

요번 강의는 저번 시간에 설명한 fork() 내용의 복습과, PCB의 상세 내용 그리고 clone 에 대해서 설명한다.
1. fork() 복습

저번 정리에서 충분히 설명을 했으므로 간단하게만 정리하겠다.
커널안에 internal 한 함수들이 있는데 그 중 하나가 context_swtch() 함수이다. 해당 함수가 커널 내에서 언제 호출이 되냐면, read, wait, exit 같은 시스템콜이 호출될때 내부적으로 호출이된다.
context_swtch() 함수가 커널 내부에서 호출이 되면, 현재의 CPU state를 실행중인 프로세스의 PCB에 저장한다. 그리고 해당 프로세스는 sleep이 된다. 그다음에 이제 새로 실행시켜야할 프로세스의 PCB에 들어있는 리소스를 가져와서 걔의 CPU state를 로드한다. 즉 CPU register들을 load시킨다.
이러한 과정이 바로 context_swtch() 쉽게 말하면 schedule() 함수에서 일어나는 로직이다.
1.
save old state vector
2.
choose next process
3.
load new stae vector
전체 로직도 다시 복습하자.
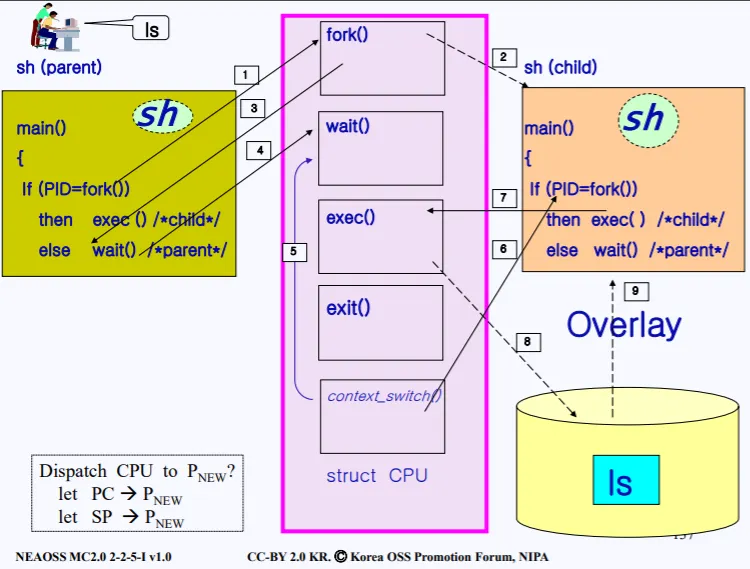
1.
ls 명령어를 치면 현재 쉘 프로세스가 ls를 수행시키기위해 동작하고, 쉘 프로세스에서 fork를 호출한다.
2.
sys_fork가 커널에서 호출되고, 커널은 현재 부모 프로세스의 리소스를 복사한다. 이에 따라 PCB, 커널 스택, 소스코드 전부 복사된다.
3.
부모 프로세스는 fork가 끝나면 분기에 따라 wait을 호출한다.
4.
sys_wait가 커널에서 호출된다
5.
커널 내부에서 context_swtch()가 호출되면서 현재 프로세스의 리소스를 PCB에 복사하고 자식 프로세스에게 CPU 점유를 넘긴다
6.
자식 프로세스는 ready 큐에서 CPU를 점유받고, 실행을 한다.
7.
exec가 호출되면서
8.
디스크에 있는 'ls' 프로그램을 로드한다.
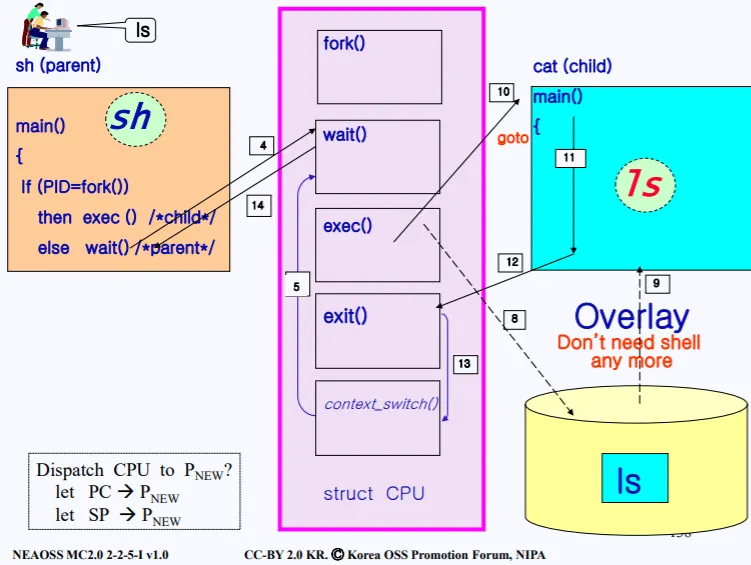
9. 자식 프로세스 쉘을 더이상 필요없다. 따라서 그 위에 ls 프로그램을 덮는다.
10. ls 프로세스가 실행된다.
11,12,13 실행이 끝나면 exit()가 호출되고 커널에서 한번더 context_switch()가 호출되면서 기존의 부모 프로세스의 PCB의 정보를 CPU에 로드한다.
14. 전에 부모의 커널 스택에서 wait()함수까지 실행됬었으므로 이때로 다시 돌아간뒤, 다시 wait() 에서 wait를 호출한 유저로 돌아간다
지금까지 프로세스를 create하는것에 대해서 설명했다. 즉 자식 프로세스를 생성시키는 일련의 과정을 살펴보았는데 여기서 중요한게 있다. 프로세스를 생성할때 생길수 있는 2가지의 오버헤드가 있다.
1.
부모 프로세스의 이미지를 복사하는데 드는 오버헤드
2.
부모 프로세스의 PCB를 복사하는데 드는 오버헤드
PCB는 수킬로바이트다. 즉 매우 용량이 크다는 소리이다.
그렇다면, 이러한 오버헤드를 줄이기 위한 노력이 들어가있을 것이다. 어떻게 오버헤드를 줄일수 있는지 살펴보자. 첫번째로 PCB 복사시에 일어나는 오버헤드를 줄이는 방법이다.
2. Overhead of PCB copy
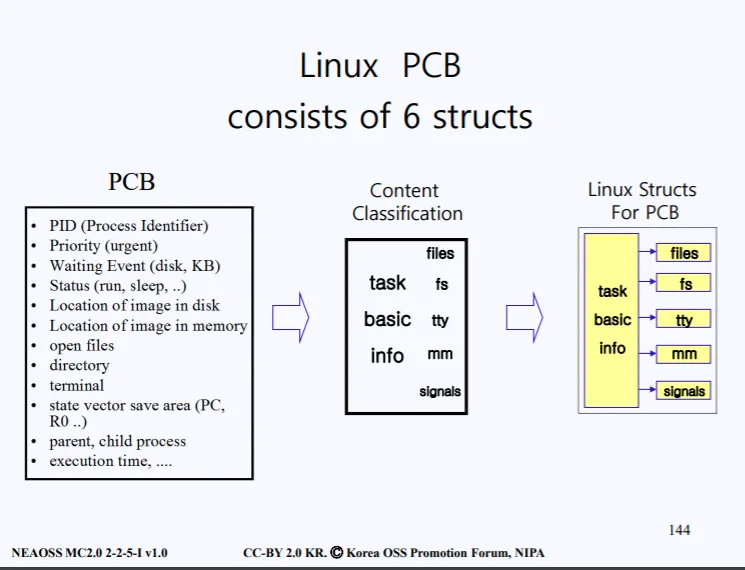
PCB에 프로세스의 처리에 필요한 다양한 리소스가 들어있다고 전에 설명했다. 이러한 리소스들을 분류를 하면 크게 6가지 구조로 구분지을수 있다.
•
task basic info
•
files : 현재 프로세스가 open file들의 정보가 담김
•
file system : 현재 프로세스가 접근중인 file system 정보
•
tty : 현재 프로세스가 사용중인 터미널 정보
•
mm : 현재 프로세스가 사용중인 메인 메모리 정보
•
signals
이러한 정보들을 합치다보니, 당연히 PCB의 용량은 수킬로바이트가 된다. 실제 PCB 정보에 대한 구조체는 아래의 그림처럼 구성되어 있다.

task_struct라는 구조체안에 PCB 데이터들이 들어있다. 여러 데이터들이 있는데, 왼쪽을 보면 포인터로 되어있는 변수가 있다.
files, fs, tty, mm, signals 총 5개의 포인터들이고, 나머지 변수들을 합쳐서 task basic info 라고 분류되어있다. 즉 리눅스에서 PCB 구조를 하나의 구조가 아닌, 우측 사진 처럼 총 6개의 구조로 나뉘어져 있다.
그렇다면 왜 PCB를 6개의 구조로 나눠서 관리하는것일까?
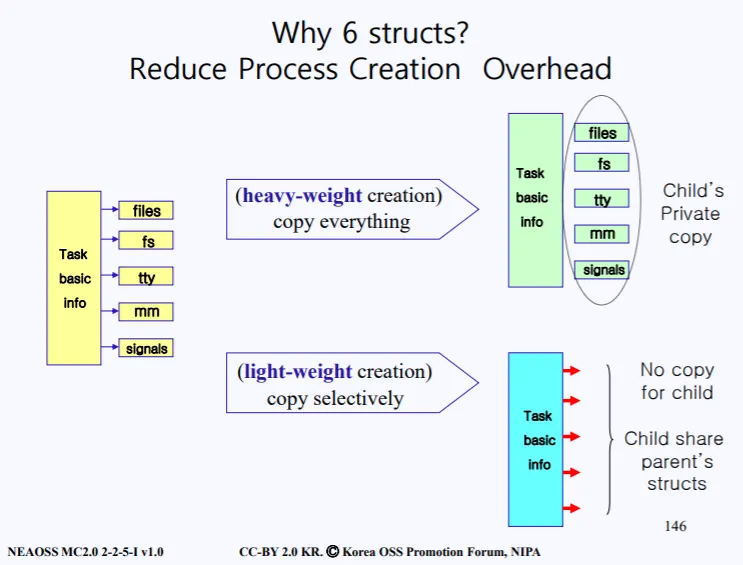
fork를 통해 부모의 PCB를 복사한다는 소리는 Task basic info, files, fs, tty, mm, signals 를 전부다 read하고 write하고를 반복해야한다는 소리이고 이는 많은 오버헤드가 생긴다. 따라서 6개의 구조로 분류하는 목적은 오버헤드를 줄이기 위함이라고 볼수있다.
부모가 프로세스의 file system, files, tty, mm, signals 는 보통 자식 프로세스랑 동일하게 사용되어진다. 그렇다면 굳이 공통으로 사용하는 리소스를 복사하는게 아닌, 공유해서 사용하면 read, write하는 오버헤드가 훨씬 줄어들 것이다.
이렇게 PCB를 6개의 구조로 나눔으로써 부모 PCB 일부를 공유할수 있게 되고 이를 통해 오버헤드를 줄일수 있게 된다. (혹은 필요한 일부만 복사해올수도 있다.)
이제 실제 예시를 들면서 쉽게 이해를 해보자.
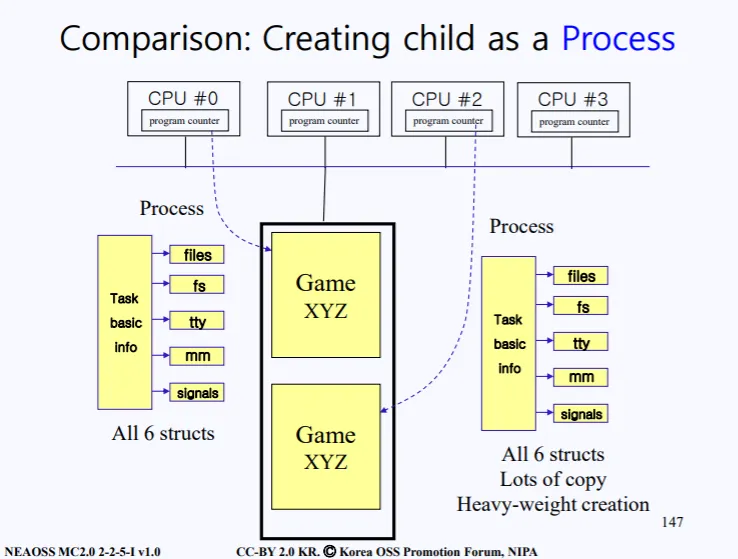
현재 메인 메모리와 4개의 CPU, 그리고 이들의 통로인 버스가 있다. 현재 Game XYZ 프로그램이 하나 돌아가고 있는 상황이다. 각 CPU에는 program counter가 존재한다.
좌측에는 6개의 구조로 되어있는 Game XyZ의 PCB가 존재한다. 이때 전통적인 방법으로 Game XYZ의 자식프로세스를 생성하려면, PCB를 통채로 복사하고, 이는 오버헤드로 직결된다.
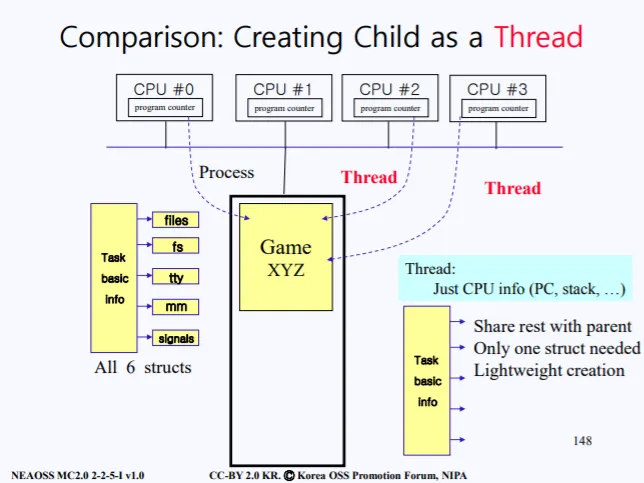
따라서 PCB의 모든 정보가 아닌, Task basic info 만 복사하고, 나머지 files, fs, tty, mm, signals 구조체들은 부모꺼를 같이 공유하게 끔한다. 이를 통해 이전보다 오버헤드를 줄일수 있게 되고, 이를 바로 쓰레드라고한다.
즉 child를 프로세스로 만드는게 아닌, 쓰레드로 만듦으로써 기존의 큰 오버헤드를 줄일수 있게 되는것이다. Task basic info 에는 주로 CPU 관련 정보(레지스터 같은거)들이 들어있다.
이렇게 쓰레드를 만들면 만들어진 쓰레드는 부모 프로세스로부터 just CPU info(PC, stack..) 정보들만 복사된다.
3. Linux thread
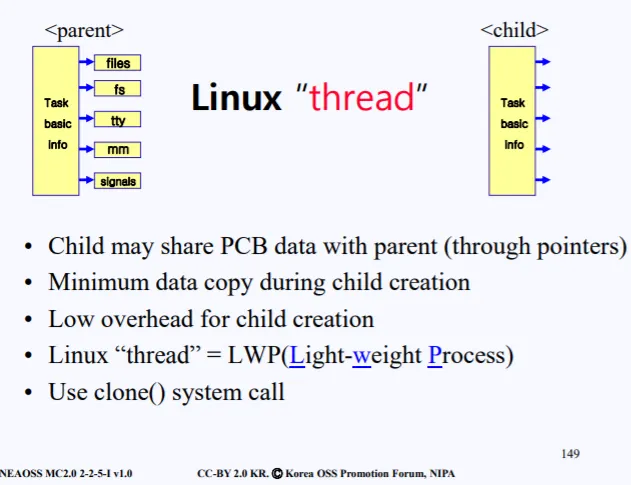
Thread의 특징은 다음과 같다
•
PCB의 Task basic info만 복사하고, 그 이외의 tty, fs 등은 부모 PCB 정보의 주소를 가지고 있어서 부모와 공유한다.
•
따라서 child를 만들는데 복사되는 데이터가 최소한으로 가능하다
•
linux thread를 LWP라고도 부른다(Light-weight-process)
•
thread는 fork()가 아닌, clone()이라는 시스템 콜로 만들어진다.
3.1 clone() system call
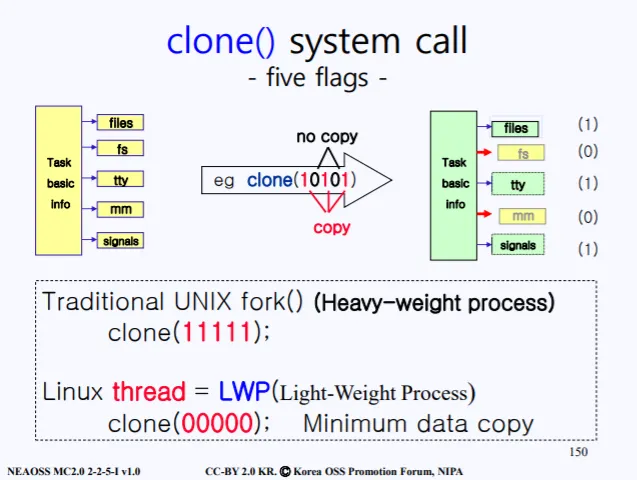
위 그림은 clone system call이 호출될때의 과정이다. 실제 sys_clone()이 호출되면, 내부적으로 binary bit 5개를 함께 보낸다. files, fs, tty, mm, signals 순으로 1이면 복사, 0이면 공유한다는 의미를 내포하고 있다.
예를 들어 clone(10101) 이 binary bit으로 세팅되면, files, tty, signals 3개의 구조체만 부모의 PCB에서 복사하고 나머지 2개는 복사하지 않겠다라는 의미이다.
제일 Light-Weight 인 경우는 모든 bit가 0인 경우이다. 만약 clone(11111)이면 기존의 모든건 복사하는 방식처럼 Heavy-Weight가 발생한다.

위 그림은 man clone을 치면 알수있는 정보이다. 파란 부분이 중요하게 말했던 공유 라는 특징이 설명되어 있는 부분이다.
추가적으로 강의에선 설명되있지 않는 부분이지만 위에 설명한 clone() 과 관련하여 중요한 부분인거 같아 간단히 집고 넘어가겠다.
sys_fork()든 sys_clone() 이든 커널 내부에서는 실제로 _do_fork() 함수가 호출되고, 함께 들어오는 인자를 보고 수행되는 로직이 구분된다.
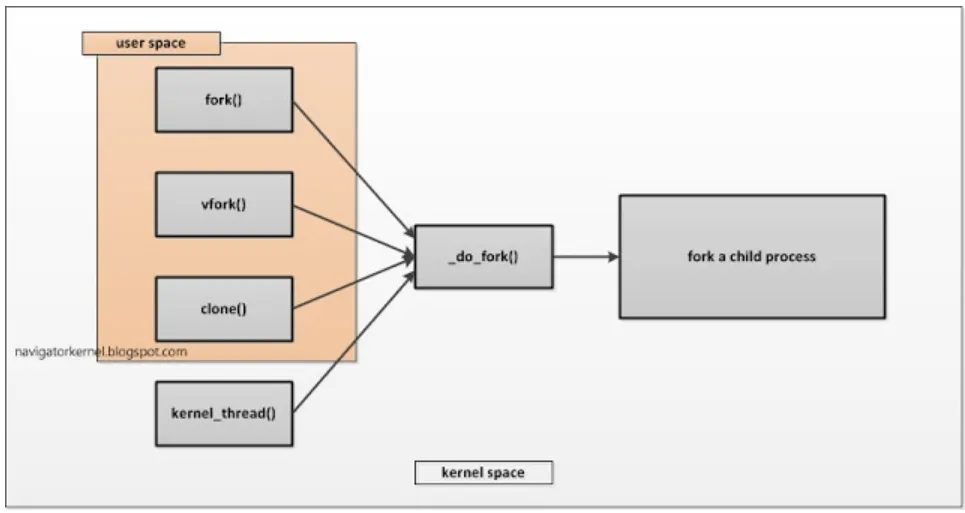
위와 같이 fork든, vfork든 clone이든 _do_fork()가 최종적으로는 커널 내부에서 호출된다.
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL, 0);
//CLONE_VM => 생성되는 자식과 부모간의 메모리를 공유하겠다는 옵션
}
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
//자식 프로세스가 종료될 때 부모 프로세스에게 SIGCHILD 시그널을 보내라
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
SYSCALL_DEFINE0(vfork)
{
return _do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL, 0);
//CLONE_VM => 생성되는 자식과 부모간의 메모리를 공유하겠다는 옵션
}
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}
C
복사
이는 커널 소스코드를 보면 do_fork가 동일하게 호출되지만, 들어가는 인자가 다르다는것을 볼수 있다.

clone() 로직을 보면 sys_clone() 을 내부적으로 호출하고, 실제로 do_fork()가 호출된다. dup_task_struct()가 호출되면서, 커널스택, task_struct의 공간을 새로 만든다. 그리고 get_pid()를 호출하여 새로운 PID를 얻는다. 그다음 clone binary bit를 체크하여 복사해야하는 구조체만 부모로부터 복사해온다.
4. Overhead of Image copy
child를 만드는데 PCB와 Image를 복사하는데 오버헤드가 든다고 했다. 위에서 PCB 복사시 생기는 오버헤드를 줄이는 방안을 설명했고, 이제 Image 복사시에 생기는 오버헤드를 줄이는 방법은 살펴보자.
실제로 PCB보다 Image의 사이즈가 훨신 더 크기 때문에, 더 많은 오버헤드가 생긴다. 따라서 반드시 이 오버헤드를 줄어야한다.
현재 터미널을 키고 shell에서 ls 명령어를 치면 해당 쉘에서 바로 동작하는 것이 아닌, shell을 copy해서 child를 만든다음에 copy한 쉘 위에 ls 이미지를 overload 시켜서 실행된다.
너무 비효율 적이지 않는가? ls 로 overload 시킬것데 왜 굳이 부모의 쉘(이미지라고 생각하자.) 을 복사해올까? 그냥 바로 복사하지 말고 ls 를 디스크로 가져와서 바로 쉘에서 실행시키면 되지 않을까?
물론 위와 같은 복사의 과정은 반드시 비효율적이다! 라는 것은 아니다. 만약 현재 '면접자료' 문서를 실행시키고 있는데, child로 똑같은 '면접자료' 문서를 띄우고 싶은 경우도 있다.
Markdown
복사
어쨋든 말하고 싶은 주 내용은, child 생성시 부모의 이미지를 그대로 복사하는 로직에서 발생하는 비효율성을 줄여야 한다는 것이다. 따라서 엔지니어들은 부모의 이미지를 그대로 복사해 오는 것이 아니라 page mapping table 만 복사해오도록 구현하였다.
즉 child는 부모의 모든 이미지가 아닌, 부모의 이미지를 가리키고 있는 page mapping table 만 가져옴으로서, 오버헤드를 줄일수 있다.
맨날 말하는 Image라는건 PCB와 프로세스를 실행하기위해 필요한 Code, Stack, Data 등을 아우르는 단어라고 생각하면 된다.
따라서 child는 부모와 동일한 page mapping table 만 가져와서 실행을 한다. 명령어들을 수행시킬동안에 매핑 테이블을 부모와 같이 사용할수 있다.
여기서 중요한 점이 있다. 무언가를 공유할 시 항상 생기는 문제가 존재하는데 바로 특정 페이지에 write를 하는 경우이다.
read시에는 크게 문제되는게 없지만, 만약 write를 하게 되면 분명 문제가 생긴다. 이러한 문제를 방지하기 위해 자식이 write하려는 페이지만 따로 복사를 해주게 된다. 이를 Copy-on-Write 줄여서 COW라고 한다. 이제 이 과정이 실제로 어떻게 구현되어있는지 살펴보자.
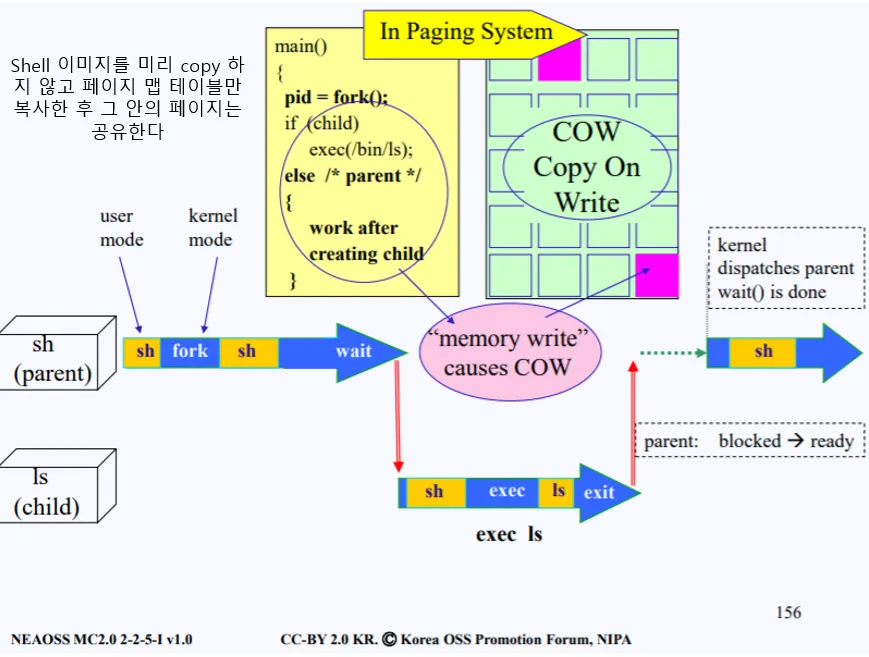
현재 쉘에서 ls를 수행하기 위해 fork를 한다. fork가 호출되면, 자식을 생성하고 현재 이미지의 페이지 맵 테이블만 복사하고 부모는 fork의 호출이 끝난후 wait 상태가 되서 sleep된다.
부모가 block되면, 자식은 cpu를 양도받아 fork 후의 루틴으로 역시 진행된다. 이제 exec이 되는데, 페이지 맵 테이블을 참조하여 특정 페이지에 대한 명령어 fetch 및 read는 크게 상관이 없고, write시에는 해당 페이지만 복사해온다. 이 부분이 보라색 부분이다. 따라서 해당 페이지는 부모하나, 자식하나 이렇게 두개의 복사본이 생기게 된다.
자식은 보통 ready 큐에서 cpu를 양도받으면 fork의 return 후 부터 시작한다. 따라서 대부분 바로 exec을 하는데, 그 이전에 발생하는 문제가 있다.
쫌전의 상황으로 돌아가보자. 부모가 fork를 호출한후에, 바로 wait()를 호출한다는 보장이 없다는 것이다. wait() 가 호출되기 전에 막 딴짓을 하게되는데, 여기서 말하는 딴짓은 메모리에 access 한다는 의미이고,
메모리에 access할때 보통 3/1은 read가 아닌 write를 수행한다.
아직 자식이 CPU를 양도받기 전에 부모 코드에서 wait 전에 발생하는 무수한 메모리 access로 인해 페이지 테이블의 변화 즉 COW가 발생하게 된다. 하지만 생각해보면 이러한 COW는 의미가 없다. 자식이 CPU를 양도받게 된다면 대부분 바로 exec을 수행하기 때문에, 복제된 페이지들은 의미없이 바로 'ls' 이미지로 overlab된다.
즉 '낭비' 라는 것이다. 해당 복제는 의미없는 동작이라는 것이다. 그렇다면 이러한 낭비를 또 없애야한다.
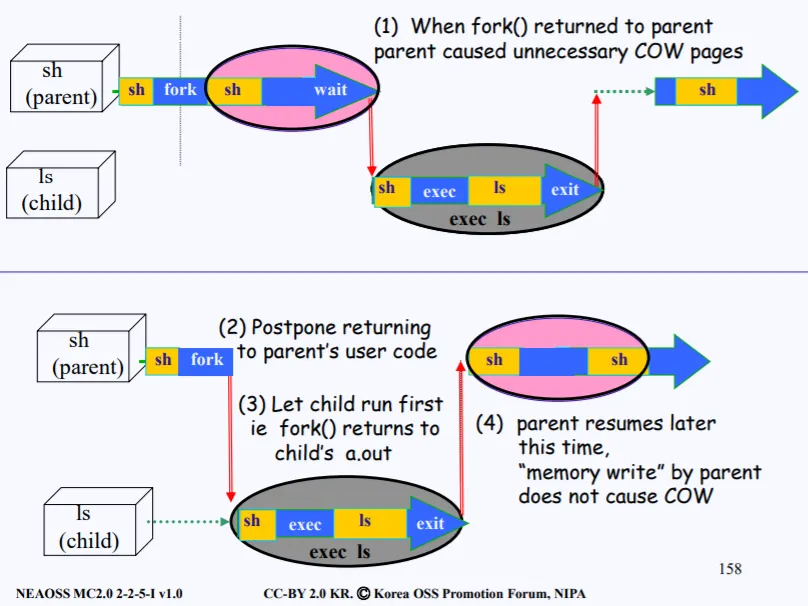
중간 경계선을 기준으로 위에 그림이 방금 설명한 의미없는 복제가 일어나는 로직이다. 여태 설명한 그 그림이란 의미이다. 저 경우 불필요한 COW pages가 발생한다.
이제 중간 아래 그림을 봐보자. ls 를 수행하기 위해 부모 쉘에서 fork를 호출하고, 여기서 fork의 return을 부모가 아닌 자식으로 돌려보내게 된다. 원래는 부모의 fork()가 끝나면 부모로 다시 돌아갸야 했다. 하지만 부모가 아닌 자식으로 돌아게 한다는 소리이다.
이는 fork() 내부에서 child의 우선순위를 부모보다 높이게 되고, 커널 내부의 로직이 수행되고 다시 유저 모드로 돌아갈때 제일 우선순위가 높은 놈으로 이동시킬수 있다.
정리를 해보자.
1.
의미없는 COW pages를 줄이기 위해, 기존 부모 쉘에서 fork가 child를 만들면서 우선순위를 높인 후, ready 큐에다가 넣는다.
2.
커널 시스템 콜의 로직이 끝난후 현재 ready 큐의 가장 우선순위가 높은 놈을 선택해 그놈에게 cpu를 넘겨준다. 즉 child가 바로 cpu를 넘겨받는다.
3.
child가 cpu를 넘겨받고 바로 exec을 수행한다. 수행을 하고 나서 exit을 통해 context swtiching이 다시 일어나고
4.
그때야 부모가 다시 cpu를 넘겨받아 fork로 돌아간뒤 다음 로직을 수행하게 된다.
이렇게 수행되면 child가 exec을 끝냈기 때문에 할당받았던 메모리가 반환될것이고, 더이상 부모의 페이지 맵 테이블은 필요없기 때문에 의미없는 COWS를 줄일수 있게 된다.
5. 정리
1강부터 4강까지 리눅스 커널에 대한 베이스적이고 중요한 부분들이 많았다. 중간중간 강의를 보면서 어? 저건 지금 사용안되는거 아닌가? 하면서 현재 바뀐 내용을 따로 정리하고 그랬는데, 3강 4강 설명에 다 바뀐 내용이 들어있었다. 크... 기본 → 문제발생 → 수정 순으로 강의가 설명되고 있다.
강의는 40분 내외의 짧은 시간이지만 정리하고, 이해하는데는 꽤 오래 걸린다.. 하지만 그만큼 얻어가는게 정말 많은거 같다. 후에 리눅스 커널 익스를 공부하기 위한 베이스라고 생각하고 열심히 진행 공부해보자.

