

후에 설명한 리눅스의 파일 시스템을 설명하기 전에 유닉스의 파일시스템 구조를 먼져 보고가자.
1. Original UNIX File System
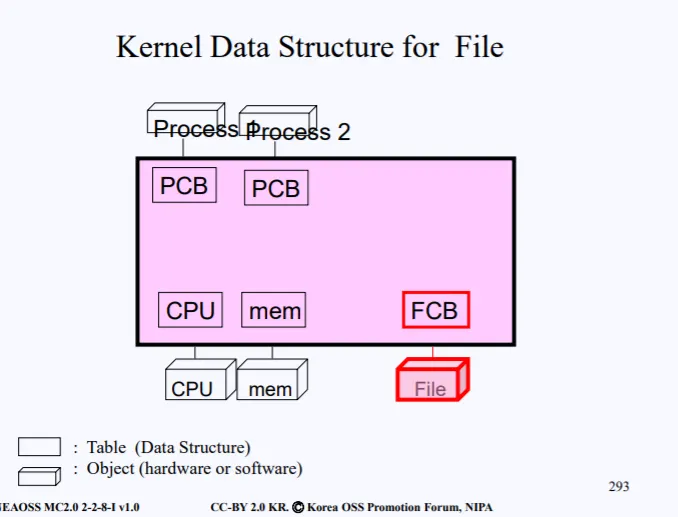
위 사진은 전에도 설명했던 그림이다. 분홍색 영역은 Kernel 영역으로 이 커널이 하는 일은 아래로는 하드웨어 자원들을 관리하고 위로는 프로그램들을 관리한다.
커널에는 이러한 자원들을 관리하기 위해 하드웨어마다 Data Structure, 프로세스마다 Data Structure를 가진다. 그 중 파일 하드웨어를 위한 Data Structure를 FCB(File Control Block)이라고 부른다.

File Data Structure 즉 FCB는 결국 File 하드웨어를 위한 메타데이터이다. 메타데이터에는 다양한 정보들이 들어있다.
•
Owner : 파일 소유자가 누구인지
•
protection : 해당 파일에 대한 퍼미션은 뭔지
•
device : 해당 파일이 어디에 있는지
•
content : 파일의 내용은 어디서 찾을수 있는지
•
device driver routines : 파일이 들어있는 디바이스의 어디를 읽어야 read나 open 같은 함수를 호출할수 있는지
•
accessing where now (offset) : 현재 파일의 어디를 읽고 있는지
예를 들어 read() 시스템 콜을 통하여 파일의 데이터를 읽어오기 위한 fp를 만들었다고 하자. (open으로) 그럼 fp는 read하고 난 count 만큼 증가가 된다. 이러한 fp는 lseek() 함수로 위치를 변경시킬수 있다.
이번엔 파일을 저장할때 어떤식으로 저장되는지 살펴보자.
1.1 File store
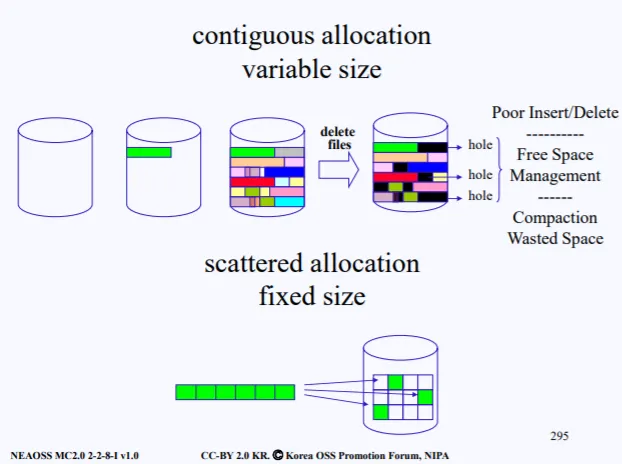
현재 파일을 disk에다가 저장하려고 하는 상황이다. 어떻게 디스크에다가 파일을 저장할까?
간단하게 생각하면 그냥 차례대로 파일을 저장하면 된다. 초록색 파일을 저장하고 그다음 회색파일 .. 이렇게 연속적으로 저장을 한다.(Contiguous allocation)
하지만 중간 중간 파일이 삭제가 되면 문제가 발생한다. 디스크 내의 파일들이 중간중간 삭제가 되면, 현재 hole 이라고 표시되어있는 영역처럼 구멍이 생긴다.
만약 생긴 구멍이 새롭게 저장시키려는 파일의 사이즈와 딱 맞게 된다면 괜찮지만, 구멍보다 약간 사이즈가 작은 파일이라면 문제가 생긴다. 100기가 구멍중 파일은 80기가 사이즈를 가지고 있어 20기가가 또 구멍이 생긴다.
디스크 조각모음이 바로 저러한 구멍을 모아서 디스크의 영역을 확보시키는 역할이다
이런식으로 계속 파일이 저장되다보면 디스크에는 여러 작은 조각들이 존재하게 되고 이를 내부 단편화가 발생한다. 내부 단편화가 발생하다 보면 실제 디스크가 가지는 총 용량은 1TB이고 실제 사용중인 공간은 800기가 이지만 디스크가 꽉찾다는 에러메시지가 발생할수 있다.
이는 바로 외부 단편화로써, 조각난 디스크가 너무 많아져서 새롭게 저장시킬수 있는 파일을 위한 공간이 없다는걸 뜻한다. 이러한 외부 단편화를 줄이려면 다음과 같이 하면된다. 다시 그림을 봐보자.

디스크에 저장하려는 파일을 그대로 저장하는게 아니라 동일한 크기로 조각을 낸다음이를 디스크의 섹터에 저장시키는 것이다. (Scattered allocation)
당연히 조각낸 파일들을 디스크에 연속적으로 넣으면 좋겠지만, 컴퓨터를 오래 쓰다보면 특정 섹터가 삭제될수도 있고 수정될수도 있기 떄문에 파일 조각은 연속되어 있지 않을수가 있다.
이렇게 파일시스템을 구성하면, 디스크의 섹터는 모두 동일한 크기를 가지기 때문에 디스크 조각모음을 할 필요가 없다. 하지만 이 방법이 무조건 좋다는것은 아니다. Scattered allocation의 단점은 디스크에서 원하는 조각들을 찾기 위해 lseek() 같은 함수로 파일 포인터를 옮겨가며 찾는데 딜레이가 생길수도 있다.
결국 둘다 장단점이 있다. 첫번째 방법은 파일 포인터가 한번 가리키면 연속적으로 빨리 파일을 읽을수 있다. 음악파일 같은 경우는 이 방식으로 읽으면 좋다. 하지만 공간적으로 낭비가 발생하고 두번째 방법은 시간적으로 딜레이가 발생한다.
따라서 디스크를 파티션을 나눠서 일부는 Contiguous allocation, 일부는 Scattered allocation 방식으로 파일을 관리한다. (하지만 대부분은 Scatter 할당 방식을 사용한다고 함)
1.2 File open
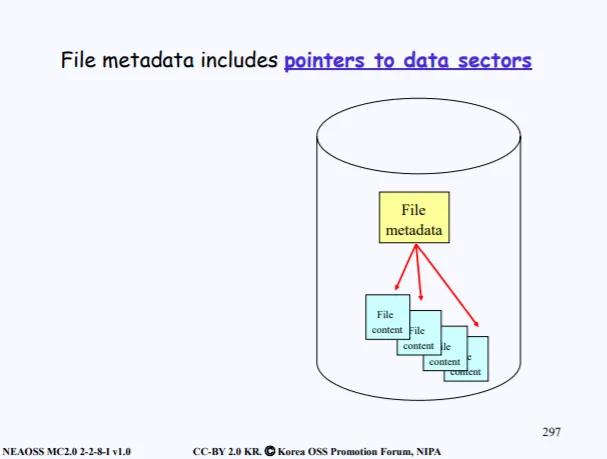
그럼 이제 파일들이 디스크에 저장되어있는 상태에서 파일을 read하려고 한다. read를 하려면 일단 파일을 디스크로부터 open해야한다. 파일이 분할되서 여러 섹터에 존재한다면 그 섹터들의 주소들을 다 알아야 한다.
이러한 섹터들의 주소는 File 메타데이터에 저장을하게 된다. 이 메타데이터는 아까 말한 FCB에 들어있다.
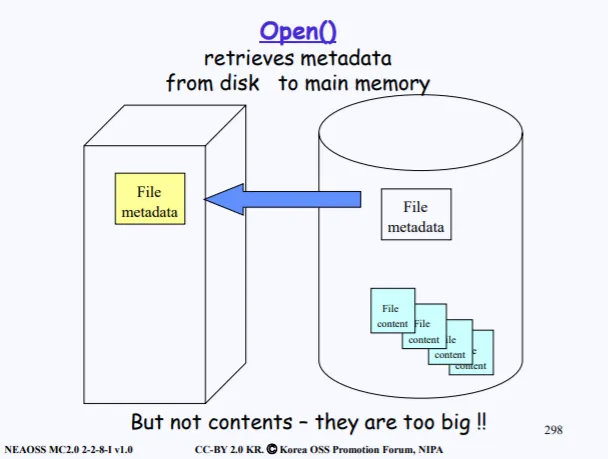

따라서 우리는 Open을 위해 FCB에 존재하는 메타데이터들만 우리 메모리로 가져오면되고, 메모리에서는 파일의 데이터 섹터를 접근하기 위해 복사해온 메타데이터 안의 정보를 이용하면 된다.
따라서 데이터 섹터가 올라오는게 아닌, 필요할 때마다 메타이터를 보고 데이터 섹터에 접근할수 있다.
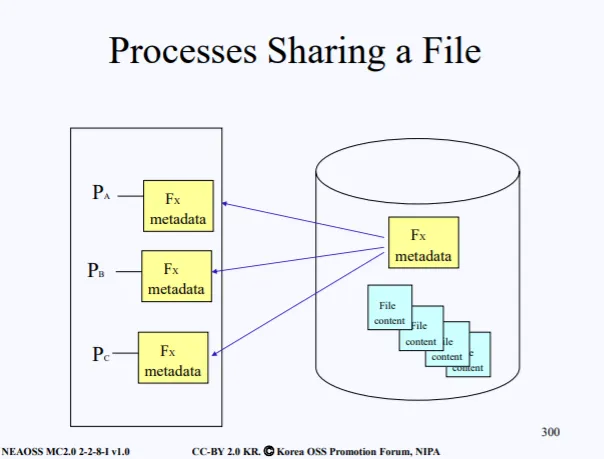
여기서 만약 3개의 다른 프로세스가 동일한 파일을 open하려고 하면 동일한 메타데이터 3개를 복사해서 가져오는데 이는 동일한 메타데이터를 중복해서 가져오기 때문에 낭비가 발생한다. 따라서 중복되지 않게 메타데이터를 공유해서 사용하도록 해야한다.

파일의 메타데이터에는 여러 정보들이 있다. 파일의 소유자가 누군지 3번이나 복사해서 각 프로세스에게 줄 필요는 없다. 따라서 중복으로 인한 낭비가 발생는 정보는 공유해서 사용하도록하느데 이러한 정보들은 inode struct로 묶을수 있다.
하지만 반드시 공유하면 안되는 메타데이터 정보가 하나 있는데 바로 offset이다. 현재 파일의 어떤 부분을 접근하고 있는지에 대한 오프셋은 공유하면 안된다. 따라서 file의 메타데이터는 두 개의 구조체로 구분된다.
•
inote struct : all processess share single copy in memory
•
file struct : Let each process have private copy
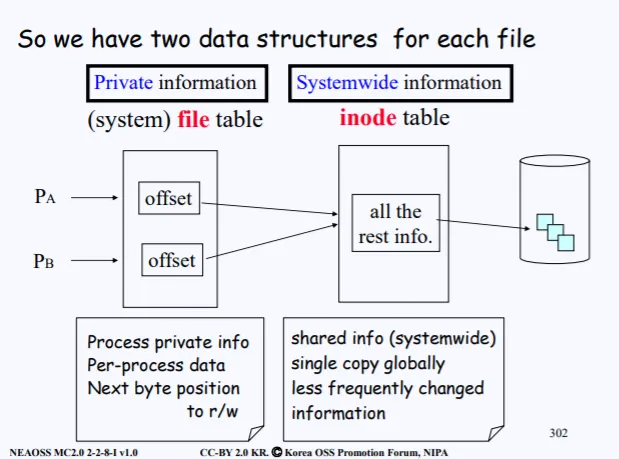
만약 현재 디스크에 파일이 10만개가 있다고 하자. 그럼 10만개의 모든 메타데이터 중 inode가 올라오는건 아니다. 현재 open하려는 파일의 inode만 복사한다. 이를 inode 배열에 저장한다.
그다음 이제 open한 파일의 포인터를 각 프로세스마다 독립적으로 복사해준다. 즉 offset을 다 따로 만들어준다. 만약 또다른 프로세스가 동일한 파일을 open하려면 현재 inode table에 올라온 inode를 공유해서 쓰고 단지 offset만 새로 복사해서 받는다.
1.3 inode
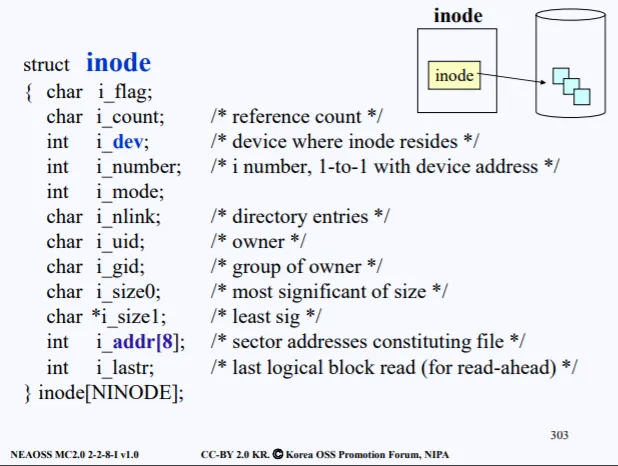
inode 구조체에는 실제 위와 같은 다양한 정보가 들어가 있다. 전부다 i_로 시작하는 필드이며 i_addr[8]에 실제 파일의 섹터 주소가 들어가 있다.

따라서 아까도 말했지만, 디스크에는 file metadata가 들어있고 그중 inode는 전부 동일한 크기의 구조체이기 때문에 inode를 위한 공간에 따로 모아둔다. 그리고 실제 데이터가 들어간 data block도 따로 모아둔다.
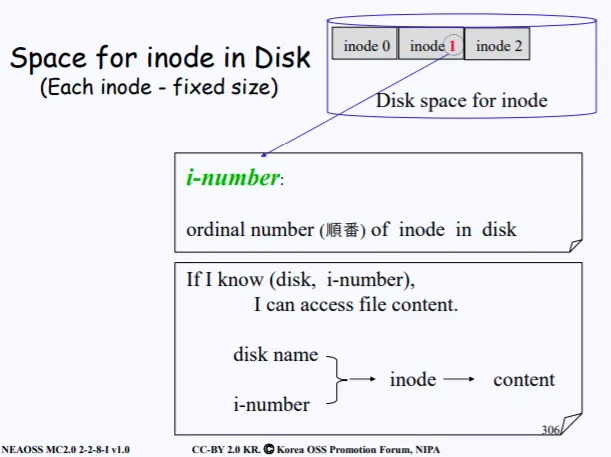
방금 inode를 따로 모아둔다고 했는데, 여기서 inode는 숫자를 가지고 있다. 이 숫자를 inode number라고 하는데, 이걸알고 있으면 디스크의 원하는 파일에 접근가능하다.
1.4 file

file 구조체는 실제 위와 같은 필드로 구성되어있다. 전부 f_ 로시작하는 필드이며 f_offset에는 inode table을 가리키는 인덱스가 들어있다. 따라서 offset을 통해 inode로 갈수가 있다.
1.5 Device switch table
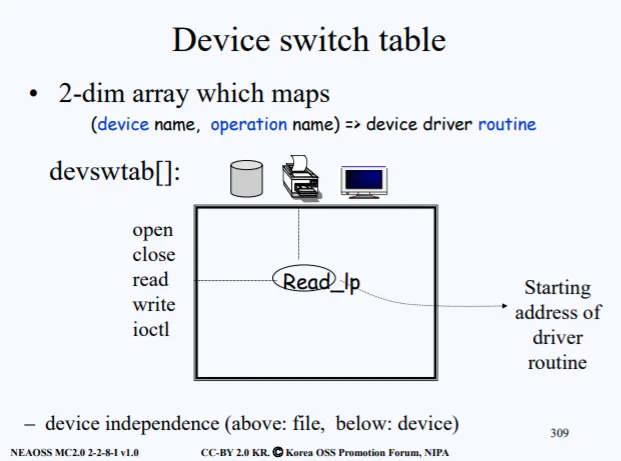
지금까지 file의 메타데이터에 존재하는 2가지 Data Structure를 배웠다. inode, file이다. 마지막으로 한가지가 더 존재한다. 리눅스에서는 모든게 다 파일로 관리된다고 했다. 프린터도 결국 파일로 관리되고, 프린트의 동작 중 read같은 기능이 반드시 필요할것이다.
따라서 어떠한 디바이스에서 어떠한 동작을 수행할 껀지에 대한 정보가 Devies switch table에 들어있다. 이를 device driver routine이라고 부르는데, devswtab[] 배열 형태로 구성되어있다.
각 행에는 동작시킬 operation이 들어있고, 열에는 어떠한 디바이스인지가 들어있다. 위 그림으로 예시를 들면 devswtab[2][1] 로 접근하면, 프린터 read operation drive routine의 시작 주소를 얻을수 있다.
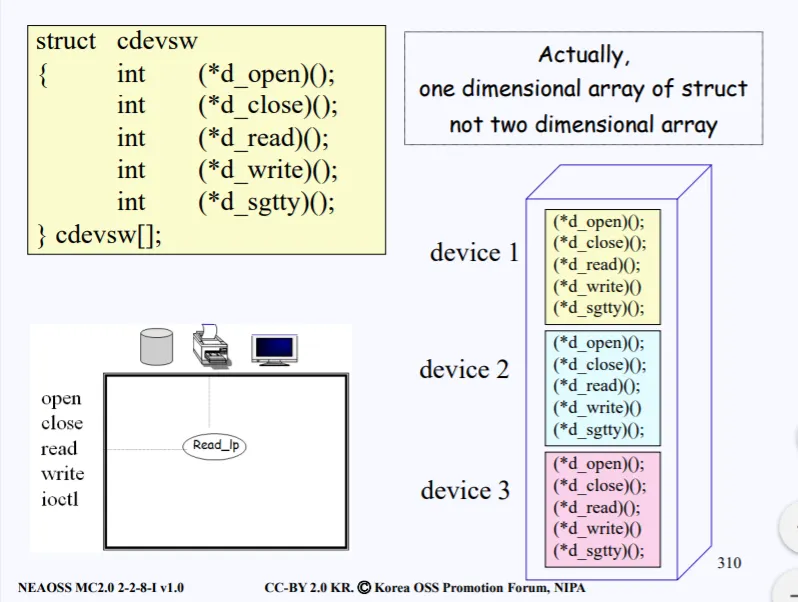
실제 구조체 배열은 저렇게 구성되어있다.
마우스든, 키보드든, NIC든 모든 디바이스들은 리눅스에서 파일로 취급되고 파일로 취급된다는 의미는 다 sequence of byte 로 처리된다.
따라서 이러한 디바이스들은 전부 device independence 하게 다 sequence of byte로 되어있는데, (파일로 추상화가 되어있다는 뜻) device switch table을 지나고 나면 모든게 다 device dependent 하게 된다. 따라서 연속적인 sequence of byte에서 각자의 디바이스에 맞는 역할을 수행하게 된다.
2. 정리
유닉스의 파일 시스템에 대한 전체적인 구조에 대해서 알아보았다. 다음시간에도 이어서 설명한다.

