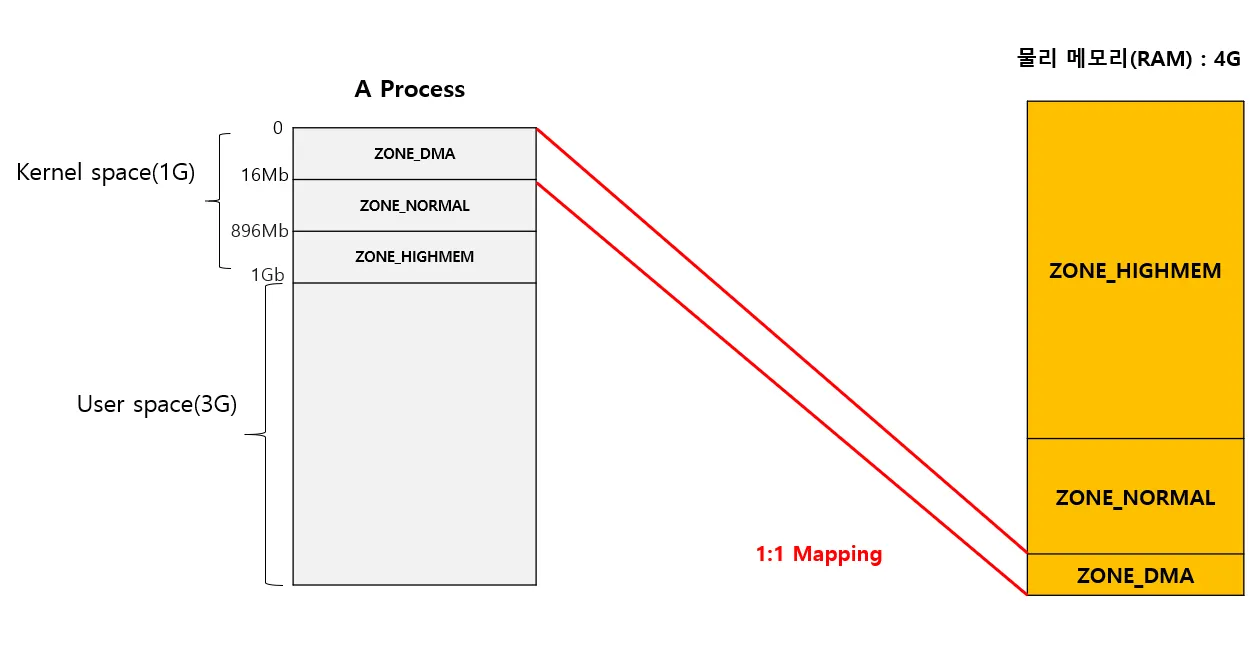
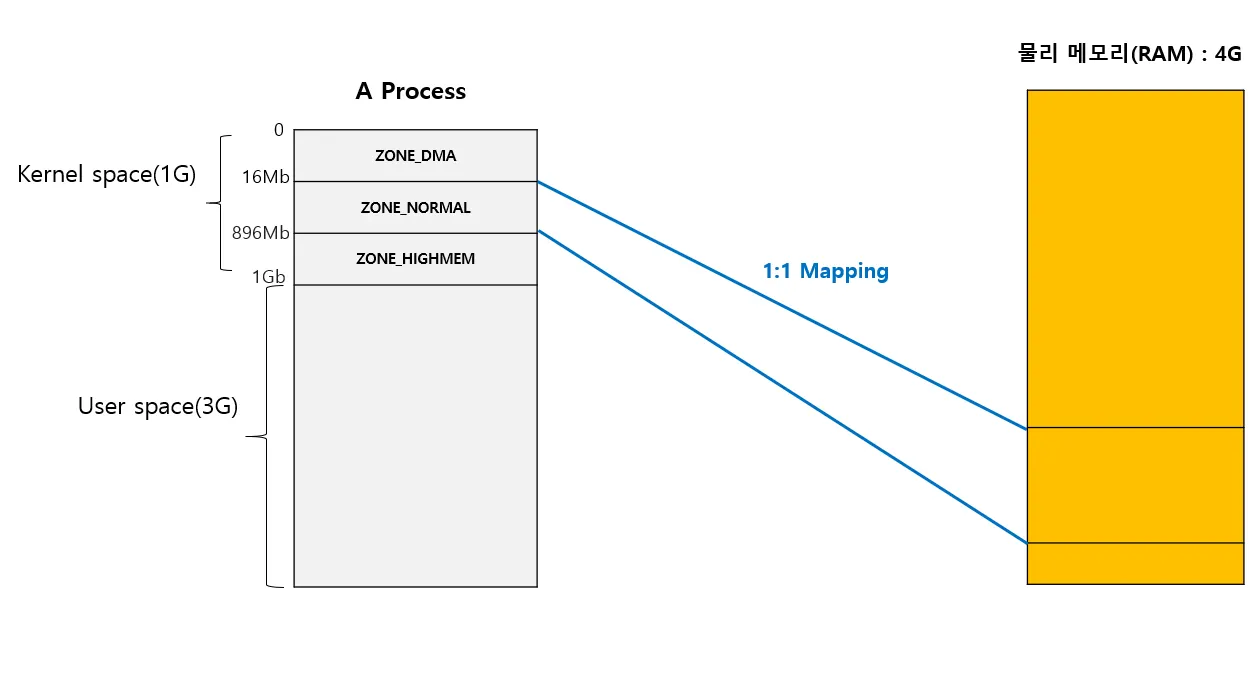
위에서 설명한 ZONE_DMA은 실제 메모리에 1:1로 매핑되어 있는데 idmap 방식으로 매핑되어 가상주소와 물리 주소가 동일한 주소로 표현된다 (가상주소==물리주소)
ZONE_NORMAL 영역은 실제 메모리에 16Mb ~ 896Mb 사이즈 만큼 1:1 매핑되어(imap방식)있다. 해당 존영역으로는 나머지 메모리를 이용하지 못한다. 보통 커널 코드에서 메모리를 할당하면 접근하는 구역이다. 커널에서 메모리를 할당할 때 가장 빨리 할당해 줄 수 있다.
따라서 만일 가상 메모리에서 page fault를 통해 할당하는 물리메모리의 경우, 유저 공간(페이징)과 커널 공간(1:1매핑)에 모두 매핑되게 된다.
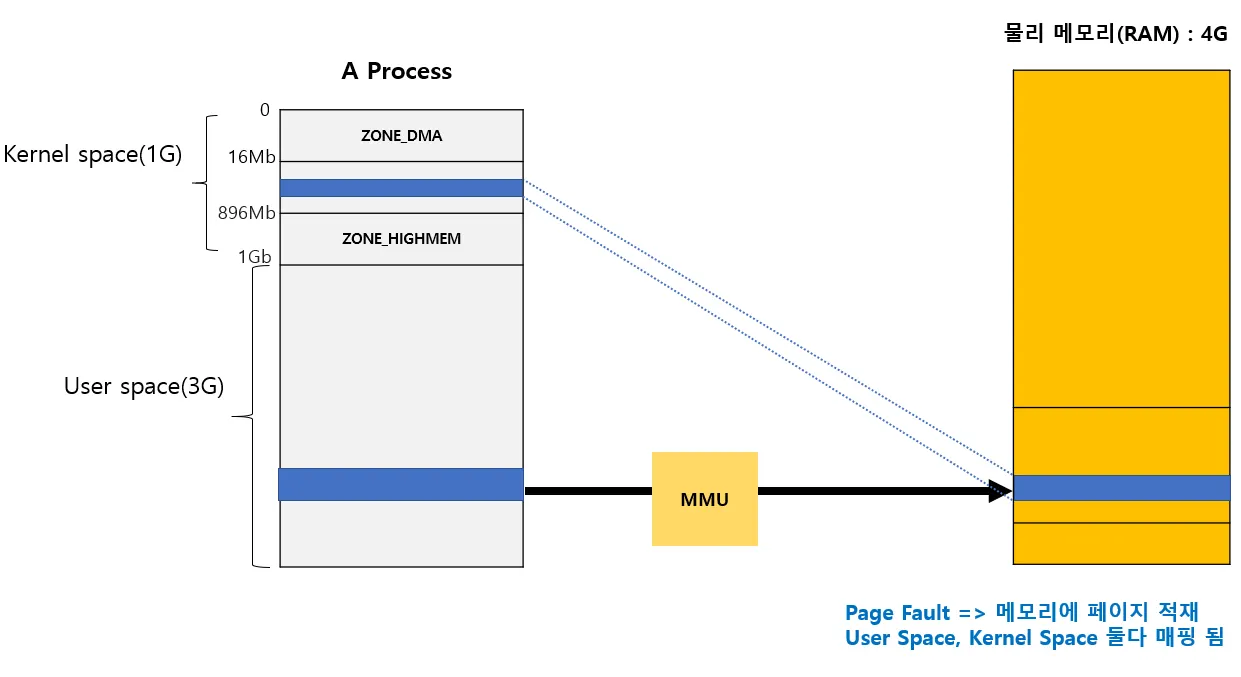
ZONE_NORMAL 영역으로는 사이즈의 제한으로 인해 커널 영역의 접근이 제한된다. 따라서 ZONE_HIGHMEM 영역으로 이를 해결하게 된다.
ZONE_HIGHMEM 이란 898Mb ~ 1Gb 영역에 1G 이상의 매핑 정보를 ZONE_NORMAL 에서 관리 못하는 영역을 관리하게 된다. 이는 사이즈 제한으로 인함이며 64bit의 경우 모든 메모리에 1:1 매핑이 가능하므로 해당 존을 사용할 필요가 없다.
정리하면
•
ZONE_NORMAL, ZONE_DMA
물리 메모리와 1대일 매핑됨(가상주소==물리주소)
•
ZONE_HIGMEM
유저 영역을 Access 하기 위한 용도로 사용되며 Kernel에서 Access 하고자 하는 유저 영역과 Mapping이 일어난후 Access를 할 수 있다.
4. ZONE_MOVABLE
버디 시스템으로 구현된 페이지 할당자가 메모리 파편화를 막기 위해 이 영역을 전용으로 사용한다. 해당 존의 목적은 크게 두가지이다
1.
메모리 단편화 방지
2.
메모리 핫플러그 지원
정리하면 해당 공간의 페이지들은 말그대로 movable하게 설정해 연속적인 메모리 세그먼트를 만들기 용이하게 한다. (원래 커널 공간의 페이지들은 movable하지 않음)
5. ZONE_DEVICE
ZONE_DMA 과 비교했을 때 ZONE_DMA 는 디바이스가 물리 메모리에 대한 접근을 하고자 하는 것을 위한 영역이라면 ZONE_DEVICE 는 대용량의 디바이스에서 사용하기 위한 영역이다.
6. ZONE Structure
커널에서 메모리 zone 별 세부 정보는 pglist_data 구조체 변수의 node_zones 필드에서 확인할 수 있다
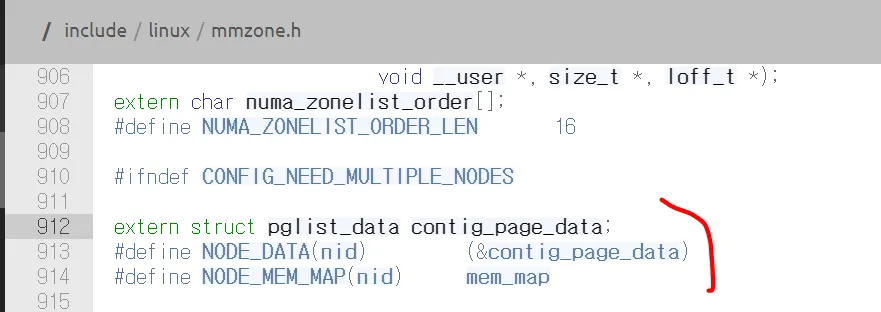
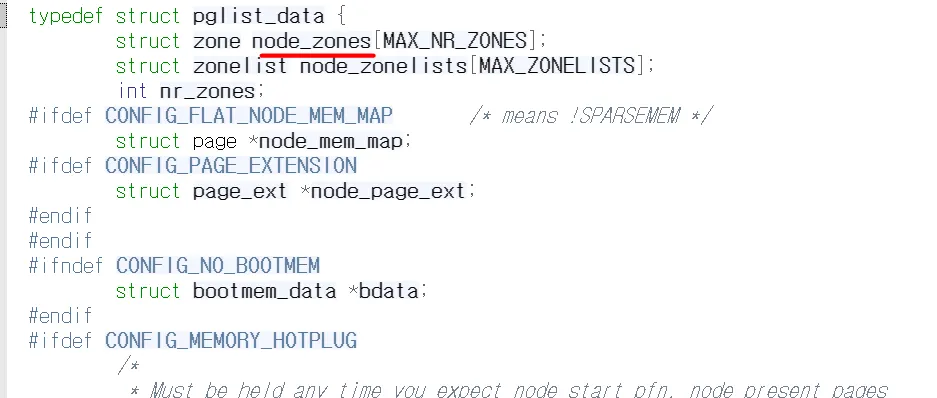
zone 구조체는 다음과 같다
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
C
복사
중요 필드는 다음과 같다
•
unsigned long watermark[NR_WMARK];
워커마크는 시스템에 할당할 메모리가 얼마나 있는지를 알려주는 지표이며 배열 인덱스는 enum 선언부이다
WMARK_HIGH: 잔여 메모리양이 충분하다.
WMARK_LOW: 잔여 메모리양이 적다.
WMARK_MIN: 잔여 메모리양이 너무 부족해 시스템을 구동하지 못할 정도이다.
Plain Text
복사
•
one_start_pfn
해당 zone이 시작하는 PFN
•
managed_pages
present_pages 중 buddy system으로 관리되고 있는 페이지의 수
•
spanned_pages
zone이 가질 수 있는 총 page 수
•
present_pages
zone에 존재하는 물리 page 수
•
const char *name
존 이름
•
struct free_area free_area[MAX_ORDER]
페이지 Order 별 잔여 페이지 갯수를 확인가능. 페이지 Order에 대해선 추후 버디 시스템에서 설명할 예정이다. 매우 중요하다

