

1. 문제
1) mitigation 확인
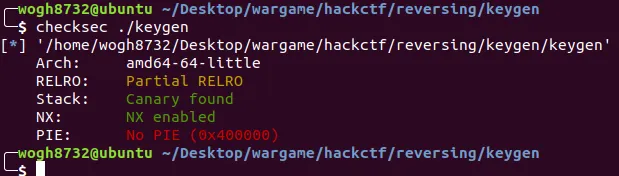
뭐 미티게이션을 보는건 큰 의미는 없지만.. 일단 PIE가 없다
2) 문제 확인

키를 입력받는다. 자세한건 아이다로 봐보자.
3) 코드흐름 파악
int __cdecl main(int argc, const char **argv, const char **envp)
{
FILE *stream; // [rsp+8h] [rbp-C8h]
char input; // [rsp+10h] [rbp-C0h]
char v6; // [rsp+60h] [rbp-70h]
unsigned __int64 v7; // [rsp+C8h] [rbp-8h]
v7 = __readfsqword(0x28u);
setvbuf(stdout, 0LL, 2, 0LL);
puts(s);
fgets(&input, 0x41, stdin);
if ( check_key(&input) )
{
stream = fopen("flag", "r");
if ( !stream )
{
puts(&byte_400AC0);
return 0;
}
fgets(&v6, 100, stream);
printf("%s", &v6);
}
return 0;
}
C
복사
메인에서 input에 입력을 받는다. 그리고 check_key()를 호출해서 반환값이 널이 아니면 플래그를 출력해준다.
bool __fastcall check_key(const char *input)
{
char *input_encode; // ST10_8
if ( strlen(input) <= 9 || strlen(input) > 0x40 )
return 0;
input_encode = encoding(input);
return strcmp("OO]oUU2U<sU2UsUsK", input_encode) == 0;
}
C
복사
일단 입력값은 사이즈가 9보단 커야하고 0x40보단 작아야한다. 그다음 encode()함수를 호출해서 반환값이랑 어떤 괴상한 문자열이랑 비교한다.
_BYTE *__fastcall encoding(const char *input)
{
unsigned __int8 v2; // [rsp+1Fh] [rbp-11h]
int i; // [rsp+20h] [rbp-10h]
int len; // [rsp+24h] [rbp-Ch]
_BYTE *buf; // [rsp+28h] [rbp-8h]
buf = malloc(0x40uLL);
len = strlen(input);
v2 = 0x48;
for ( i = 0; i < len; ++i )
{
buf[i] = ((input[i] + 12) * v2 + 17) % 70 + 48;
v2 = buf[i];
}
return buf;
}
C
복사
요게 실제 인코딩 로직이다. 입력값이 위 로직을 거쳐서 아까 괴상한 문자열이 되게끔하면 된다.
2. 접근방법
첨에는 저 로직을 수학적으로 역연산 그지랄 할라고했는데 생각해보니 그럴필요가 없었음. 어짜피 내가 입력할수 있는 값은 아스키값 범위가 정해져 있고, 그냥 저 encode 로직을 구현한뒤, 32~126까지 브포 떄려서 괴상한 문자열의 문자 하나씩 비교하면 끝임
key='OO]oUU2U<sU2UsUsK'
def encode(key):
v2=0x48;
buf=''
index=0
for j in range(len(key)):
for i in range(32,127):
tmp=((i+12)*v2+17)%70+48
if ord(key[j]) == tmp:
print('tmp: ',chr(tmp)),
print('key: ',key[j])
buf+=chr(i)
v2=tmp
break
print(buf)
C
복사
간단히 구현할수 있다.
3. 풀이
코드를 돌리면
╰─$ python ex.py
('tmp: ', 'O') ('key: ', 'O')
('tmp: ', 'O') ('key: ', 'O')
('tmp: ', ']') ('key: ', ']')
('tmp: ', 'o') ('key: ', 'o')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', '2') ('key: ', '2')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', '<') ('key: ', '<')
('tmp: ', 's') ('key: ', 's')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', '2') ('key: ', '2')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', 's') ('key: ', 's')
('tmp: ', 'U') ('key: ', 'U')
('tmp: ', 's') ('key: ', 's')
('tmp: ', 'K') ('key: ', 'K')
A,d<&$+$' +$& &&
C
복사
저렇게 나오는데 답이 틀렸다고 함. 웨지? 디버깅 ㄱ
'A,d<&$+$' +$& &&' 요거 그대로 넣고 strcmp 보면
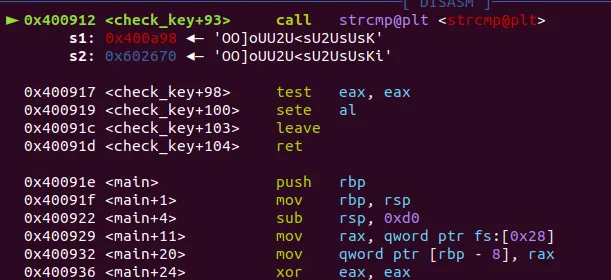
끝에 문자 하나가 더 들어가있다. 아마 마지막 개행 문자까지 인코딩된듯 저거 빼주고 하면 된다.
4. 몰랐던 개념
리버싱 문제는 왜케 적응이 안ㄷ...

