

명령어가 하나 수행되기 까지의 기본적인 3단계를 거친다.
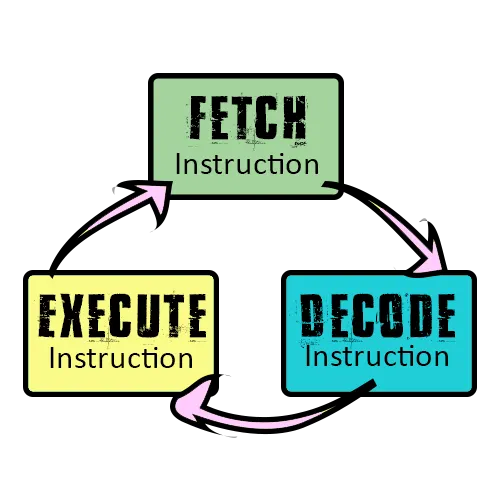
1.
Fetch : CPU가 기억장치로부터 명령어를 읽어옴
2.
Decode : 읽어온 명령어를 CPU가 이해할수 있도록 기계어로 번역
3.
Execute : 명령어 실행
CPU 내부 구조는 다음과 같다.
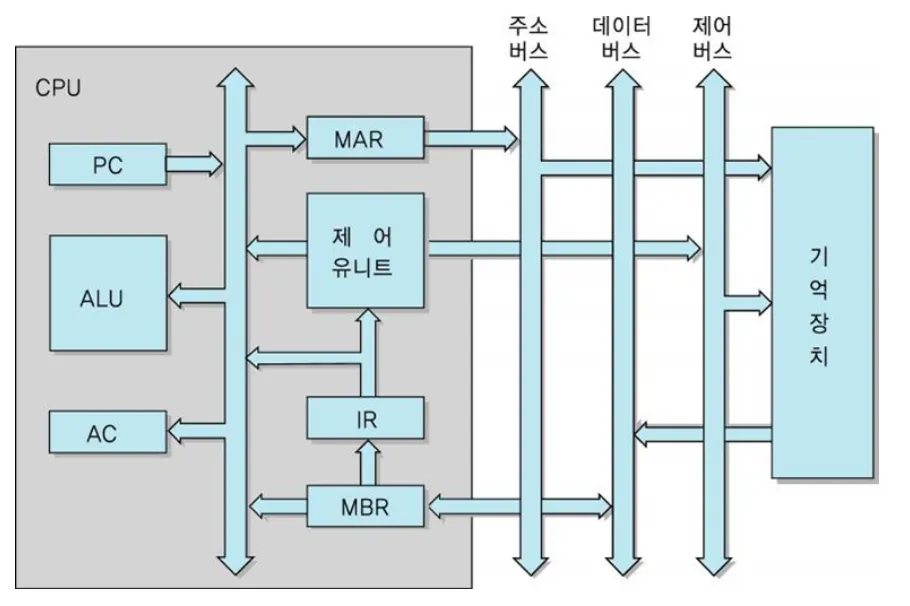
•
PC
다음에 인출할 명령어의 주소를 가지고 있는 레지스터
•
AC
데이터를 일시적으로 저장하는 레지스터
•
IR
최근에 인출된 명령어 코드가 저장되어 있는 레지스터
•
MAR
PC에 저장된 명령어 주소가 주소 버스로 출력되기 전에 일시적으로 저장되는 주소 레지스터
•
MBR
기억 장치에 쓰여질 데이터 혹은 기억장치로부터 읽어진 데이터를 일시적으로 저장하는 레지스터.
명령어가 한사이클을 돌때마다 위 사진 내부에서
fetch ⇒ decode ⇒ execute 가 실행된다.
만약 두개의 명령어가 호출된다면
fetch ⇒ decode ⇒ execute ⇒ fetch ⇒decode ⇒ execute 이렇게 총 6단계의 로직이 수행된다. 기본적인 3단계 사이클의 성능을 향상시키기 위해 파이프라이닝을 적용시켜 병렬적으로 명령어를 수행할 수가 있다.
•
ARM 7

기본 3단계에서 각 단계가 끝날때마다 다음 명령어가 병렬적으로 처리가 된다. 따라서 기존 명령어 3개가 9사이클을 돌았다면, 파이프라이닝을 이용하면, 5사이클로 동일한 결과를 낼수 있으므로 성능이 훨씬 좋아진다.
위 3단계는 기본이 되는 단계로, ARM7의 CPU에서 구성된다. ARM9는 5단계, ARM11은 8단계, CortexA8은 13단계라고 한다.
자세한 내용은 아래 블로그에 잘나와 있다.

그럼 이 내용을 정리한 이유를 간단히 살펴보자.
Dump of assembler code for function key1:
0x00008cd4 <+0>: push {r11} ; (str r11, [sp, #-4]!)
0x00008cd8 <+4>: add r11, sp, #0
0x00008cdc <+8>: mov r3, pc
0x00008ce0 <+12>: mov r0, r3
0x00008ce4 <+16>: sub sp, r11, #0
0x00008ce8 <+20>: pop {r11} ; (ldr r11, [sp], #4)
0x00008cec <+24>: bx lr
End of assembler dump.
Bash
복사
r0에 들어가는 값을 알아야 할 필요가 있었다. mov r3,pc를 하므로, 결국 r0에는 pc의 값이 들어간다는 것을 알았다. 기존 x86에서의 eip 역할이 PC라고 알고있어서 당연히 0x8cdc가 r3에 들어갈줄 알았지만 아니였다.
CPU 명령어 사이클에서 pc는 다음에 인출할 명령어의 주소를 가지고 있는 레지스터라고 했다. 즉 fetch할 명령어 주소가 들어가 있는데, 현재 상황에서 파이프라이닝이 적용이 되면

다음처럼 mov r3,pc 가 실행될때 pc는 fetch할 명령어의 주소인 sub sp,r11 코드의 주소이다. 따라서 r0에는 +8 인 0x00008ce4가 들어간다.

