

목차
1. kmalloc() 함수란?
int __init test_device_init(void) {
if(register_chrdev(300, "test_device", &vd_fops) < 0 )
printk(KERN_ALERT "driver init failed\n");
else
printk(KERN_ALERT "driver init successful\n");
buffer = (char*)kmalloc(1024, GFP_KERNEL);
if(buffer != NULL)
memset(buffer, 0, 1024);
return 0;
}
C
복사
커널 디바이스 드라이버 공부를 할 때 테스트코드에서 kmalloc() 함수를 많이 사용했다. 보통 malloc을 쓰는 것처럼 커널단에서 동적으로 메모리 할당을 할때 주로 사용하는 함수가 바로 kmalloc이다. 이 함수에 대해서 자세히 알아보쟈
커널에서 보통 주로 작은 사이즈의 연속된 물리 주소 공간을 할당받을 때 kmalloc을 사용한다. 이전 시간에 공부했던 slab 할당자에서 슬랩 캐시를 알아봤는데, kmalloc용 슬랩 캐시를 이용해서 빠른 할당을 해주는것이 주 목표이다.
Kmalloc type
kmalloc과 관련된 slab 캐시를 확인해보면 아래와 같은 타입들이 나온다

•
dma-kmalloc-<size>
◦
주소 제한이 있는 dma 존이 필요한 시스템에서만 사용되는 타입
◦
◦
kmalloc()의 두번째 인자인 플래그에 __GFP_DMA 를 넣게되면 dma용 커널 메모리의 할당을 위해 zone_dma 영역을 사용한다
◦
별도의 dma_zone이 필요하지 않는 시스템은 그냥 일반 kmalloc 타입을 쓴다
•
kmalloc-rcl-<size>
◦
shrinker를 제공하여 회수 가능한 타입에 사용되는 타입
◦
__GFP_RECLAIMABLE 플래그 사용
•
kmalloc-<size>
◦
일반적으로 사용되는 타입
Kmalloc cache size
아키텍쳐 별로 약간씩 다르긴 하지만 보통 kmalloc 슬랩 캐시는 2 page (8K) 사이즈까지 미리 준비해놓고, 요청한 사이즈에 알맞은 슬랩 캐시를 할당해준다. 만약 8K 이상의 사이즈를 요청하면 kmalloc 슬랩 캐시가 아닌, Buddy 할당자를 사용하여 할당시도를 하게된다.
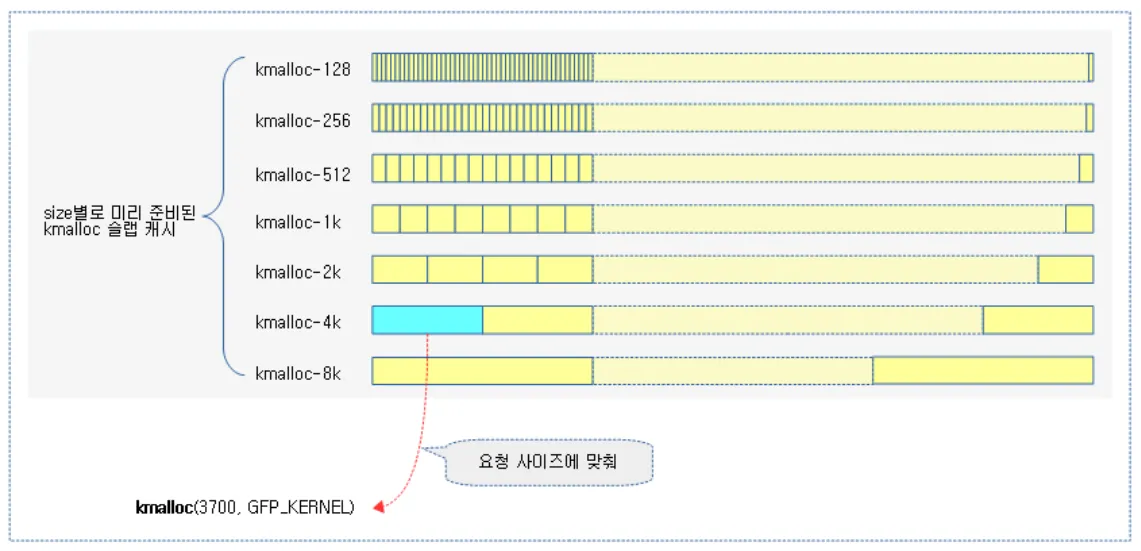
이렇게 만일 kmalloc(3700,GFP_KERNEL) 로 할당요청을 하게 된다면 내부적으로 적합한 사이즈의 슬랩 캐시를 선택한다. 위 경우에는 kmalloc-4K가 선택되어 해당 슬랩 캐시가 관리하는 슬랩 오브젝트 하나를 할당해주게된다
실제 슬랩 캐시는 배열 형태로 관리되고 kmalloc_index() 를 통해서 원하는 캐시가 들어있는 인덱스를 할당받게된다. 뒤에서 해당 함수를 분석할 것이다.
Kmalloc flag
kmalloc 함수는 두개의 인자를 갖는다. 첫번째는 요청하는 사이즈를 의미하고 두번째는 플래그를 뜻한다. 여기서 플래그란, 배달음식에 비유하면 쉽게 이해된다.
•
일반 주문 : 중국집에 전화해서 짜장면 2그릇이랑 탕수육하나 주세요 !
•
옵션 주문 : 중국집에 전화해서 짜장면 2그릇이랑 탕수육 주시고, 소스는 따로 주시구요 젓가락 2개 더 주세요 !
즉 플래그를 어떻게 설정하냐에 따라서 동적메모리 할당시의 옵션값이 바뀌게 된다. 플래그는 다음과 같은것이 있다
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | __GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
/* Convert GFP flags to their corresponding migrate type */
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE)
#define GFP_MOVABLE_SHIFT 3
Plain Text
복사
kmalloc() 함수를 호출할 때 지정하는 GFP 플래그에 따라서 아래와 같은 동작이 수행된다
1.
할당할 페이지 메모리 타입 설정
2.
메모리 할당 시 세부 동작 지정
•
GFP_KERNEL
일반적으로 사용되는 플래그이며 zone_normal을 사용하도록 요청한다. 또한 메모리의 할당이 완료될 때 까지 sleep상태가 될 수 있다.
•
GFP_ATOMIC
인터럽트 컨텍스트와 Soft IRQ 컨텍스트에서 주로 지정한다. 인터럽트나 Soft IRQ 컨텍스트에서는 sleep 상태로 진입되면 안되기 때문에 해당 플래그를 반드시 사용해야한다.
•
GFP_HIGHUSER
zone_highmem 영역을 할당하려면 사용해야하는 플래그이다.
•
__GFP_HIGH
높은 우선 순위로 처리되도록 요청할 때 사용한다
•
__GFP_NOFAIL
실패를 허용하지 않으며 성공할 때까지 처리하도록 요청할 떄 사용한다.
•
__GFP_NORETRY
해당 플래그를 사용하면 메모리 할당 요청에 대해 실패 시 재시도하지 않는다.
•
__GFP_NOWARN
해당 플래그를 사용하면 메모리 할당 실패 시 어떠한 경고도 처리하지 않는다
2. Kmalloc 소스코드 분석
실제 kmalloc의 소스코드를 한번 분석해보자. 버전은 4.14 기준이다.
우선 전체 흐름을 먼저 살펴보자.
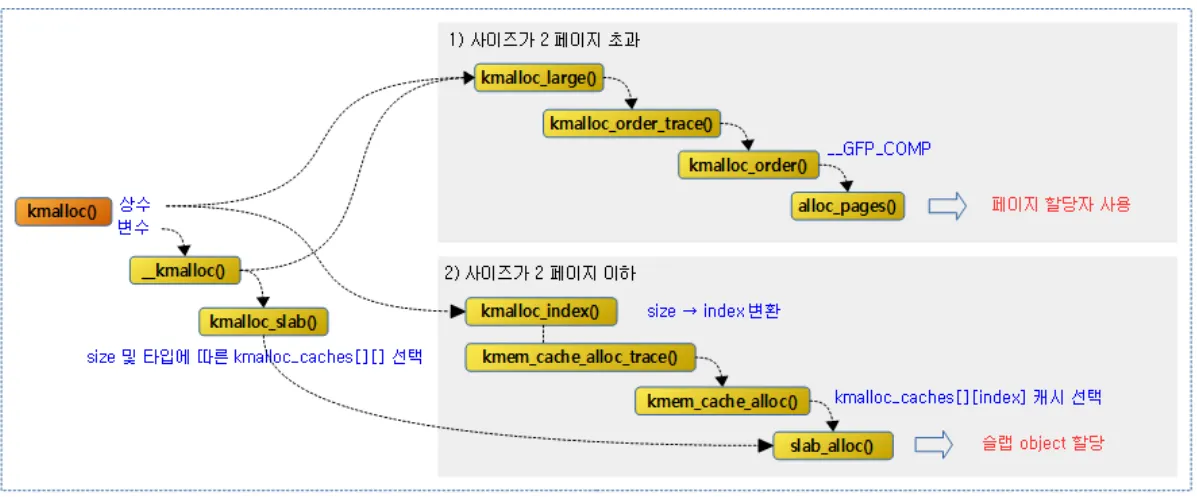
kmalloc이 호출되면 요청한 사이즈를 처리할 수 있는 슬랩 캐시를 우선 고른다. 요청 사이즈가 8K 초과인 경우 슬랩 할당자가 아닌 페이지 할당자(Buddy 할당자)로 할당 시도를 하고, 이하인 경우에는 슬랩 할당자로 할당시도를 한다. kmalloc 부터 살펴보자
2.1 kmalloc()
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags); // try buddy allocator
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}
C
복사
•
4-5 line :
만약 요청한 사이즈가 KMALLOC_MAX_CACHE_SIZE (8k) 보다 크면 버디 시스템으로 할당 시도를 한다. → kmalloc_large(size, flags)
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
..
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1)
...
#define PAGE_SHIFT 12
따라서 KMALLOC_MAX_CACHE_SIZE == 1<<(12+1)
Plain Text
복사
•
7-8 line :
GFP 플래그가 GFP_DMA아 아니라면 kmalloc_index 함수를 호출한다. 해당 함수는 슬랩 캐시 인덱스를 읽는 역할을 한다.
•
13 line :
획득한 인덱스를 이용하여 실제 슬랩 오브젝트 할당을 kmem_cache_alloc_trace 함수를 통해서 시도한다.
kmalloc_index()
kmalloc_index() 함수는 kmalloc() 함수로 요청한 메모리 사이즈에 맞게 kmalloc 슬랩 캐시 인덱스를 계산하는 역할이다.
/*
* Figure out which kmalloc slab an allocation of a certain size
* belongs to.
* 0 = zero alloc
* 1 = 65 .. 96 bytes
* 2 = 129 .. 192 bytes
* n = 2^(n-1)+1 .. 2^n
*/
static __always_inline int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8;
if (size <= 512) return 9;
if (size <= 1024) return 10;
if (size <= 2 * 1024) return 11;
if (size <= 4 * 1024) return 12;
if (size <= 8 * 1024) return 13;
if (size <= 16 * 1024) return 14;
if (size <= 32 * 1024) return 15;
if (size <= 64 * 1024) return 16;
if (size <= 128 * 1024) return 17;
if (size <= 256 * 1024) return 18;
if (size <= 512 * 1024) return 19;
if (size <= 1024 * 1024) return 20;
if (size <= 2 * 1024 * 1024) return 21;
if (size <= 4 * 1024 * 1024) return 22;
if (size <= 8 * 1024 * 1024) return 23;
if (size <= 16 * 1024 * 1024) return 24;
if (size <= 32 * 1024 * 1024) return 25;
if (size <= 64 * 1024 * 1024) return 26;
BUG();
/* Will never be reached. Needed because the compiler may complain */
return -1;
}
C
복사
1.
size가 0인경우 0을 반환
2.
size가 " KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96 " 조건에 만족하면 1을 반환
3.
size가 " KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192 " 조건에 만족하면 2를 반환
•
1 ~ 3 조건에 맞지 않고 8보다 같거나 작으면 3을 반환
•
쭉쭉 해서 최대 26까지 반환
•
만약 size가 54이면 6을 반환하는 식이다
kmem_cache_alloc_trace()
kmalloc_index()를 통해 index를 구했다. slabinfo로 확인되는 슬랩 캐시들은 실제 구조체 배열 형태로 전역변수에 선언되어있으며 우리가 구한 인덱스를 이용해서 특정 슬랩 캐시에 접근할 수 있다.
struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];
C
복사
따라서 " kmem_cache_alloc_trace( kmalloc_caches[index], flags, size); " 이렇게 호출한다는 의미는 구한 index가 만약 6이라면 kmalloc_caches[6] 에 우리가 사용하려는 슬랩 캐시 구조체가 들어있다는 소리이다.
void *kmem_cache_alloc_trace(struct kmem_cache *s, gfp_t gfpflags, size_t size)
{
void *ret = slab_alloc(s, gfpflags, _RET_IP_);
trace_kmalloc(_RET_IP_, ret, size, s->size, gfpflags);
kasan_kmalloc(s, ret, size, gfpflags);
return ret;
}
C
복사
kmem_cache_alloc_trace() 함수 안에서 실제 slab_alloc() 가 할당하는 주체이다.
slab_alloc() & slab_alloc_node()
slab_alloc() 함수는 kmem_cahe 구조체 포인터와 플래그, _RET_IP 총 3개의 인자로 호출된다
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr);
}
C
복사
별다른 기능 없이 slab_alloc_node() 함수를 호출한다
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPT so we need
* to check if it is matched or not.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid); //전담 CPU id 값 획득
c = raw_cpu_ptr(s->cpu_slab); // 전담 CPU per-cpu 구조체 포인터 획득
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and page associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* page could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*/
barrier();
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node)))
{ // slowpath !
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
else
{ // fastpath !
void *next_object = get_freepointer_safe(s, object);
// freelist 조정 위해
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
if (unlikely(!this_cpu_cmpxchg_double(s->cpu_slab->freelist, s->cpu_slab->tid, object, tid,next_object, next_tid(tid))))
{
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH); // fastpath로 할당 상태 표시
}
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}
C
복사
slab_alloc_node() 함수가 슬랩 오브젝트를 할당하는 핵심 역할을 수행한다.
1.
여러 CPU들중 선점가능하고 read 권한 만 있는 것을 제외하는 거 선택
do {
tid = this_cpu_read(s->cpu_slab->tid); //전담 CPU id 값 획득
c = raw_cpu_ptr(s->cpu_slab); // 전담 CPU per-cpu 구조체 포인터 획득
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
C
복사
위 로직이 끝나면 우리가 슬랩 할당자에서 공부했던 cpu_slab 포인터인 ' c ' 의 주소가 나옴!
2.
fastpah or slowpath 선택
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node)))
{ // slowpath !
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
else
{ // fastpath !
C
복사
cpu_slab 포인터인 c→freelist, c→page 를 얻어옴. 만약 c→freelist가 널이 아니면 할당 해줄 오브젝트가 존재한다는 뜻이므로 fastpath로 할당이 가능하다.
만약 없다면 __slab_alloc() 함수를 호출해서 slowpath 로 할당을 시도한다.
3.
fastpath 가 가능한 경우
{ // fastpath !
void *next_object = get_freepointer_safe(s, object);
// freelist 조정
if (unlikely(!this_cpu_cmpxchg_double(s->cpu_slab->freelist, s->cpu_slab->tid, object, tid,next_object, next_tid(tid))))
{
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH); // fastpath로 할당 상태 표시
}
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
C
복사
•
freelist 조정 후 검증을 완료한 후 free object 주소를 반환한다.
3. Kmalloc 디버깅
위에서 확인한 소스코드를 실제 테스트 코드를 이용해서 디버깅해보자. 구성환경은 다음과 같다
•
host : vmware - ubuntu 18.04
•
guest : x86_64 linux kernel 4.14.62 - qemu
테스트 코드는 char device 드라이버 공부할 때 사용했던 코드를 이용했다. 드라이버 open 시에 kmalloc이 호출되는 부분을 디버깅할 것이다.
참고로 kmalloc 부터 그 안에 들어있는 함수들은 내부분 inline으로 설정되어있기 때문에 컴파일 시 코드 내부에 함수로직이 삽입되어 디버깅에 불편하다. 그래서 처음에 분석하기 굉장히 힘들었는데 지인의 추천으로 한번 inline 부분을 지우고 커널을 다시 빌드하고 분석을 했다.
커널 빌드를 성공했고 다행히 디버깅이 훨씬 편해졌다. 물론 이렇게 하면 먼가 내부에서 틀어지는 경우가 생길꺼같아 두려웠지만 일단 진행하는걸로..
또한 user space에서 힙 분석시 편하게 분석할 수 있는 pwndbg 힙 관련 플러그인 처럼 커널에도 슬랩 오브젝트를 쉽게 분석할 수 있는 gdb 플러그인이 있다.
testcode *클릭*
chardev_open 함수에 bp를 걸고 시작해보자
*참고로 슬랩 캐시는 kmem_cache 구조체로 표현한다. 헷갈리는 안되는게 전역변수에
struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];
Plain Text
복사
슬랩 캐시들이 동일한 이름인 kmalloc_cache[] 구조체 배열이 선언되어 있다.
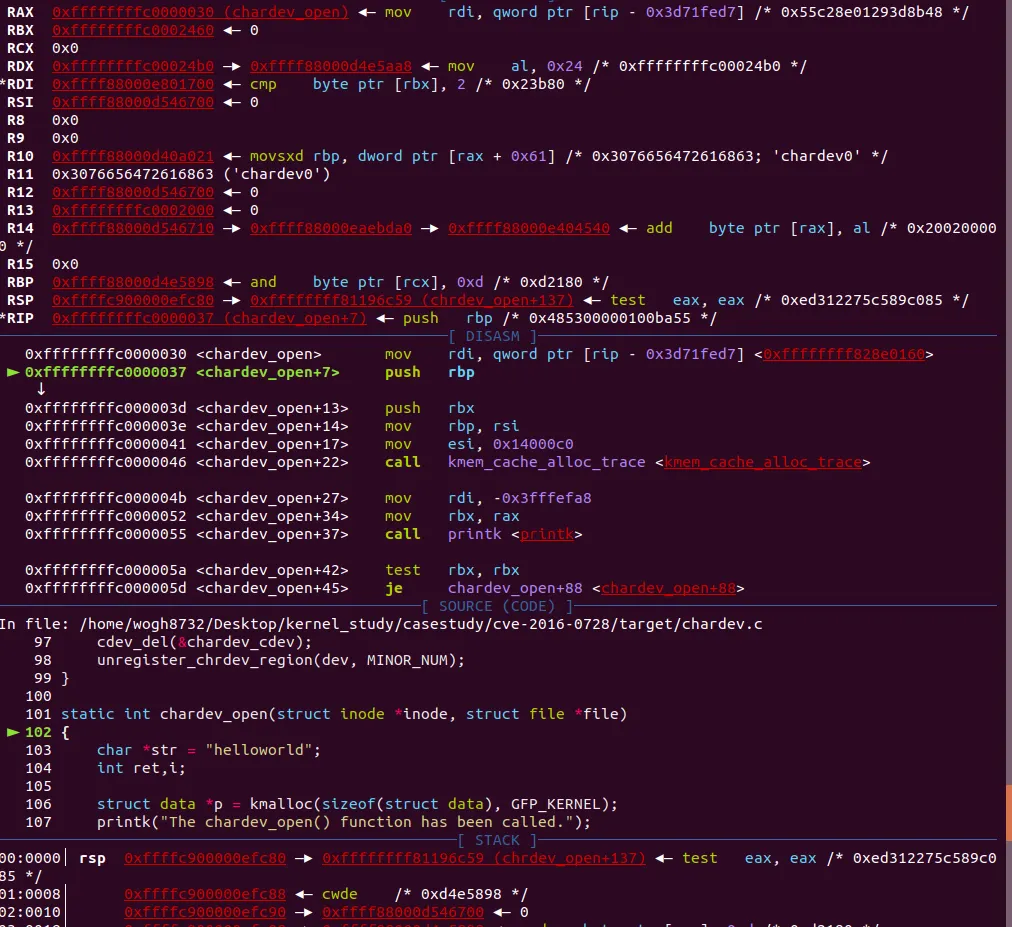
•
kmalloc 소스코드 분석시에 처음에는 요청 사이즈가 8k 를 넘는지 체크하고 넘으면 kmalloc_large 함수를 호출해서 Buddy 할당자로 요청시도를 한다고 봤었다. 근데 지금 위에 사진을 보면 해당 체크로직이 없다.
•
kmalloc 자체도 inline 함수여서 지우고 빌드했는데도 안뜬다. rdi에 어떤 값을 복사한다
•
rdi는 kmem_cache_alloc_trace() 함수의 첫번째 인자이므로 결국 rdi는 kmalloc_caches[index] 값이 되고 현재 디버깅 화면에는 안보이지만 아마 내부적으로 kmalloc_index()를 통해 인덱스를 얻고, kmalloc_caches 구조체 배열의 인덱스로 들어갔다고 추정할 수 있다
그렇다면 우리가 kmalloc_index() 함수에서 봤듯이, 0x100사이즈를 요청했으면 8을 반환해야 할 것이다.
/*
* Figure out which kmalloc slab an allocation of a certain size
* belongs to.
* 0 = zero alloc
* 1 = 65 .. 96 bytes
* 2 = 129 .. 192 bytes
* n = 2^(n-1)+1 .. 2^n
*/
static __always_inline int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8; // here
if (size <= 512) return 9;
if (size <= 1024) return 10;
...
}
C
복사
확인해보자.
pwndbg> p* kmalloc_caches[8]
$9 = {
cpu_slab = 0x23b80,
flags = 1073741824,
min_partial = 5,
size = 256,
object_size = 256,
offset = 0,
cpu_partial = 13,
oo = {
x = 16
},
max = {
x = 16
},
min = {
x = 16
},
allocflags = 0,
refcount = 10,
ctor = 0x0 <irq_stack_union>,
inuse = 256,
align = 8,
reserved = 0,
red_left_pad = 0,
name = 0xffffffff81fcac1d "kmalloc-256",
list = {
next = 0xffff88000e801868,
prev = 0xffff88000e801668
},
kobj = {
name = 0xffff88000d99d120 ":0000256",
entry = {
next = 0xffff88000e801880,
prev = 0xffff88000e801680
},
parent = 0xffff88000eba0af8,
kset = 0xffff88000eba0ae0,
ktype = 0xffffffff8225f760 <slab_ktype>,
sd = 0xffff88000d9aaf68,
kref = {
refcount = {
refs = {
counter = 1
}
}
},
state_initialized = 1,
state_in_sysfs = 1,
state_add_uevent_sent = 1,
state_remove_uevent_sent = 0,
uevent_suppress = 0
},
kobj_remove_work = {
data = {
counter = 68719476704
},
entry = {
next = 0xffff88000e8017c0,
prev = 0xffff88000e8017c0
},
func = 0xffffffff811864b0 <sysfs_slab_remove_workfn>
},
remote_node_defrag_ratio = 1000,
node = {0xffff88000e800e00, 0x0 <irq_stack_union>, 0x0 <irq_stack_union>, 0x0 <irq_stack_union>, 0x23b60, 0x40000000, 0x5 <irq_stack_union+5>, 0xc0000000c0, 0x1e00000000, 0x15 <irq_stack_union+21>, 0x15 <irq_stack_union+21>, 0x15 <irq_stack_union+21>, 0x600000000, 0x0 <irq_stack_union>, 0x8000000c0, 0x0 <irq_stack_union>, 0xffffffff81fcabda, 0xffff88000e801968, 0xffff88000e801768, 0xffff88000d99d140, 0xffff88000e801980, 0xffff88000e801780, 0xffff88000eba0af8, 0xffff88000eba0ae0, 0xffffffff8225f760 <slab_ktype>, 0xffff88000d9a9110, 0x700000001, 0xfffffffe0, 0xffff88000e8018c0, 0xffff88000e8018c0, 0xffffffff811864b0 <sysfs_slab_remove_workfn>, 0x3e8 <irq_stack_union+1000>, 0xffff88000e800e40, 0x0 <irq_stack_union>, 0x0 <irq_stack_union>, 0x0 <irq_stack_union>, 0x23b40, 0x40000000, 0x5 <irq_stack_union+5>, 0x8000000080, 0x1e00000000, 0x20 <irq_stack_union+32>, 0x20 <irq_stack_union+32>, 0x20 <irq_stack_union+32>, 0x800000000, 0x0 <irq_stack_union>, 0x800000080, 0x0 <irq_stack_union>, 0xffffffff81fcac11, 0xffff88000e801a68, 0xffff88000e801868, 0xffff88000d99d160, 0xffff88000e801a80, 0xffff88000e801880, 0xffff88000eba0af8, 0xffff88000eba0ae0, 0xffffffff8225f760 <slab_ktype>, 0xffff88000d96e2a8, 0x700000001, 0xfffffffe0, 0xffff88000e8019c0, 0xffff88000e8019c0, 0xffffffff811864b0 <sysfs_slab_remove_workfn>, 0x3e8 <irq_stack_union+1000>}
}
Bash
복사
오우 ! 정확하다.
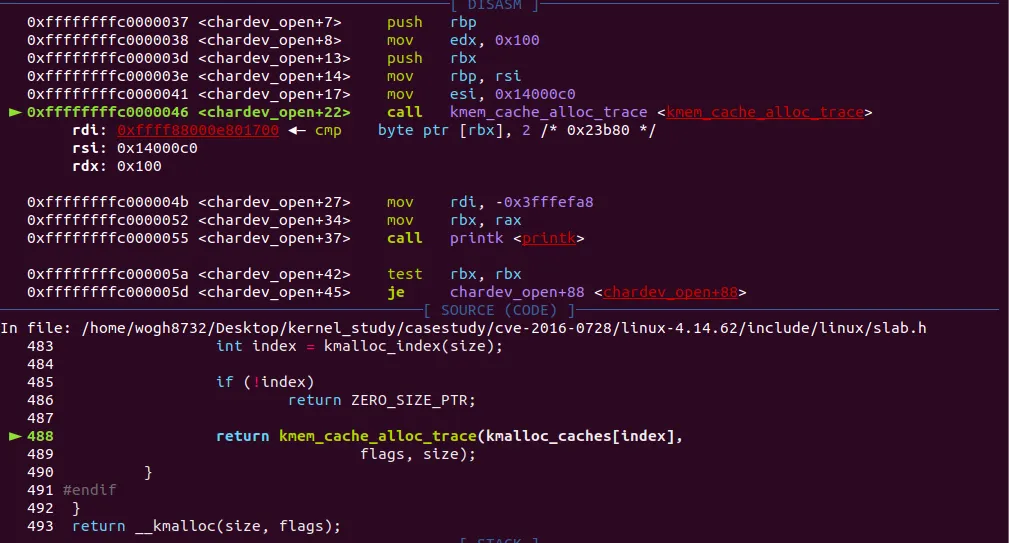
결국 kmem_cache_alloc_trace(kmalloc_cache[8], GFP_KERNEL, 0x100) 이렇게 호출된다.
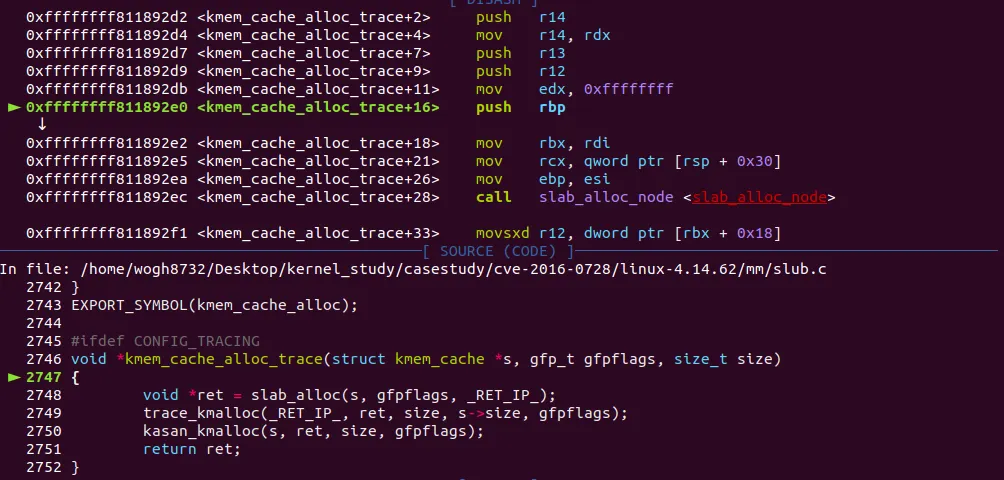
kmem_cache_alloc_trace 함수 내부로 들어왔다. 아까 분석했을 때 내부에서 가장 먼저 slab_alloc() 함수를 호출하는데, slab_alloc() 내부에선 별다른 동작없이 다시 slab_alloc_node() 함수를 호출했다. 저함수는 inline을 지우지 않아서 kmem_cache_alloc_trace() 함수 내부에 삽입이 되었다. slab_alloc_node() 내부로 들어와보자
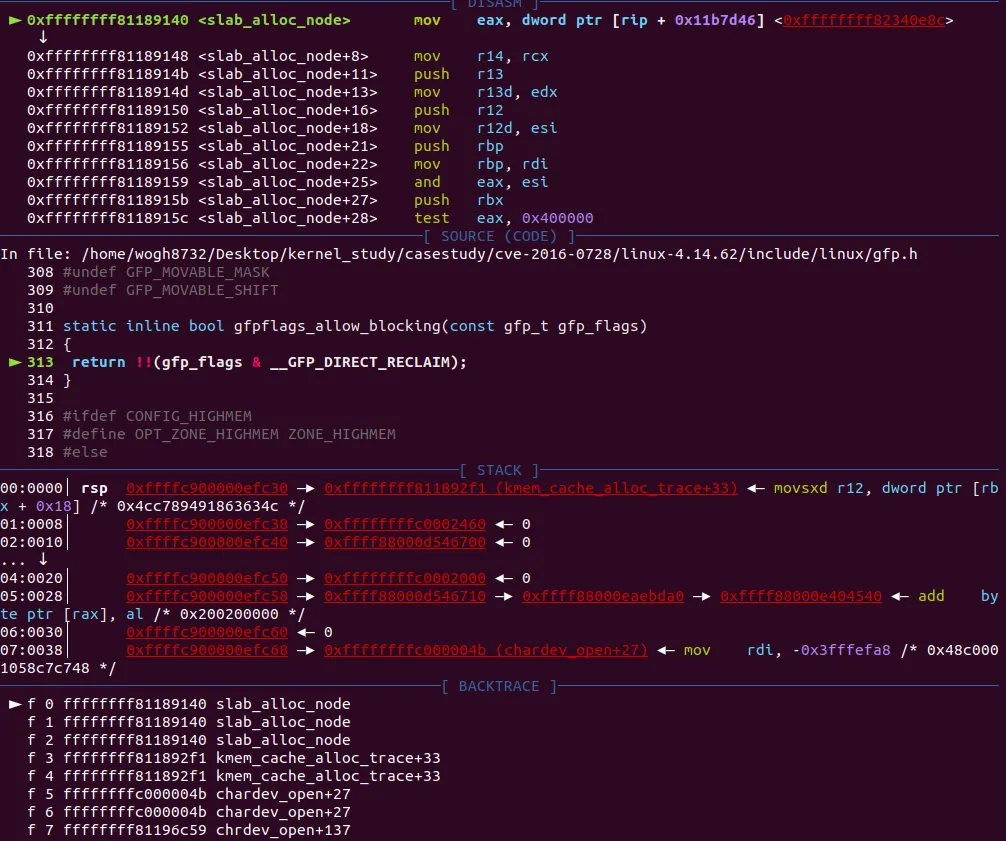
slab_alloc_node() 함수 내부로 들어오면 위와 같이 나온다. 처음엔 당황했는데 slab_alloc_node() 함수 초기에 다음과 같은 함수가 있다.
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
...
C
복사
slab_pre_alloc_hook() 함수가 있는데, 이 함수 내부에서 또 호출되는 함수들이 대부분 inline이다. 그 중 초기에 호출되는게 바로 저 디버깅 화면에서 나오는 gfpflags_allow_blocking() 함수이다. 따라서 ni 몇번 해주면 다시 slab_alloc_node() 코드가 나온다.
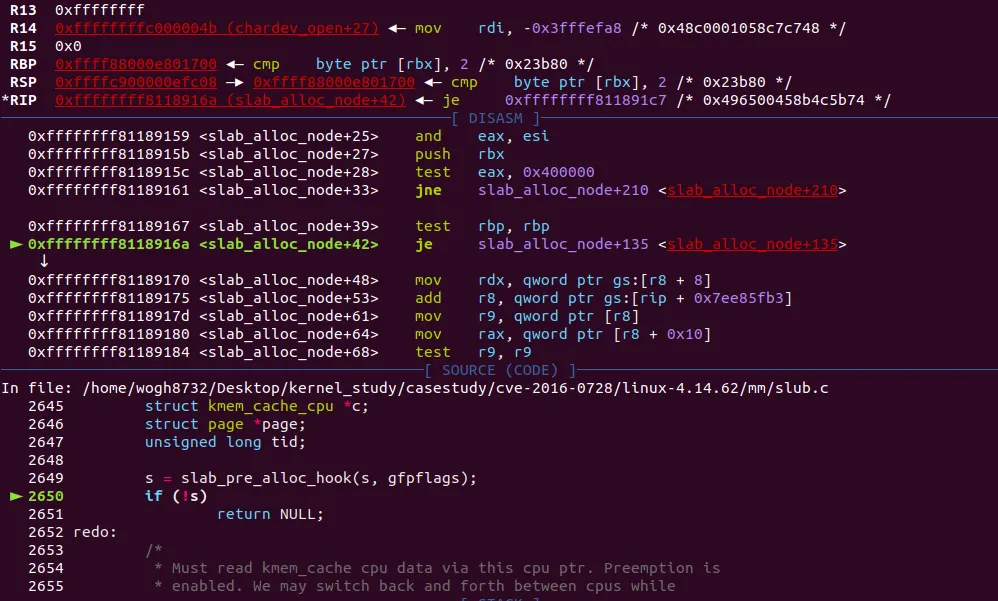
제거안한 inline 함수가 너무 많아서 아직도 분석하기 힘들다. 현재 slab_alloc_node 함수에서
" slab_alloc_node + 39 : test rbp, rbp "라인이 실행됬다. 저기가 바로 slab_pre_alloc_hook() 함수의 반환값을 비교하는 부분이다. rbp가 0이라면 해당 함수는 종료된다. 현재 rbp가 0이 아니여서 계속 수행된다.
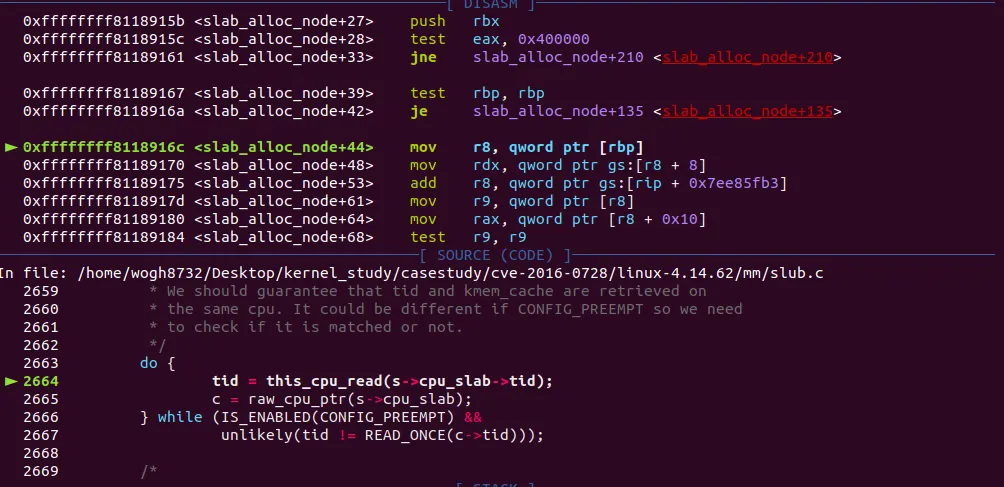
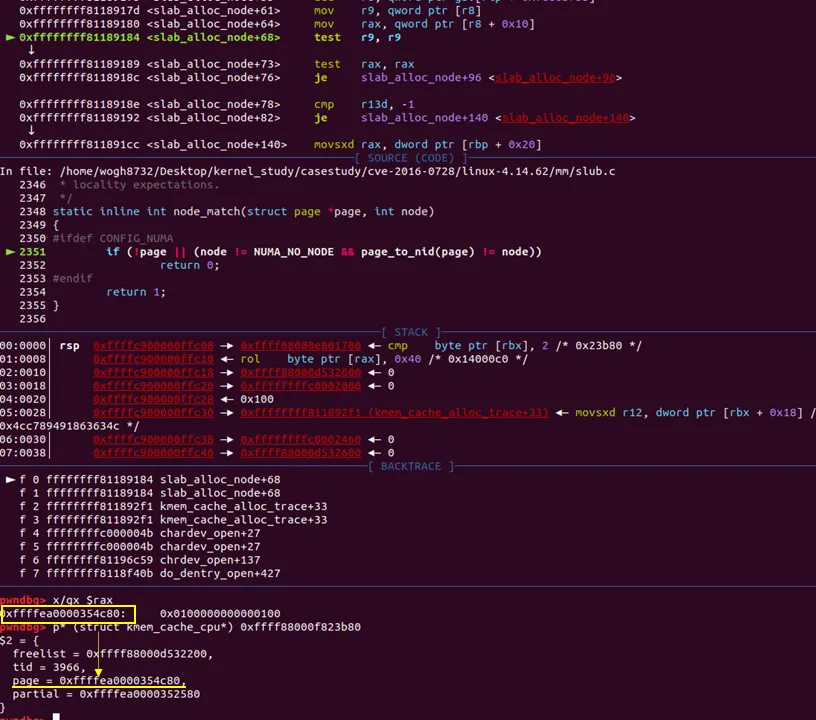
' tid '와 ' c ' 를 구하는 로직으로 왔다. struct kmem_cache_cpu *c 가 구해지면 다음과 같이 구조체 형태를 확인 할 수 있다

c의 포인터 주소가 바로 0xffff88000f823b80이다. freelist에 오브젝트가 존재하고, 커널 쓰레드로 추정되는 tid값이 보인다. 그리고 c→page와 c→partial 도 확인할 수 있다.
힘들게 공부한 슬랩 오브젝트 내용이 실제 확인되는 감격스러운 상황이다 ㅜㅜ

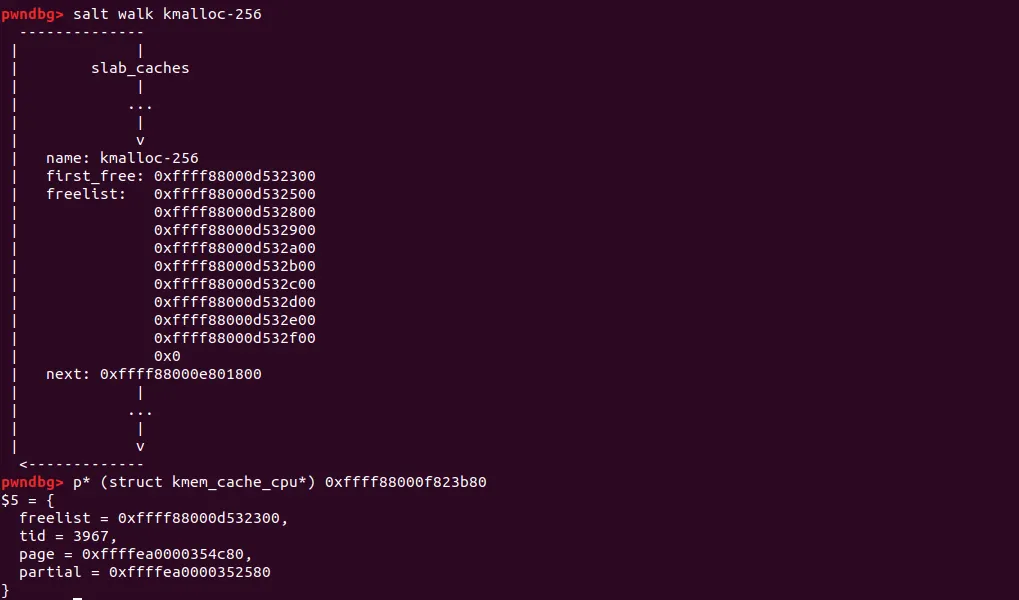
그다음 [r8](c→freelist) 에 들어있는 값을 반환한다. 이제 salt 플러그으로 슬랩 캐시를 확인해보자. 현재 우리가 요청한 사이즈는 0x100이므로 kmalloc-256 슬랩캐시가 관리해준다.
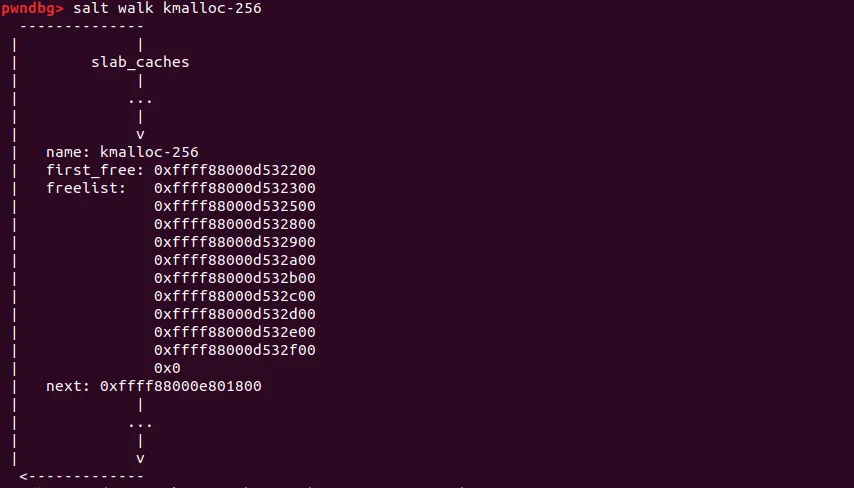
현재 kmalloc-256 슬랩캐시를 보면 c→freelist에 10개의 free되어있는 오브젝트를 확인 할 수 있다. 이론대라로면 first_free에 있는 0xffff88000d532200 오브젝트를 object(r9 레지스터) 변수에 담길 것이다.
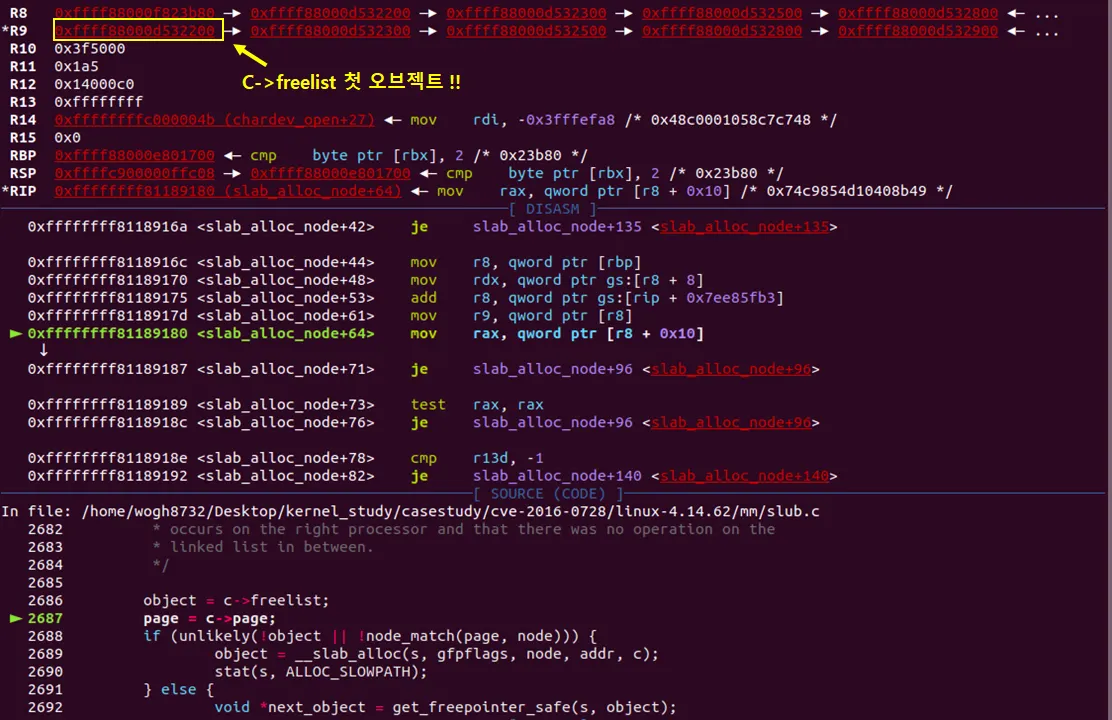
salt로 확인한 주소가 r9에 담겼다 !!. 이제 r8+0x10에 들어있는 값을 rax에 복사한다. 이는 아까 확인했던 kmem_cache_cpu 구조체의 c→page 값일것이다.
정확하다. 코드를 보면 또 내부 함수중에 inline 이 있어서 저렇게 나온다. 지금까지 kmalloc 부터 어디까지 진행됬는지 요약해보자.
kmalloc() → kmem_cache_alloc_trace() → slab_alloc() → slab_alloc_node() 에서
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
...
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node)))
{ // slowpath !
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
else
{ // fastpath !
void *next_object = get_freepointer_safe(s, object); // 여기 진행중 !!
if (unlikely(!this_cpu_cmpxchg_double(s->cpu_slab->freelist, s->cpu_slab->tid, object, tid,next_object, next_tid(tid))))
{
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH); // fastpath로 할당 상태 표시
}
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}
C
복사
현재 get_freepointer_safe() 함수가 진행중인 상황이다. 이 함수도 inline이여서 따로 호출없이 내부에서 바로 진행된다. get_freepointer_safe() 에서 내부에 또 get_freepointer()가 inline으로 호출됨
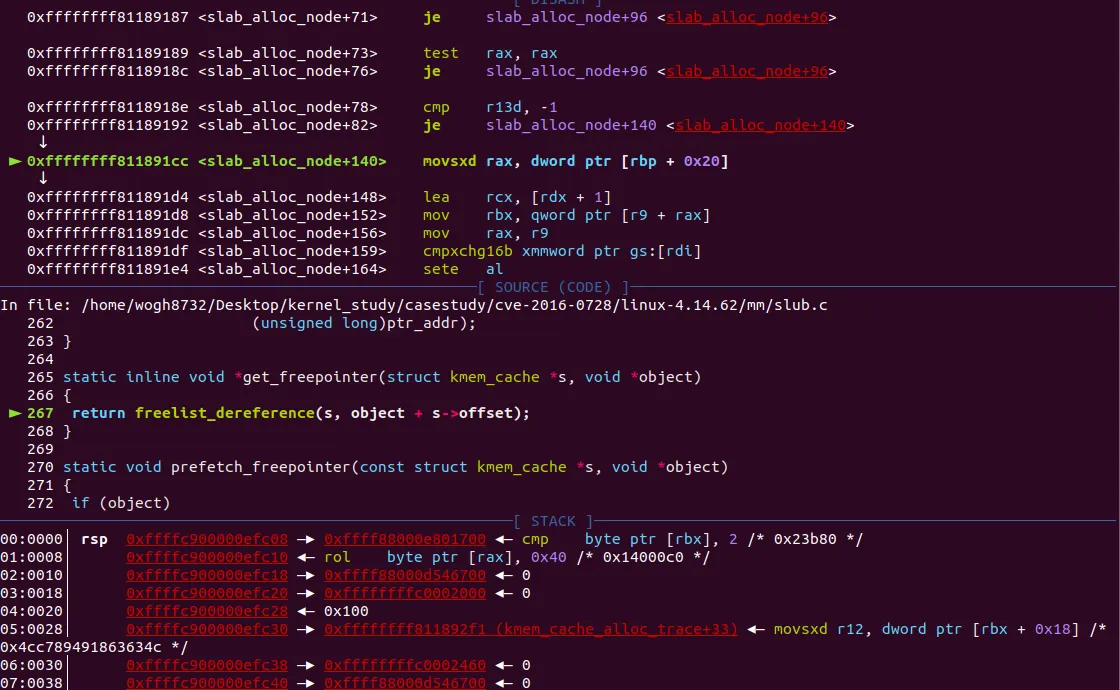
get_freepointer 함수가 실행되고 있다는 뜻은 바로 Fastpath 방식으로 오브젝트의 할당이 진행된다는 것이다.
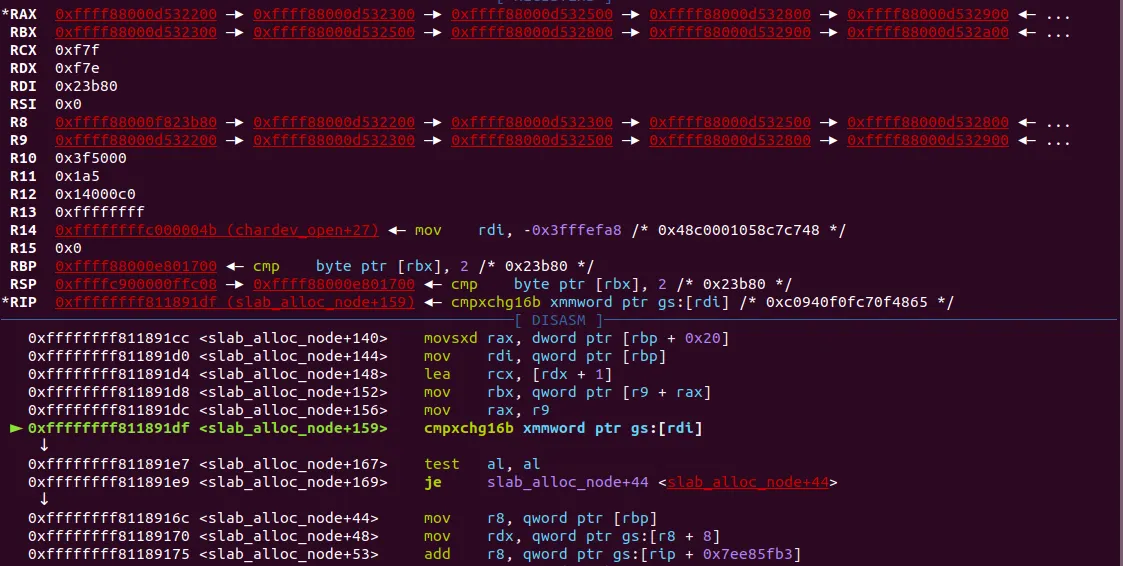
쭉 진행되다가 cmpxchgm16b 명령이 나온다. 저 부분은 실제 소스코드의 다음 부분에 해당한다
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
...
if (unlikely(!object || !node_match(page, node)))
{ // slowpath !
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
else
{ // fastpath !
void *next_object = get_freepointer_safe(s, object);
...
if (unlikely(!this_cpu_cmpxchg_double(s->cpu_slab->freelist, s->cpu_slab->tid, object, tid,next_object, next_tid(tid))))
{ this_cpu_cmpxchg_double => 요 함수 !!
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH); // fastpath로 할당 상태 표시
}
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}
C
복사
this_cpu_cmpxchg_double() 함수인데 여기 안에서 freelist의 조정이 일어난다. 저 함수를 c 코드로 다음과 같이 나타낼 수 있다.
this_cpu_cmpxchg_double() =>
if ((__this_cpu_ptr(s->cpu_slab->freelist) == object) && (__this_cpu_ptr(s->cpu_slab->tid) == tid))
{
__this_cpu_ptr(s->cpu_slab->freelist) = next_object; // freelist 조정 !
__this_cpu_ptr(s->cpu_slab->tid) = next_tid(tid);
return true;
}
else
{
return false;
}
C
복사
즉 저 함수에서 할당하려는 오브젝트를 c→freelist에서 제거하게 된다.
cmpxchgm16b ~ 명령어가 수행되면 위 사진처럼 할당하려는 0xffff88000d532200 오브젝트가 freelist에서 제거된 것을 볼 수 있다.
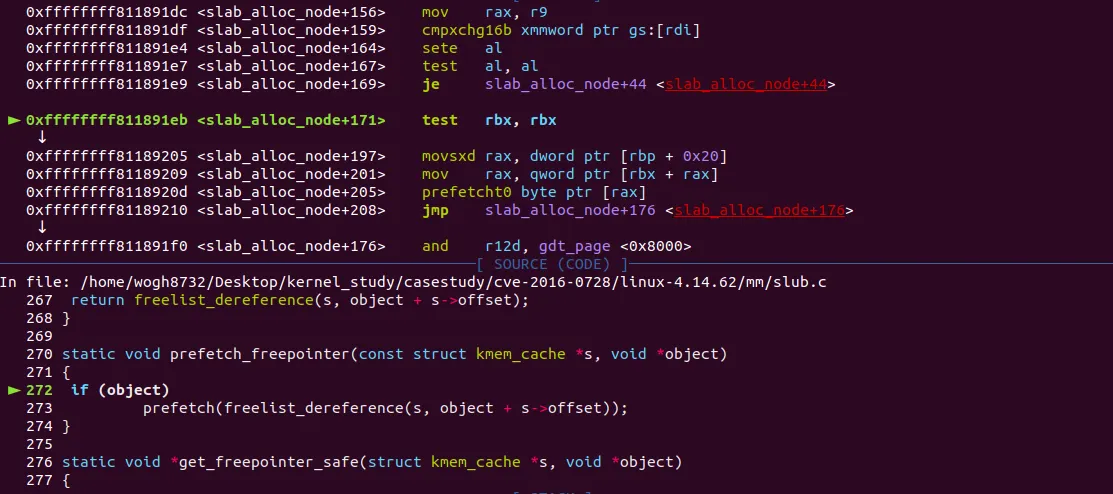
unlikely() 부분은 일반적인 상황에선 false가 나오기 때문에 조건문 안으로 안들어간다. freelist를 조정하고 slab_alloc_node() 의 마지막 부분인 prefetch_freepointer() 가 호출된다. 이 역시 인라인으로 삽입되어 있다.
해당 함수의 인자는 kmalloc-256 슬랩 캐시 구조체 포인터와 할당해준 다음 슬랩 오브젝트 주소를 받는다. 즉 다음 object에 대한 캐시라인을 prefetch한다
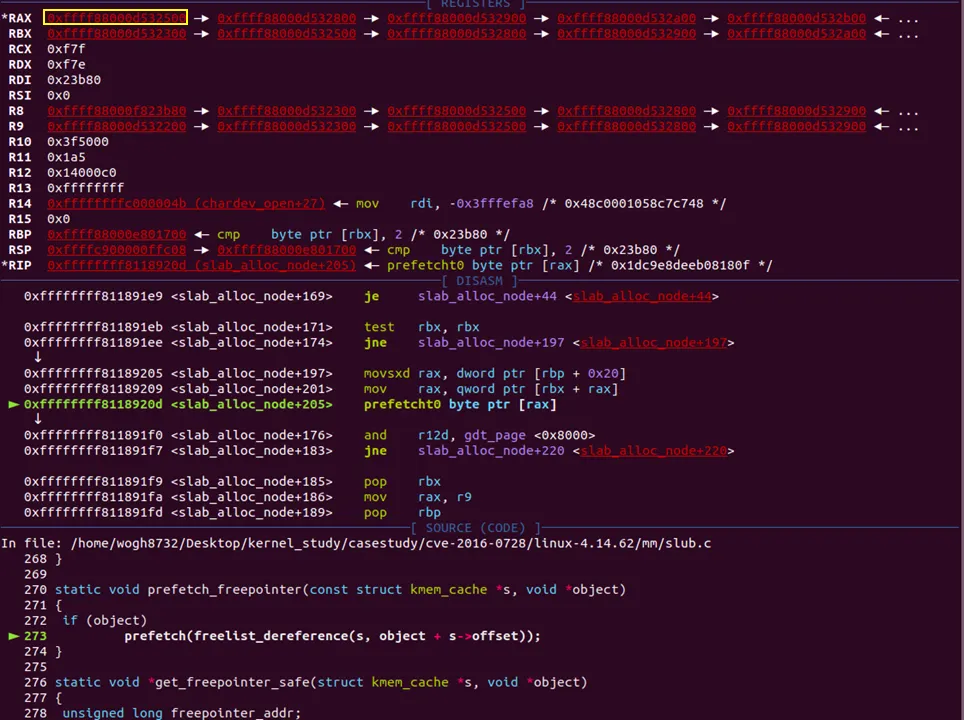
실제 prefetcht0 명령으로 [rax] 값을 prefetch한다. rax는 현재 freelist의 2번째 오브젝트이다. 자세힌 모르겠지만 아마 다음, 다다음 처리될 오브젝트들을 L1 캐시에 올리는 작업인 거 같다.

그다음 진행해보면 unlikely() 부분이 또 나온다. kmalloc()의 두번째 인자인 플래그 값에서 __GFP_ZERO 플래그가 on 되어있는지 체크한다. 일반적으로 세팅 안되어있다. 만약 세팅되어 있고 할당하려는 object가 null이 아니면 해당 오브젝트를 0으로 초기화한다.
이제 마지막으로 r9에 있는 값을 rax로 복사한다. 해당 값은 바로 할당해주려는 슬랩 오브젝트이다. 끝이다. 이제 드라이버 코드에서 kmalloc으로 할당받은 메모리에 값을 쓰는 부분을 확인해보자.
printk로 출력시켜놨으니 어떤 주소에 값을 쓰는지 확인해보고, 여태 살펴본 0xffff88000d532200 주소가 맞으면 잘 분석한거다 !! 우선 테스트 코드를 다시 보면
...
struct data {
unsigned char buffer[BUFFER_SIZE];
};
...
static int chardev_open(struct inode *inode, struct file *file)
{
char *str = "helloworld";
int ret,i;
struct data *p = kmalloc(sizeof(struct data), GFP_KERNEL);
printk("The chardev_open() function has been called.");
if (p == NULL) {
printk(KERN_ERR "kmalloc - Null");
return -ENOMEM;
}
ret = strlcpy(p->buffer, str, sizeof(p->buffer));
if(ret > strlen(str)){
printk(KERN_ERR "strlcpy - too long (%d)",ret);
}
file->private_data = p;
return 0;
}
...
static ssize_t chardev_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct data *p = filp->private_data;
printk("The chardev_write() function has been called.");
printk("Before calling the copy_from_user() function : %p, %s",p->buffer,p->buffer);
if (copy_from_user(p->buffer, buf, count) != 0) {
return -EFAULT;
}
printk("After calling the copy_from_user() function : %p, %s",p->buffer,p->buffer);
return count;
}
C
복사
이렇게 작성해놨다. (어짜피 만들어 놓은 data 구조체에 멤벼변수인 buffer 하나밖에 없어서 p→buffer 주소가 p 시작 주소이다)

홀리~~~~~ 0xffff88000d532200 이다. 보람차구만
4. 정리
사실 원래 커널 원데이 분석하려고 했는데 슬랩 할당자라는 개념을 알게되었다. 커널 공부하다가 간간히 봤는데 이참에 확실히 한번 예전 힙 분석한 것처럼 이해해보자! 라는 마인드로 공부를 시작하였다. 헌데 난이도가 후덜덜했다. 사실 지금까지 한것도 깊게 한건 아니다. 빙산의 일각인듯..
슬랩 할당자 공부하려고 보니 NUMA 구조를 알아야하고, 이걸 이해할라면 또 메모리 존이란 개념을 알아야하고, 또 페이지 구조체, 페이징 기법, 버디시스템 .. 후.. 타고타고 계속 가다보니 끝이 없었다.
근 2주동안 커널공부만 한거같은데 그래도 포기하지 않고 계획한 목표치까지 분석을 다했다. 이제 커널 취약점 원데이 분석 바로 들어가고 올해안에 커널 퍼징 돌리는거 목표로 조지자.

